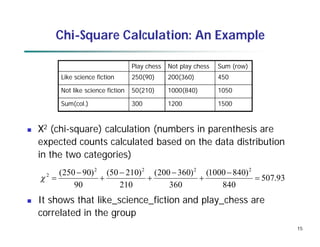
This document provides an overview of data preprocessing techniques. It discusses data quality issues like missing values, noise, and inconsistencies that require cleaning. Major tasks in preprocessing include data cleaning, integration, reduction, and transformation. Data cleaning techniques are described for handling incomplete, noisy, and inconsistent data. Methods for data integration, reduction through dimensionality reduction and sampling, and transformation through normalization and discretization are also summarized.




























![33
Normalization
Min-max normalization: to [new_minA, new_maxA]
Ex. Let income range $12,000 to $98,000 normalized to [0.0,
1.0]. Then $73,000 is mapped to
Z-score normalization (μ: mean, σ: standard deviation):
Ex. Let μ = 54,000, σ = 16,000. Then
Normalization by decimal scaling
716
.
0
0
)
0
0
.
1
(
000
,
12
000
,
98
000
,
12
600
,
73
A
A
A
A
A
A
min
new
min
new
max
new
min
max
min
v
v _
)
_
_
(
'
A
A
v
v
'
j
v
v
10
' Where j is the smallest integer such that Max(|ν’|) < 1
225
.
1
000
,
16
000
,
54
600
,
73
](https://image.slidesharecdn.com/03preprocessing01-231216002955-16aba1a1/85/03Preprocessing01-pdf-33-320.jpg)






















































