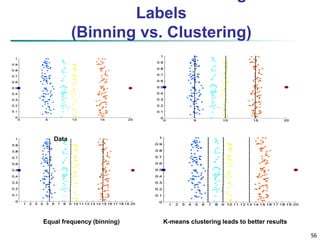
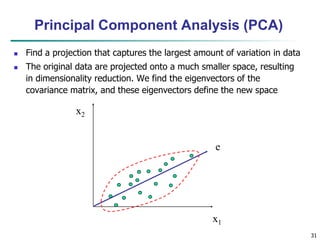
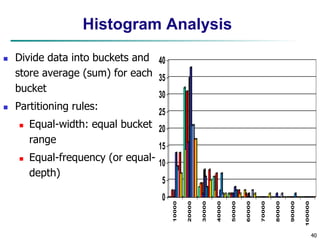
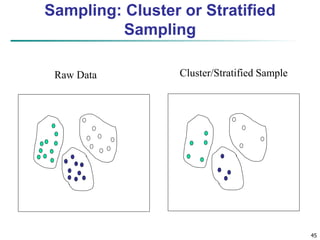
This document provides an overview of data preprocessing techniques discussed in Chapter 3 of the textbook "Data Mining: Concepts and Techniques". It covers topics such as data quality, data cleaning, data integration, data reduction, and data transformation. Data reduction techniques like dimensionality reduction aim to obtain a reduced representation of data that uses less space but produces similar analytical results. Dimensionality reduction methods include wavelet transforms, principal component analysis, and feature selection. Wavelet transforms decompose a signal into different frequency subbands and allow clusters to become more distinguishable at different resolution levels.
















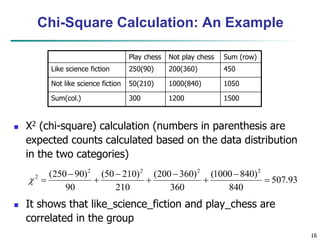

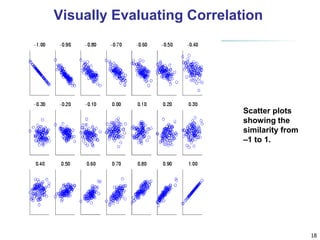






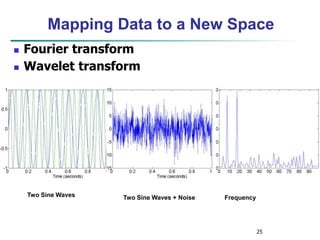


![28
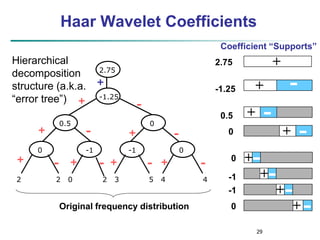
Wavelet Decomposition
Wavelets: A math tool for space-efficient hierarchical
decomposition of functions
S = [2, 2, 0, 2, 3, 5, 4, 4] can be transformed to S^ =
[23/4, -11/4, 1/2, 0, 0, -1, -1, 0]
Compression: many small detail coefficients can be
replaced by 0’s, and only the significant coefficients are
retained](https://image.slidesharecdn.com/03preprocessing-230529172058-03d5e6f3/85/03Preprocessing-ppt-28-320.jpg)















![51
Normalization
Min-max normalization: to [new_minA, new_maxA]
Ex. Let income range $12,000 to $98,000 normalized to [0.0,
1.0]. Then $73,000 is mapped to
Z-score normalization (μ: mean, σ: standard deviation):
Ex. Let μ = 54,000, σ = 16,000. Then
Normalization by decimal scaling
716
.
0
0
)
0
0
.
1
(
000
,
12
000
,
98
000
,
12
600
,
73
A
A
A
A
A
A
min
new
min
new
max
new
min
max
min
v
v _
)
_
_
(
'
A
A
v
v
'
j
v
v
10
' Where j is the smallest integer such that Max(|ν’|) < 1
225
.
1
000
,
16
000
,
54
600
,
73
](https://image.slidesharecdn.com/03preprocessing-230529172058-03d5e6f3/85/03Preprocessing-ppt-51-320.jpg)