Downloaded 16 times







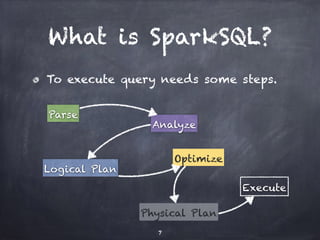
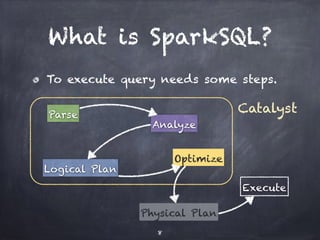
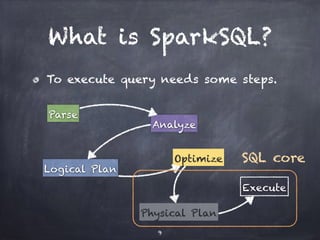





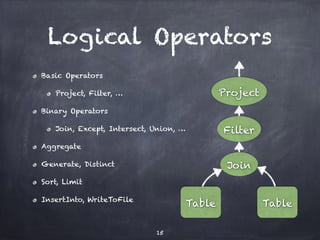











![SQL core in depth
o.a.s.sql.SchemaRDD
Extends RDD[Row].
Has logical plan tree.
Provides LINQ-like interfaces to construct
logical plan.
select, where, join, orderBy, …
Executes the plan.
28](https://image.slidesharecdn.com/sparksqlcatalyst-140912023144-phpapp02/85/Introduction-to-Spark-SQL-and-Catalyst-Spark-SQL-Calalyst-28-320.jpg)











SparkSQL is a Spark component that allows SQL queries to be executed on Spark. It uses Catalyst, which provides an execution planning framework for relational operations like SQL parsing, logical optimization, and physical planning. Catalyst defines logical and physical operators, expressions, data types and provides rule-based optimizations to transform query plans. The SQL core in SparkSQL builds SchemaRDDs to represent queries and allows reading/writing to Parquet and JSON formats.































![[ScalaMatsuri] グリー初のscalaプロダクト!チャットサービス公開までの苦労と工夫](https://cdn.slidesharecdn.com/ss_thumbnails/scalamaturiscala-140914203407-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





































































