Downloaded 17 times


![THE TEAM
Jim Cai
MSCS
Technical Lead LinkedIn
Engineering
William Song
MSCS
Self driving Car
Google[x]; Facebook
Engineering
Billy Jun
MSCS
Robotics at MDA
Engineering
Sam Yu
MSx GSB
SAIF Partners, GE
Strategy + Bizdev
Jordan Segall
MS in MS&E, BSCS
PM RelateIQ; FDE Palantir
Product + Bizdev](https://image.slidesharecdn.com/ezml-150303192040-conversion-gate01/85/Ezml-Stanford-2015-3-320.jpg)

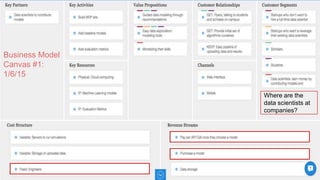

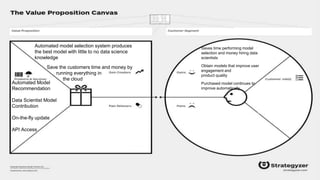






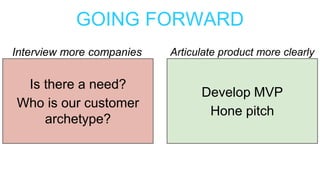

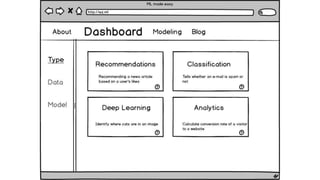










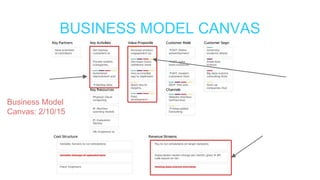


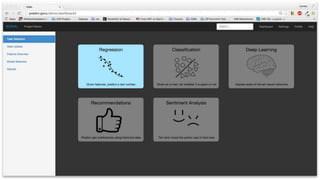
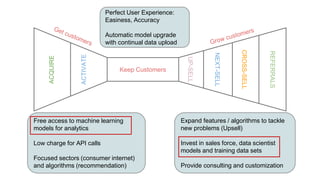
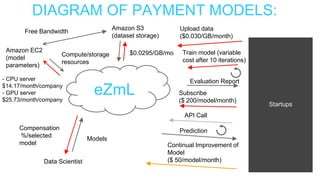



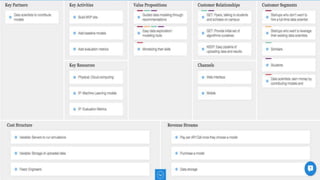
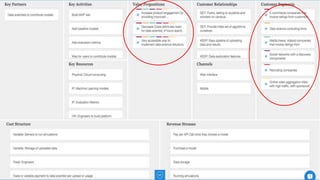
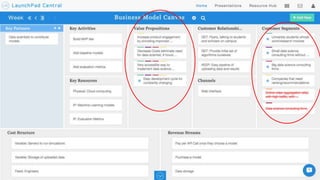
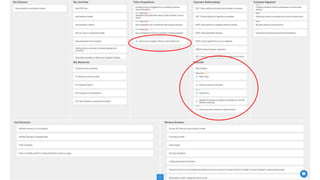
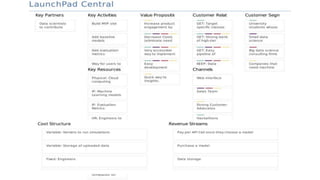





This document summarizes the learnings and evolution of EZML, a proposed machine learning tool. It began by targeting data scientists, but interviews revealed that feature extraction was more important than automated model selection. The target then became companies lacking data science capabilities. Further interviews identified the ideal customer as a startup CTO with a recommendation or engagement problem. An MVP was developed with tiered pricing and consulting. Ongoing challenges around data privacy and costs were noted. The document concludes by questioning the business viability and next steps.























































































