AggNet: Deep Learning from Crowds

The lack of publicly available ground-truth data has been identified as the major challenge for transferring recent developments in deep learning to the biomedical imaging domain. Though crowdsourcing has enabled annotation of large scale databases for real world images, its application for biomedical purposes requires a deeper understanding and hence, more precise definition of the actual annotation task. The fact that expert tasks are being outsourced to non-expert users may lead to noisy annotations introducing disagreement between users. Despite being a valuable resource for learning annotation models from crowdsourcing, conventional machine-learning methods may have difficulties dealing with noisy annotations during training. In this manuscript, we present a new concept for learning from crowds that handle data aggregation directly as part of the learning process of the convolutional neural network (CNN) via additional crowdsourcing layer (AggNet). Besides, we present an experimental study on learning from crowds designed to answer the following questions. 1) Can deep CNN be trained with data collected from crowdsourcing? 2) How to adapt the CNN to train on multiple types of annotation datasets (ground truth and crowd-based)? 3) How does the choice of annotation and aggregation affect the accuracy? Our experimental setup involved Annot8, a self-implemented web-platform based on Crowdflower API realizing image annotation tasks for a publicly available biomedical image database. Our results give valuable insights into the functionality of deep CNN learning from crowd annotations and prove the necessity of data aggregation integration. http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=7405343

Recommended
Recommended
More Related Content
Similar to AggNet: Deep Learning from Crowds
Similar to AggNet: Deep Learning from Crowds (20)
More from Shadi Nabil Albarqouni
Recently uploaded
Recently uploaded (20)
AggNet: Deep Learning from Crowds
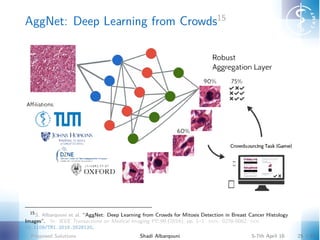
- 1. AggNet: Deep Learning from Crowds15 15 S. Albarqouni et al. “AggNet: Deep Learning from Crowds for Mitosis Detection in Breast Cancer Histology Images”. In: IEEE Transactions on Medical Imaging PP.99 (2016), pp. 1–1. issn: 0278-0062. doi: 10.1109/TMI.2016.2528120. Proposed Solutions Shadi Albarqouni 5-7th April 16 25 / 42
- 2. AggNet: Deep Learning from Crowds16 Trying to answer I Can we handle "noisy" votes? I Can we learn/augment a deep model from the crowd votes? I How di erent aggregation methods can influence the learning/augmentation of deep model? Requirements: I Aggregate the ground-truth from crowdvotes matrix. I Reduce the e ect of "noisy" votes. (Compute the sensitivity and specificity of each annotator). I Jointly learn the classifier by propagating back the derivative of the loss function. 16 Albarqouni et al., “AggNet: Deep Learning from Crowds for Mitosis Detection in Breast Cancer Histology Images”. Proposed Solutions Shadi Albarqouni 5-7th April 16 26 / 42
- 3. Methodology Figure: AggNet Framework Proposed Solutions Shadi Albarqouni 5-7th April 16 27 / 42
- 4. Notation I X is the input RGB images, X = {x1, x2, ..., xN} œ RH◊W ◊D◊N. I N is the number of input instances/samples. I H is the height of an image xiœN. I W is the width of an image xiœN. I D is the channels/depth of an image/volume xiœN. I Y is the crowdsourced labels, Y = {y1, y2, ...., yN} œ Rc◊P◊N I P is the number of participants (Crowds). Objective Build a model f that for a given input x and crowdsourced labels y, can predict the output ˆp: ˆp = f(x, y; ◊), where ˆp is the predicted label and ◊ is the model parameter. Proposed Solutions Shadi Albarqouni 5-7th April 16 28 / 42
- 5. Network Architecture I Figure: CNN architecture: The same CNN architecture is used for di erent scales to build a multi-scale CNN model (Initial model) Proposed Solutions Shadi Albarqouni 5-7th April 16 29 / 42
- 6. Network Architecture II Figure: CNN architecture: pi , µi , yj i represents the classifier output, the aggregated label, and the crowdvotes respectively. Proposed Solutions Shadi Albarqouni 5-7th April 16 30 / 42
- 7. Objective I Data Pre-Processing. I Handling Imbalanced data: Data Re-sampling. I Data Augmentation: 4 Rotation and 2 Flipping. I Network Architecture: (Conv+ReLU+Pooling)3 + FC2. The Loss function Given a pre-trained model, minimize the Negative Log-likelihood: E{≠ ln Pr[D, g|Â]} = ≠ Nÿ i=1 µi ln pi ai + (1 ≠ µi ) ln(1 ≠ pi )bi , where µi is the aggregated label, pi is the predicted label, and both ai , bi are the conditional probabilities p(y|g = 1, –), p(y|g = 0, —) respectively. Proposed Solutions Shadi Albarqouni 5-7th April 16 31 / 42
- 8. Algorithm input : Data points X = {x1, x2, ..., xN }, crowdvotes matrix Y = {y1, y2, ..., yN }, and model parameter ◊(0) . output: Aggregated labels µ = {µ1, µ2, ..., µN }, sensitivity and specificity of each user –j and —j respectively, and the updated model parameter ◊(k) Initialize µi with majority voting, compute –j and —j accordingly. while convergence do % E-Step, Forward Message ¸(µ, p) = ≠ qN i=1 µi ln pi ai + (1 ≠ µi ) ln(1 ≠ pi )bi , ai = rP j=1 [–j ]y j i [1 ≠ –j ]1≠y j i , bi = rP j=1 [—j ]1≠y j i [1 ≠ —j ]y j i , pi = ‡(zi ) = ezic qC c=1 ezic , zi = wT xi, µi = ai pi ai pi +bi (1≠pi ) . % M-Step, Backward Message –j = qN i=1 µi y j i qN i=1 µi , —j = qN i=1 (1≠µi )(1≠y j i ) qN i=1 (1≠µi ) , ˆ¸ ˆw = ˆ¸ ˆpi ˆpi ˆzi ˆzi ˆw . end Proposed Solutions Shadi Albarqouni 5-7th April 16 32 / 42
- 9. Example Proposed Solutions Shadi Albarqouni 5-7th April 16 33 / 42
- 10. Example Proposed Solutions Shadi Albarqouni 5-7th April 16 34 / 42
- 11. Experimental Setup I I Dataset: publicly available MICCAI-AMIDA13 challenge dataset17, which contains annotated histology images of a total 23 patients (around 600 images). Each is an RGB image of 2k ◊ 2k with a spatial resolution of 0.25µm/pixel. Samples are collected at 33 ◊ 33 patches resulting in more than 100 million of instances. I Training (40%), Validation (10%), Testing(50%). I Training parameters: Learning rate = 1 ◊ 10≠3, Momentum = 0.9, Batch size = 200 samples. I Positive candidates of pi > 0.9 are crowdsourced. I Tuning parameters: Learning rate = 1 ◊ 10≠5, Momentum = 0.9, Batch size = 600 samples. Proposed Solutions Shadi Albarqouni 5-7th April 16 35 / 42
- 12. Experimental Setup II Figure: Instruction and Guidelines Figure: HIT task 17 http://amida13.isi.uu.nl/ Proposed Solutions Shadi Albarqouni 5-7th April 16 36 / 42
- 13. Results I Initial model: Multi-scale results (3rd rank in AMIDA13) Proposed Solutions Shadi Albarqouni 5-7th April 16 37 / 42
- 14. Results II Di erent aggregation methods have been evaluated showing the robustness of the proposed AggNet method. The augmented models (refinement) have been evaluated as well. Figure: ROC of Aggregated Labels Figure: ROC of Augmented Models Proposed Solutions Shadi Albarqouni 5-7th April 16 38 / 42
- 15. Results III Figure: Augmented Models: Visual Results Proposed Solutions Shadi Albarqouni 5-7th April 16 39 / 42
- 16. Conclusion I The proposed AggNet is quite robust to "noisy" labels and positively influences the performance of the CNN model. I The augmented model has a gain of 7.6% in AUC. I The applied quality control need to be carefully planned and well designed. I Learning a model from crowdsourcing labels alone is quite challenging due to small amount of data (possibly noisy). I Propose Gamification18 to keep the users motivated to perform the task until the very end. 18 PlaySourcing paper Proposed Solutions Shadi Albarqouni 5-7th April 16 40 / 42