Downloaded 984 times



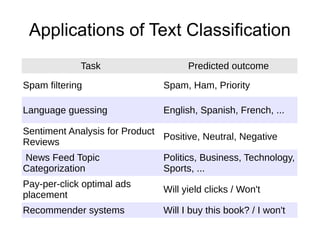

![Bags of Words
● Tokenize document: list of uni-grams
['the', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog']
● Binary occurrences / counts:
{'the': True, 'quick': True...}
● Frequencies:
{'the': 0.22, 'quick': 0.11, 'brown': 0.11, 'fox': 0.11…}
● TF-IDF
{'the': 0.001, 'quick': 0.05, 'brown': 0.06, 'fox': 0.24…}](https://image.slidesharecdn.com/textclassificationscikit-learnpycon2011ogrisel-110311132018-phpapp01/85/Statistical-Machine-Learning-for-Text-Classification-with-scikit-learn-and-NLTK-6-320.jpg)



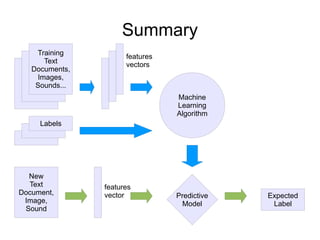
![Features Extraction in scikit-learn
from scikits.learn.features.text import WordNGramAnalyzer
text = (u"J'ai mangxe9 du kangourou ce midi,"
u" c'xe9tait pas trxeas bon.")
WordNGramAnalyzer(min_n=1, max_n=2).analyze(text)
[u'ai', u'mange', u'du', u'kangourou', u'ce', u'midi', u'etait',
u'pas', u'tres', u'bon', u'ai mange', u'mange du', u'du
kangourou', u'kangourou ce', u'ce midi', u'midi etait', u'etait
pas', u'pas tres', u'tres bon']](https://image.slidesharecdn.com/textclassificationscikit-learnpycon2011ogrisel-110311132018-phpapp01/85/Statistical-Machine-Learning-for-Text-Classification-with-scikit-learn-and-NLTK-11-320.jpg)
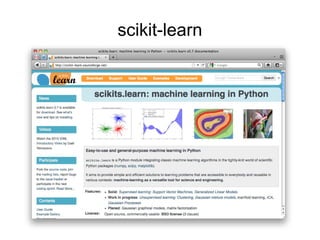
![Features Extraction in scikit-learn
from scikits.learn.features.text import CharNGramAnalyzer
analyzer = CharNGramAnalyzer(min_n=3, max_n=6)
char_ngrams = analyzer.analyze(text)
print char_ngrams[:5] + char_ngrams[-5:]
[u"j'a", u"'ai", u'ai ', u'i m', u' ma', u's tres', u' tres ', u'tres b',
u'res bo', u'es bon']](https://image.slidesharecdn.com/textclassificationscikit-learnpycon2011ogrisel-110311132018-phpapp01/85/Statistical-Machine-Learning-for-Text-Classification-with-scikit-learn-and-NLTK-12-320.jpg)


![Using a NLTK corpus
>>> from nltk.corpus import movie_reviews as reviews
>>> pos_ids = reviews.fileids('pos')
>>> neg_ids = reviews.fileids('neg')
>>> len(pos_ids), len(neg_ids)
1000, 1000
>>> reviews.words(pos_ids[0])
['films', 'adapted', 'from', 'comic', 'books', 'have', ...]](https://image.slidesharecdn.com/textclassificationscikit-learnpycon2011ogrisel-110311132018-phpapp01/85/Statistical-Machine-Learning-for-Text-Classification-with-scikit-learn-and-NLTK-17-320.jpg)



![The NLTK Naïve Bayes Classifier
from nltk.classify import NaiveBayesClassifier
neg_examples = [(features(reviews.words(i)), 'neg') for i in neg_ids]
pos_examples = [(features(reviews.words(i)), 'pos') for i in pos_ids]
train_set = pos_examples + neg_examples
classifier = NaiveBayesClassifier.train(train_set)](https://image.slidesharecdn.com/textclassificationscikit-learnpycon2011ogrisel-110311132018-phpapp01/85/Statistical-Machine-Learning-for-Text-Classification-with-scikit-learn-and-NLTK-21-320.jpg)







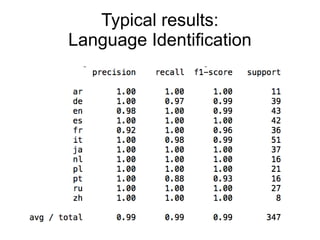
![Typical results:
Language Identification
● 15 Wikipedia articles
● [p.text_content() for p in html_tree.findall('//p')]
● CharNGramAnalyzer(min_n=1, max_n=3)
● TF-IDF
● LinearSVC](https://image.slidesharecdn.com/textclassificationscikit-learnpycon2011ogrisel-110311132018-phpapp01/85/Statistical-Machine-Learning-for-Text-Classification-with-scikit-learn-and-NLTK-33-320.jpg)



This document discusses using machine learning algorithms and natural language processing tools for text classification tasks. It covers using scikit-learn and NLTK to extract features from text, build predictive models, and evaluate performance on tasks like sentiment analysis, topic categorization, and language identification. Feature extraction methods discussed include bag-of-words, TF-IDF, n-grams, and collocations. Classifiers covered are Naive Bayes and linear support vector machines. The document reports typical accuracy results in the 70-97% range for different datasets and models.