Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
なおき きしだ
PDF, PPTX
11,746 views
Java8 コーディングベストプラクティス and NetBeansのメモリログから...
JJUG CCC 2017 Springの資料です
Software
◦
Read more
5
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 63
2
/ 63
3
/ 63
4
/ 63
5
/ 63
6
/ 63
7
/ 63
8
/ 63
9
/ 63
10
/ 63
11
/ 63
12
/ 63
13
/ 63
14
/ 63
15
/ 63
16
/ 63
17
/ 63
18
/ 63
19
/ 63
20
/ 63
21
/ 63
22
/ 63
23
/ 63
24
/ 63
25
/ 63
26
/ 63
27
/ 63
28
/ 63
29
/ 63
30
/ 63
31
/ 63
32
/ 63
33
/ 63
34
/ 63
35
/ 63
36
/ 63
37
/ 63
38
/ 63
39
/ 63
40
/ 63
41
/ 63
42
/ 63
43
/ 63
44
/ 63
45
/ 63
46
/ 63
47
/ 63
48
/ 63
49
/ 63
50
/ 63
51
/ 63
52
/ 63
53
/ 63
54
/ 63
55
/ 63
56
/ 63
57
/ 63
58
/ 63
59
/ 63
60
/ 63
61
/ 63
62
/ 63
63
/ 63
More Related Content
PDF
10のJava9で変わるJava8の嫌なとこ!
by
bitter_fox
PDF
思ったほど怖くない! Haskell on JVM 超入門 #jjug_ccc #ccc_l8
by
y_taka_23
PDF
Javaはどのように動くのか~スライドでわかるJVMの仕組み
by
Chihiro Ito
PDF
Javaチョットデキルへの道〜JavaコアSDKに見る真似したいコード10選〜
by
JustSystems Corporation
PPTX
JEP280: Java 9 で文字列結合の処理が変わるぞ!準備はいいか!? #jjug_ccc
by
YujiSoftware
PPTX
Heap statsfx analyzer
by
Yasumasa Suenaga
PDF
Introduction to JShell #JavaDayTokyo #jdt_jshell
by
bitter_fox
PDF
Frege, What a Non-strict Language
by
y_taka_23
10のJava9で変わるJava8の嫌なとこ!
by
bitter_fox
思ったほど怖くない! Haskell on JVM 超入門 #jjug_ccc #ccc_l8
by
y_taka_23
Javaはどのように動くのか~スライドでわかるJVMの仕組み
by
Chihiro Ito
Javaチョットデキルへの道〜JavaコアSDKに見る真似したいコード10選〜
by
JustSystems Corporation
JEP280: Java 9 で文字列結合の処理が変わるぞ!準備はいいか!? #jjug_ccc
by
YujiSoftware
Heap statsfx analyzer
by
Yasumasa Suenaga
Introduction to JShell #JavaDayTokyo #jdt_jshell
by
bitter_fox
Frege, What a Non-strict Language
by
y_taka_23
What's hot
PDF
Reactive Extensionsで非同期処理を簡単に
by
Yoshifumi Kawai
PDF
イマドキの現場で使えるJavaライブラリ事情
by
takezoe
PPTX
「書ける」から「できる」になれる! ~Javaメモリ節約ノウハウ話~
by
JustSystems Corporation
PPTX
JJUG CCC 2017 Fall オレオレJVM言語を作ってみる
by
Koichi Sakata
PDF
Javaの進化にともなう運用性の向上はシステム設計にどういう変化をもたらすのか
by
Yoshitaka Kawashima
PDF
Java SE 9の紹介: モジュール・システムを中心に
by
Taku Miyakawa
PDF
CEDEC 2018 最速のC#の書き方 - C#大統一理論へ向けて性能的課題を払拭する
by
Yoshifumi Kawai
PDF
Java開発の強力な相棒として今すぐ使えるGroovy
by
Yasuharu Nakano
PPTX
async/await のしくみ
by
信之 岩永
PPTX
Androidで使えるJSON-Javaライブラリ
by
Yukiya Nakagawa
PDF
【Unite Tokyo 2018】さては非同期だなオメー!async/await完全に理解しよう
by
Unity Technologies Japan K.K.
PDF
LogbackからLog4j 2への移行によるアプリケーションのスループット改善 ( JJUG CCC 2021 Fall )
by
Hironobu Isoda
PDF
Java EEを補完する仕様 MicroProfile
by
Norito Agetsuma
PDF
Use JWT access-token on Grails REST API
by
Uehara Junji
PDF
Java SE 8 lambdaで変わる プログラミングスタイル
by
なおき きしだ
PDF
Introduction to JShell: the Java REPL Tool #jjug_ccc #ccc_ab4
by
bitter_fox
KEY
Java One 2012 Tokyo JVM Lang. BOF(Groovy)
by
Uehara Junji
PDF
コンピューティングとJava~なにわTECH道
by
なおき きしだ
PPTX
LINQ 概要 + 結構便利な LINQ to XML
by
ShinichiAoyagi
Reactive Extensionsで非同期処理を簡単に
by
Yoshifumi Kawai
イマドキの現場で使えるJavaライブラリ事情
by
takezoe
「書ける」から「できる」になれる! ~Javaメモリ節約ノウハウ話~
by
JustSystems Corporation
JJUG CCC 2017 Fall オレオレJVM言語を作ってみる
by
Koichi Sakata
Javaの進化にともなう運用性の向上はシステム設計にどういう変化をもたらすのか
by
Yoshitaka Kawashima
Java SE 9の紹介: モジュール・システムを中心に
by
Taku Miyakawa
CEDEC 2018 最速のC#の書き方 - C#大統一理論へ向けて性能的課題を払拭する
by
Yoshifumi Kawai
Java開発の強力な相棒として今すぐ使えるGroovy
by
Yasuharu Nakano
async/await のしくみ
by
信之 岩永
Androidで使えるJSON-Javaライブラリ
by
Yukiya Nakagawa
【Unite Tokyo 2018】さては非同期だなオメー!async/await完全に理解しよう
by
Unity Technologies Japan K.K.
LogbackからLog4j 2への移行によるアプリケーションのスループット改善 ( JJUG CCC 2021 Fall )
by
Hironobu Isoda
Java EEを補完する仕様 MicroProfile
by
Norito Agetsuma
Use JWT access-token on Grails REST API
by
Uehara Junji
Java SE 8 lambdaで変わる プログラミングスタイル
by
なおき きしだ
Introduction to JShell: the Java REPL Tool #jjug_ccc #ccc_ab4
by
bitter_fox
Java One 2012 Tokyo JVM Lang. BOF(Groovy)
by
Uehara Junji
コンピューティングとJava~なにわTECH道
by
なおき きしだ
LINQ 概要 + 結構便利な LINQ to XML
by
ShinichiAoyagi
Viewers also liked
PDF
VMの歩む道。 Dalvik、ART、そしてJava VM
by
yy yank
PDF
Jjugccc2017spring-postgres-ccc_m1
by
Kosuke Kida
PDF
Java8移行は怖くない~エンタープライズ案件でのJava8移行事例~
by
Hiroyuki Ohnaka
PDF
SpotBugs(FindBugs)による 大規模ERPのコード品質改善
by
Works Applications
PPTX
新卒2年目から始めるOSSのススメ~明日からできるコミットデビュー~
by
Yoshio Kajikuri
PDF
ヤフーの広告レポートシステムをSpring Cloud Stream化するまで #jjug_ccc #ccc_a4
by
Yahoo!デベロッパーネットワーク
PPTX
JJUG CCC 2017 Spring Seasar2からSpringへ移行した俺たちのアプリケーションがマイクロサービスアーキテクチャへ歩み始めた
by
Koichi Sakata
PPTX
グラフデータベース入門
by
Masaya Dake
PDF
Java Clientで入門する Apache Kafka #jjug_ccc #ccc_e2
by
Yahoo!デベロッパーネットワーク
PDF
Polyglot on the JVM with Graal (English)
by
Logico
PDF
日本Javaグループ2017年定期総会 #jjug
by
日本Javaユーザーグループ
PDF
2017spring jjug ccc_f2
by
Kazuhiro Wada
PPTX
サーバサイド Kotlin
by
Hiroki Ohtani
PPTX
データ履歴管理のためのテンポラルデータモデルとReladomoの紹介 #jjug_ccc #ccc_g3
by
Hiroshi Ito
PPTX
U-NEXT学生インターン、過激なJavaの学び方と過激な要求
by
hajime funaki
PDF
Introduction of Project Jigsaw
by
Yuichi Sakuraba
PDF
Arachne Unweaved (JP)
by
Ikuru Kanuma
PPTX
Jjug ccc
by
Tanaka Yuichi
PPTX
Kotlin is charming; The reasons Java engineers should start Kotlin.
by
JustSystems Corporation
PDF
Java libraries you can't afford to miss
by
Andres Almiray
VMの歩む道。 Dalvik、ART、そしてJava VM
by
yy yank
Jjugccc2017spring-postgres-ccc_m1
by
Kosuke Kida
Java8移行は怖くない~エンタープライズ案件でのJava8移行事例~
by
Hiroyuki Ohnaka
SpotBugs(FindBugs)による 大規模ERPのコード品質改善
by
Works Applications
新卒2年目から始めるOSSのススメ~明日からできるコミットデビュー~
by
Yoshio Kajikuri
ヤフーの広告レポートシステムをSpring Cloud Stream化するまで #jjug_ccc #ccc_a4
by
Yahoo!デベロッパーネットワーク
JJUG CCC 2017 Spring Seasar2からSpringへ移行した俺たちのアプリケーションがマイクロサービスアーキテクチャへ歩み始めた
by
Koichi Sakata
グラフデータベース入門
by
Masaya Dake
Java Clientで入門する Apache Kafka #jjug_ccc #ccc_e2
by
Yahoo!デベロッパーネットワーク
Polyglot on the JVM with Graal (English)
by
Logico
日本Javaグループ2017年定期総会 #jjug
by
日本Javaユーザーグループ
2017spring jjug ccc_f2
by
Kazuhiro Wada
サーバサイド Kotlin
by
Hiroki Ohtani
データ履歴管理のためのテンポラルデータモデルとReladomoの紹介 #jjug_ccc #ccc_g3
by
Hiroshi Ito
U-NEXT学生インターン、過激なJavaの学び方と過激な要求
by
hajime funaki
Introduction of Project Jigsaw
by
Yuichi Sakuraba
Arachne Unweaved (JP)
by
Ikuru Kanuma
Jjug ccc
by
Tanaka Yuichi
Kotlin is charming; The reasons Java engineers should start Kotlin.
by
JustSystems Corporation
Java libraries you can't afford to miss
by
Andres Almiray
Similar to Java8 コーディングベストプラクティス and NetBeansのメモリログから...
PDF
60分で体験する Stream / Lambda ハンズオン
by
Hiroto Yamakawa
PDF
F#入門 ~関数プログラミングとは何か~
by
Nobuhisa Koizumi
PPTX
【java8 勉強会】 怖くない!ラムダ式, Stream API
by
dcomsolution
PPTX
Java Puzzlers JJUG CCC 2016
by
Yoshio Terada
PDF
ゆるふわJava8入門
by
dcubeio
PDF
リーダブルコード 第二章
by
Yuto Ogi
PDF
NetBeansのメモリ使用ログから機械学習できしだが働いてるかどうか判定する
by
なおき きしだ
PDF
[豆ナイト]Java small object programming
by
Yuichi Hasegawa
PDF
社内Java8勉強会 ラムダ式とストリームAPI
by
Akihiro Ikezoe
PDF
函館IKA Eclipse活用術
by
Masahiro Wakame
PDF
Java8 lambdas chap03
by
ohtsuchi
PPTX
Project lambda
by
Appresso Engineering Team
PDF
Java9直前!最近のJava復習ハンズオン
by
Hiroto Yamakawa
PPTX
関数型言語&形式的手法セミナー(3)
by
啓 小笠原
PPTX
Java8 Lambda chapter5
by
Takinami Kei
PDF
Programming in Scala Chapter 17 Collections
by
Joongjin Bae
PDF
Refactoring point of Kotlin application
by
Recruit Lifestyle Co., Ltd.
PDF
⾃動プログラム修正による マージ競合の⾃動解決を⽬指して(SES 2020 発表資料)
by
katsuhisamaruyama
PDF
kollectionの紹介
by
Kota Mizushima
PDF
B33 Super HadoopでRockなR&D by 平間大輔
by
Insight Technology, Inc.
60分で体験する Stream / Lambda ハンズオン
by
Hiroto Yamakawa
F#入門 ~関数プログラミングとは何か~
by
Nobuhisa Koizumi
【java8 勉強会】 怖くない!ラムダ式, Stream API
by
dcomsolution
Java Puzzlers JJUG CCC 2016
by
Yoshio Terada
ゆるふわJava8入門
by
dcubeio
リーダブルコード 第二章
by
Yuto Ogi
NetBeansのメモリ使用ログから機械学習できしだが働いてるかどうか判定する
by
なおき きしだ
[豆ナイト]Java small object programming
by
Yuichi Hasegawa
社内Java8勉強会 ラムダ式とストリームAPI
by
Akihiro Ikezoe
函館IKA Eclipse活用術
by
Masahiro Wakame
Java8 lambdas chap03
by
ohtsuchi
Project lambda
by
Appresso Engineering Team
Java9直前!最近のJava復習ハンズオン
by
Hiroto Yamakawa
関数型言語&形式的手法セミナー(3)
by
啓 小笠原
Java8 Lambda chapter5
by
Takinami Kei
Programming in Scala Chapter 17 Collections
by
Joongjin Bae
Refactoring point of Kotlin application
by
Recruit Lifestyle Co., Ltd.
⾃動プログラム修正による マージ競合の⾃動解決を⽬指して(SES 2020 発表資料)
by
katsuhisamaruyama
kollectionの紹介
by
Kota Mizushima
B33 Super HadoopでRockなR&D by 平間大輔
by
Insight Technology, Inc.
More from なおき きしだ
PDF
これからのコンピューティングの変化とこれからのプログラミング at 広島
by
なおき きしだ
PDF
JavaOne報告2017
by
なおき きしだ
PDF
Javaプログラミング入門
by
なおき きしだ
PPTX
New thing in JDK10 even that scala-er should know
by
なおき きしだ
PDF
GraalVMの紹介とTruffleでPHPぽい言語を実装したら爆速だった話
by
なおき きしだ
PDF
最近のJava事情
by
なおき きしだ
PDF
Java10 and Java11 at JJUG CCC 2018 Spr
by
なおき きしだ
PDF
Summary of JDK10 and What will come into JDK11
by
なおき きしだ
PDF
Summary of JDK10 and What will come into JDK11
by
なおき きしだ
PDF
GraalVMについて
by
なおき きしだ
PDF
GraalVM at Fukuoka LT
by
なおき きしだ
PDF
これからのJava言語と実行環境
by
なおき きしだ
PPTX
Java Release Model (on Scala Matsuri)
by
なおき きしだ
PDF
VRカメラが楽しいのでブラウザで見たくなった話
by
なおき きしだ
PDF
怖いコードの話 2018/7/18
by
なおき きしだ
PDF
JavaOne2016報告
by
なおき きしだ
PDF
プログラマになるためになにを勉強するか at 九州学生エンジニアLT大会
by
なおき きしだ
PDF
これからのコンピューティングの変化とこれからのプログラミング in 福岡 2018/12/8
by
なおき きしだ
PDF
Java新機能観察日記 - JJUGナイトセミナー
by
なおき きしだ
PDF
JavaOne2017で感じた、Javaのいまと未来 in 大阪
by
なおき きしだ
これからのコンピューティングの変化とこれからのプログラミング at 広島
by
なおき きしだ
JavaOne報告2017
by
なおき きしだ
Javaプログラミング入門
by
なおき きしだ
New thing in JDK10 even that scala-er should know
by
なおき きしだ
GraalVMの紹介とTruffleでPHPぽい言語を実装したら爆速だった話
by
なおき きしだ
最近のJava事情
by
なおき きしだ
Java10 and Java11 at JJUG CCC 2018 Spr
by
なおき きしだ
Summary of JDK10 and What will come into JDK11
by
なおき きしだ
Summary of JDK10 and What will come into JDK11
by
なおき きしだ
GraalVMについて
by
なおき きしだ
GraalVM at Fukuoka LT
by
なおき きしだ
これからのJava言語と実行環境
by
なおき きしだ
Java Release Model (on Scala Matsuri)
by
なおき きしだ
VRカメラが楽しいのでブラウザで見たくなった話
by
なおき きしだ
怖いコードの話 2018/7/18
by
なおき きしだ
JavaOne2016報告
by
なおき きしだ
プログラマになるためになにを勉強するか at 九州学生エンジニアLT大会
by
なおき きしだ
これからのコンピューティングの変化とこれからのプログラミング in 福岡 2018/12/8
by
なおき きしだ
Java新機能観察日記 - JJUGナイトセミナー
by
なおき きしだ
JavaOne2017で感じた、Javaのいまと未来 in 大阪
by
なおき きしだ
Java8 コーディングベストプラクティス and NetBeansのメモリログから...
1.
NetBeansのメモリ使用ログから 機械学習で きしだが働いてるかどうか判定する 2017/5/20 LINE Fukuoka
きしだ なおき Java8 コーディング ベストプラクティス &
2.
自己紹介 ● きしだ なおき ● LINE FukuokaでJavaを書いてます
3.
今日のはなし ● Java8コーディングベストプラクティス ● NetBeansのメモリログから、機械学習で きしだが働いてるかどうか判定する
4.
ところで、なぜ2本立て? ● Call for Papersに2本出した –
Java8コーディング〜(30分) – NetBeansのメモリログから〜(50分)
5.
ところで、なぜ2本立て? ● 両方とおった – お、おう
6.
ところで、なぜ2本立て? ● やっぱり1枠で。50分で – でもJava8のほうが人気タカカッタヨ
7.
ところで、なぜ2本立て? ● あ、45分で – Java8中心にやろう – 先にNetBeansのメモリログから〜をやります
8.
NetBeansのメモリログから 機械学習で きしだが働いてるかどうか 判定する
9.
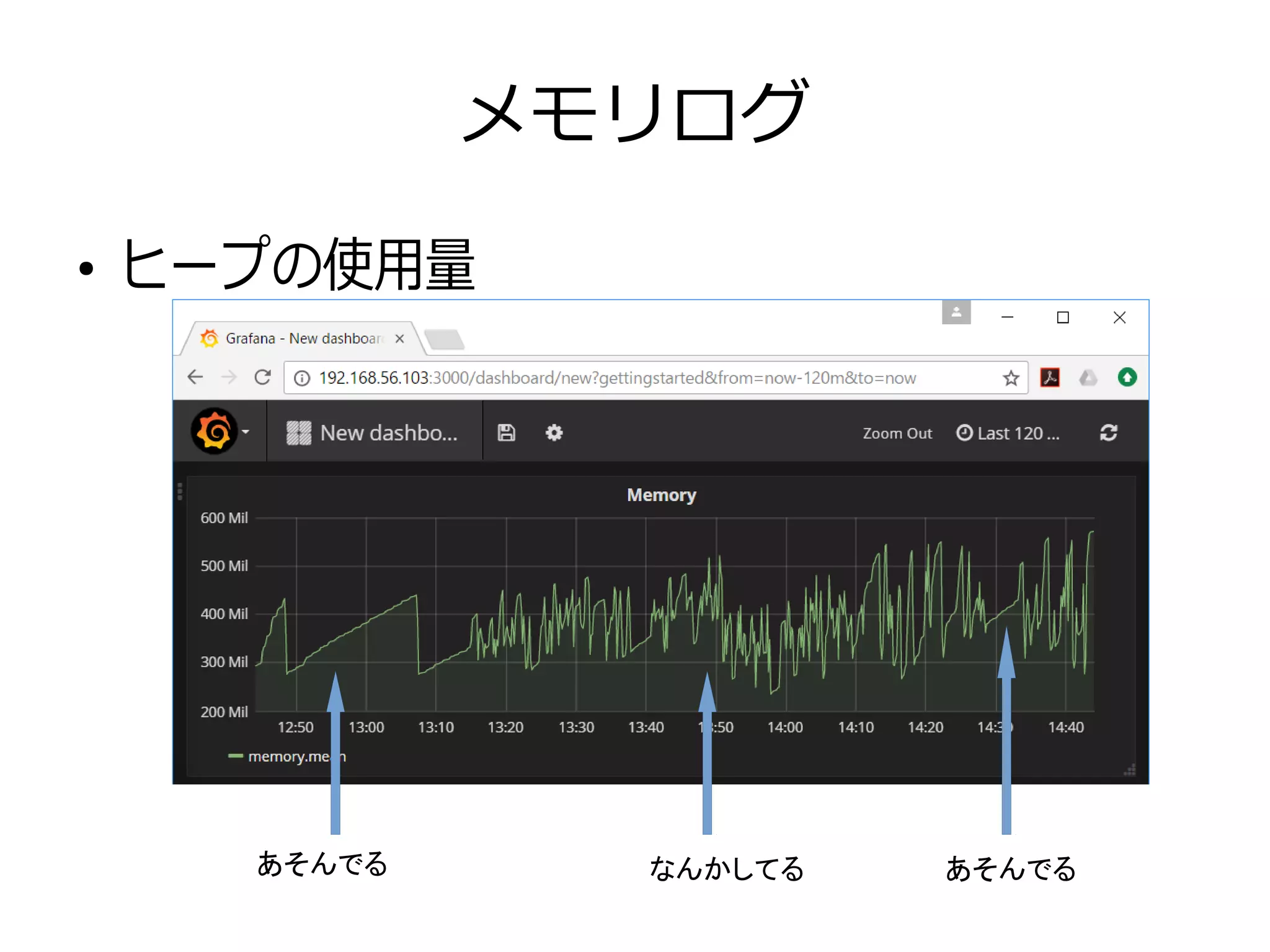
メモリログ ● ヒープの使用量 あそんでる あそんでるなんかしてる
10.
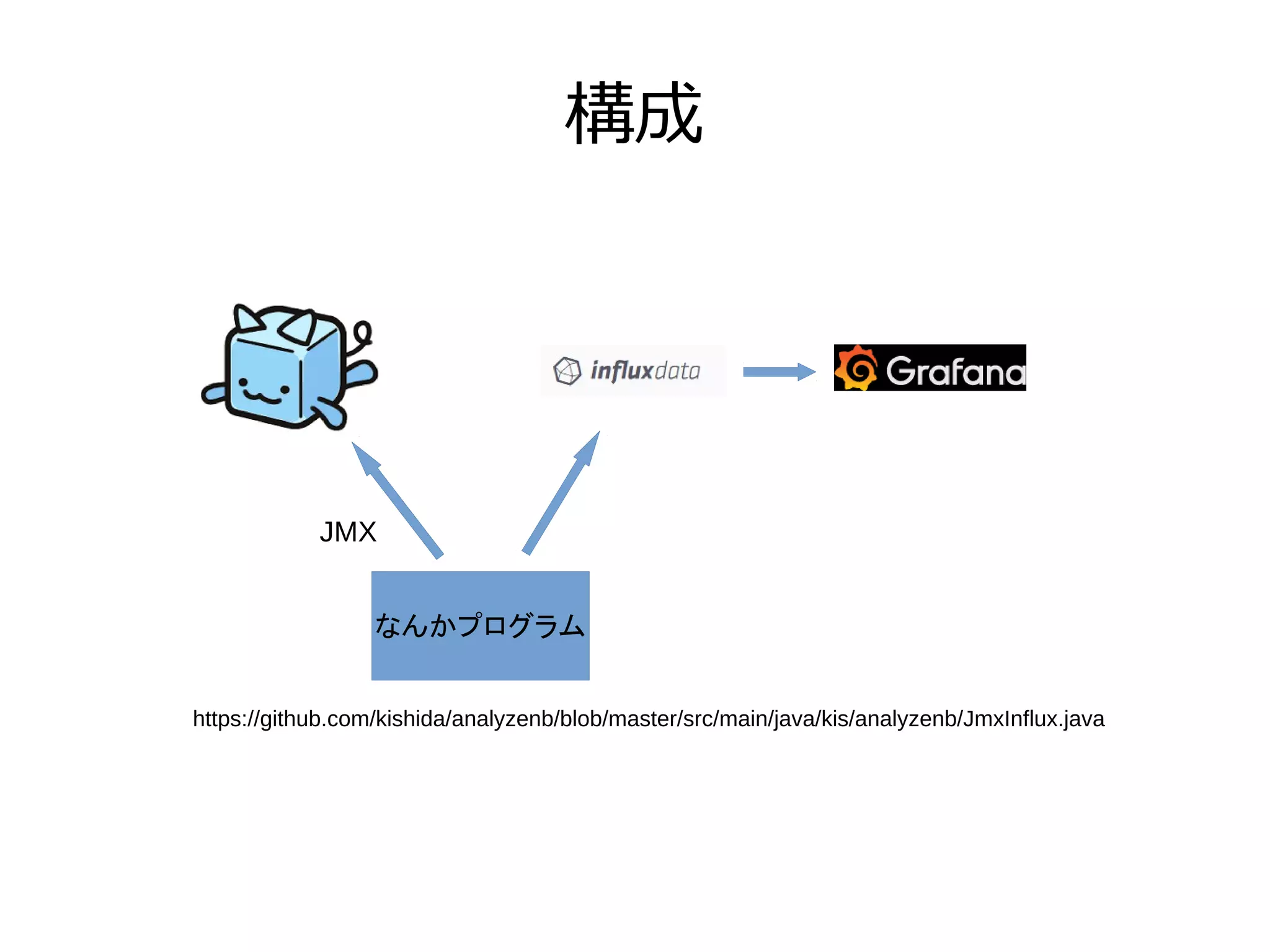
どう取るか ● JMXという仕組みがある ● InfluxDBにつっこむ ● Grafanaで見る
11.
構成 なんかプログラム JMX https://github.com/kishida/analyzenb/blob/master/src/main/java/kis/analyzenb/JmxInflux.java
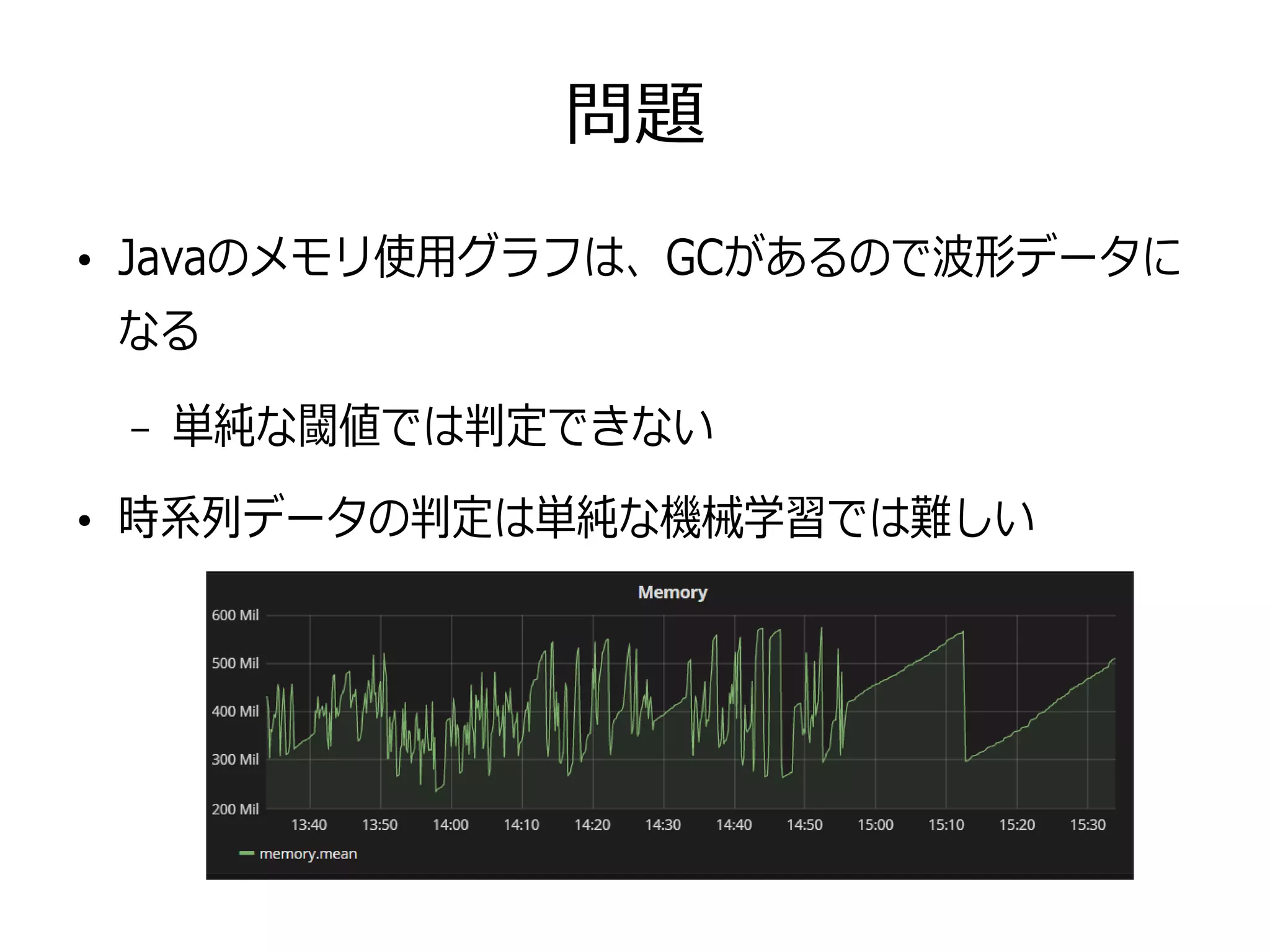
12.
問題 ● Javaのメモリ使用グラフは、GCがあるので波形データに なる – 単純な閾値では判定できない ● 時系列データの判定は単純な機械学習では難しい
13.
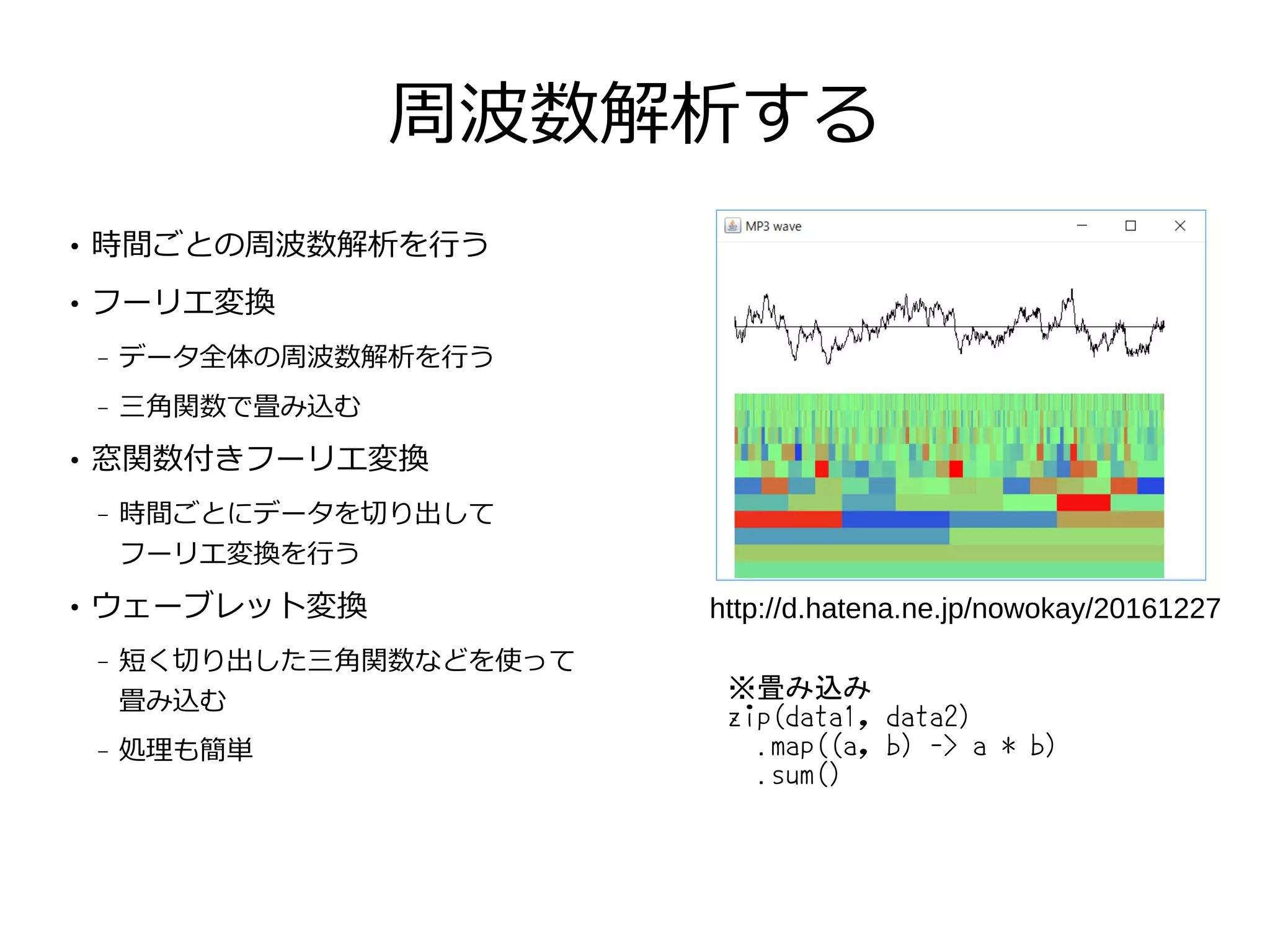
周波数解析する ● 時間ごとの周波数解析を行う ● フーリエ変換 – データ全体の周波数解析を行う – 三角関数で畳み込む ● 窓関数付きフーリエ変換 –
時間ごとにデータを切り出して フーリエ変換を行う ● ウェーブレット変換 – 短く切り出した三角関数などを使って 畳み込む – 処理も簡単 http://d.hatena.ne.jp/nowokay/20161227 ※畳み込み zip(data1, data2) .map((a, b) -> a * b) .sum()
14.
離散ウェーブレット変換 ● 隣同士を引いて2で割る – 移動差分 – ハイパスフィルタになる(高い周波数だけ残す) –
ウェーブレット値 ● 隣同士を足して2で割る – 移動平均 – ローパスフィルタになる(低い周波数だけ残す) – より低い周波数の解析に使う
15.
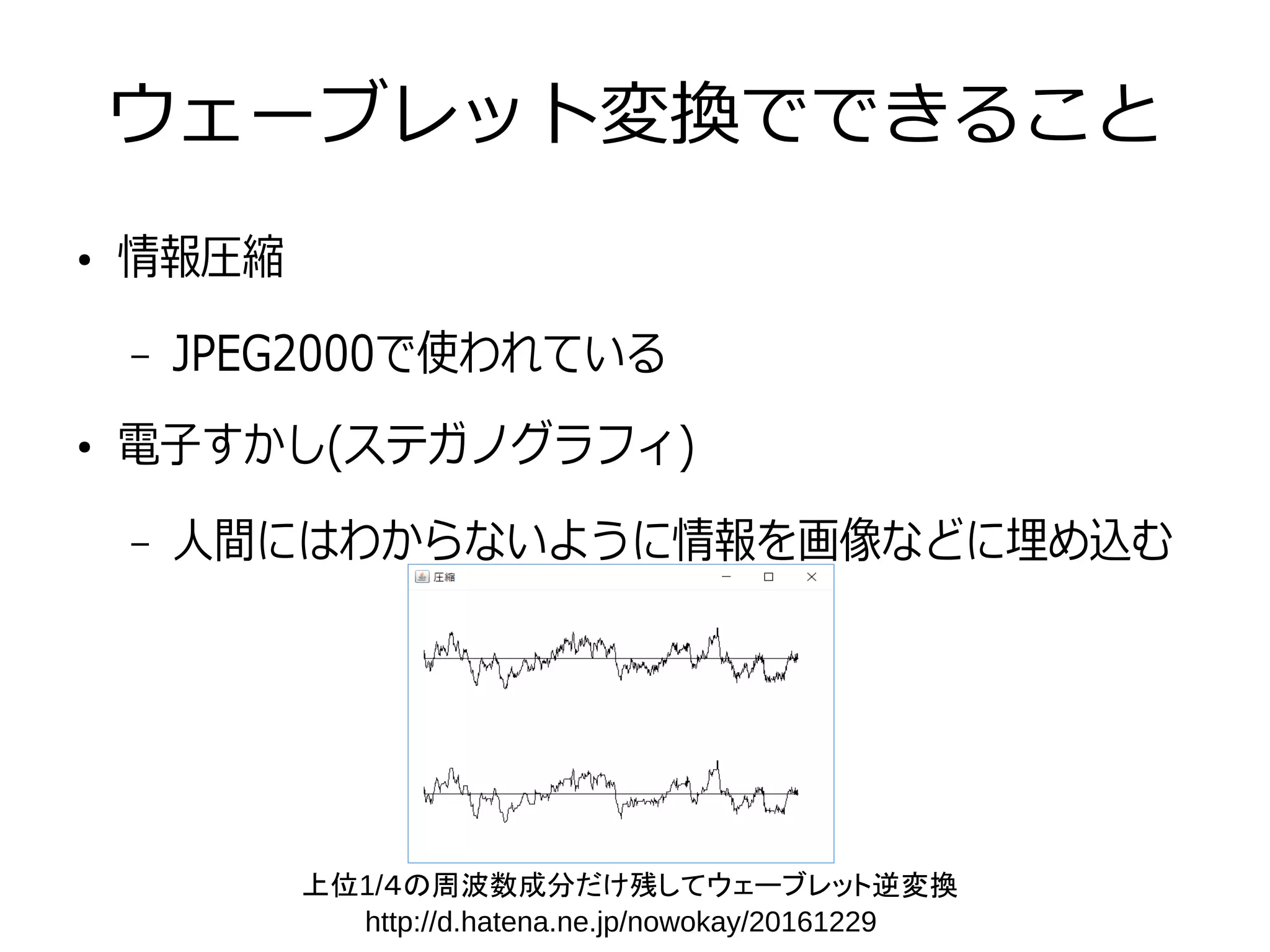
ウェーブレット変換でできること ● 情報圧縮 – JPEG2000で使われている ● 電子すかし(ステガノグラフィ) – 人間にはわからないように情報を画像などに埋め込む 上位1/4の周波数成分だけ残してウェーブレット逆変換 http://d.hatena.ne.jp/nowokay/20161229
16.
ウェーブレット変換の適用 ● 512データ(8分30秒)をウェーブレット変換 する ● 512 = 2^9 –
9+1=10周波数のデータができる
17.
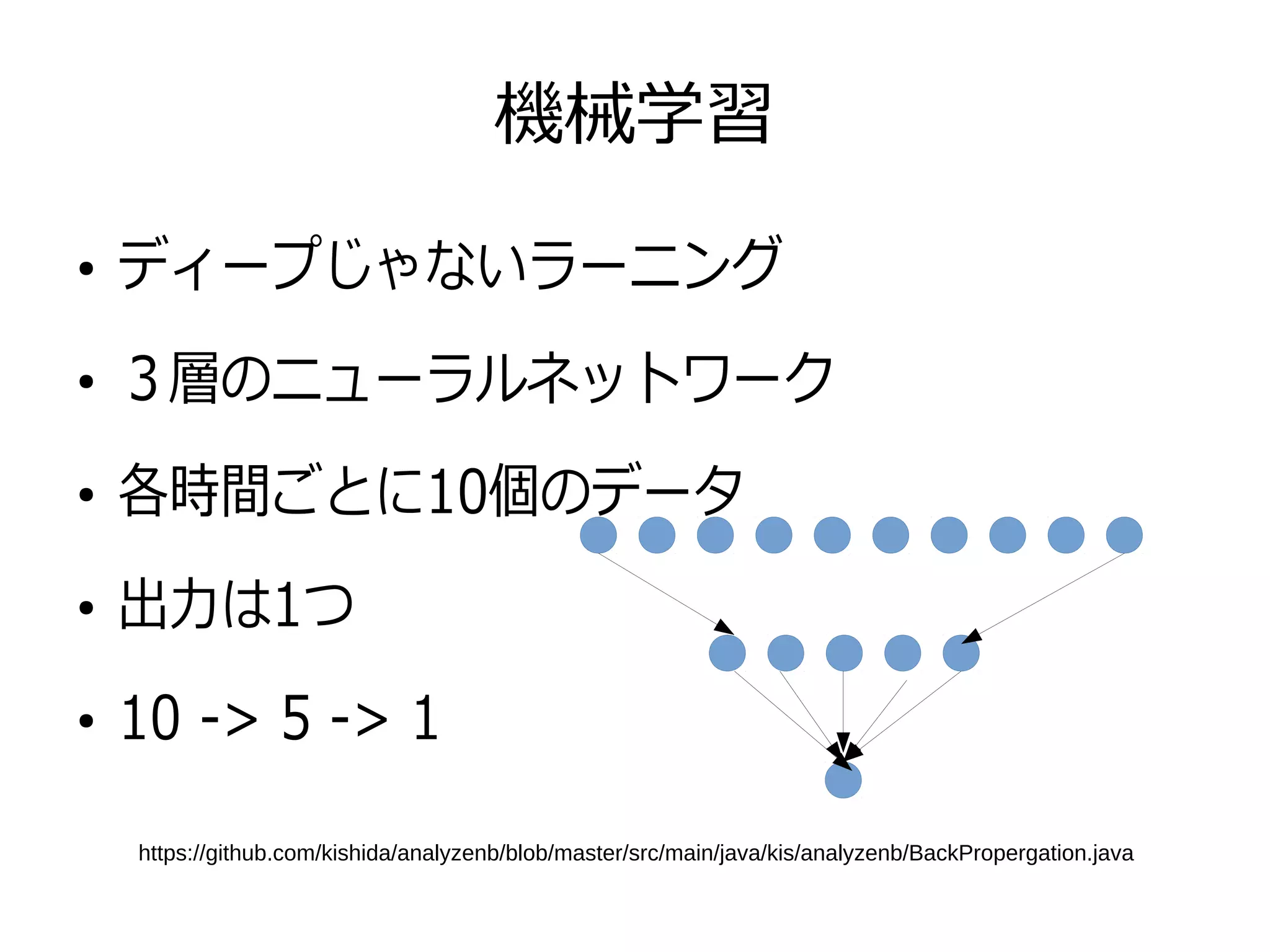
機械学習 ● ディープじゃないラーニング ● 3層のニューラルネットワーク ● 各時間ごとに10個のデータ ● 出力は1つ ● 10 -> 5
-> 1 https://github.com/kishida/analyzenb/blob/master/src/main/java/kis/analyzenb/BackPropergation.java
18.
教師データはどうする? ● 機械学習では、学習用に、入力値とその入力が どう判定されるべきかという教師データが必要
19.
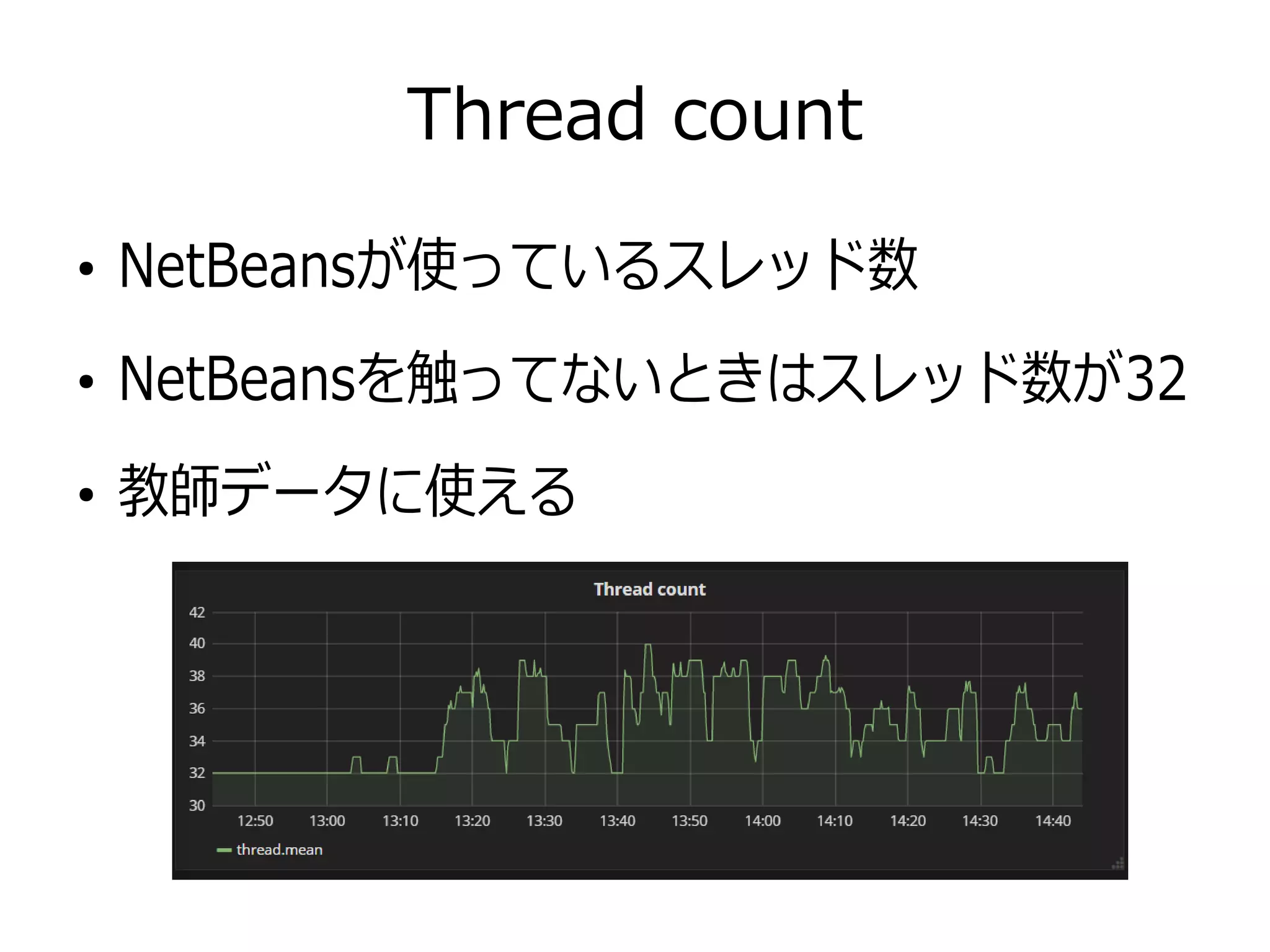
Thread count ● NetBeansが使っているスレッド数 ● NetBeansを触ってないときはスレッド数が32 ● 教師データに使える
20.
機械学習とか不要では? ● ロマンです
21.
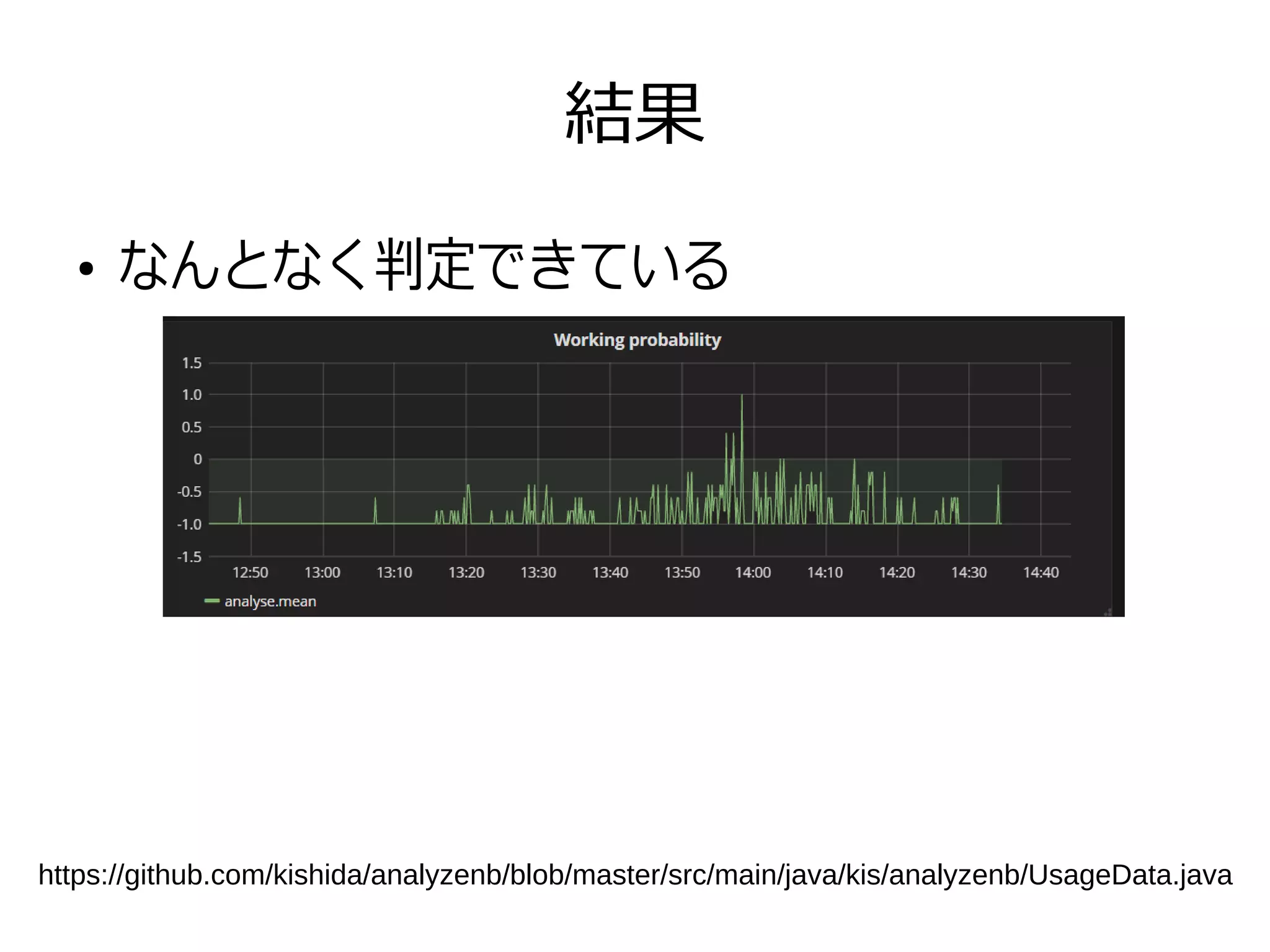
結果 ● なんとなく判定できている https://github.com/kishida/analyzenb/blob/master/src/main/java/kis/analyzenb/UsageData.java
22.
他の手法 ● ニューラルネットではなくSVMで識別する ● RNN(循環ニューラルネットワーク)を使う – 学習がうまくいけばウェーブレット変換と 同じ計算になりうる ● 近傍法など障害検知手法を使う – 多値分類はできない –
学習が不要
23.
まとめ ● 時系列データのウェーブレット変換からなんと なく状態を把握することができた ● 常に働いていれば判定など不要
24.
Java8コーディング ベストプラクティス
25.
話すこと ● Java8でのコーディングで気をつけることを まとめる ● APIの使い方自体はちゃんと把握しておく
26.
Agenda ● 一般的なこと ● Java 8 ● Java 7以前
27.
一般的なこと ● Immutability ● 論理式をうまく使う ● 大事なものはインデントを浅く ● オーバーロード
28.
Immutability ● 変数への再代入を避ける ● ImmutableList/Mapを使う
29.
変数への再代入を避ける String message =
"default"; if (hoge) { message = "ほげ"; } String message; if (hoge) { message = "ほげ"; } else { message = "default"; }
30.
変数への再代入を避ける String message; if (hoge)
{ message = "ほげ"; } else { message = "default"; } ● 再代入がないほうが最適化がかかりやすい ● 代入を忘れた場合にコンパイルエラーになる
31.
ImmutableList/Mapを使う ● Guavaのライブラリ ● Collectors::toListの代わりに ImmutableList::toImmutableList ● ofが便利 – Java 9が待てない人のために
32.
toImmutableList strs.stream() .map(String::toUpperCase) .collect(ImmutableList.toImmutableList()); ● 値が変更されないことを明示する ● 並列実行で不具合が起きない
33.
ofが便利 ● 固定値のListやMapを作る場合 ● Java 9ではList.of/Map.ofが入る Map<String, String>
countries = ImmutableMap.of( "JP", "日本", "US", "アメリカ");
34.
論理式をうまく使う ● ド・モルガンの法則を活用する ● 片方が定数リテラルを返す条件演算子は 論理演算にできる ● ifでbooleanを反転させない
35.
ド・モルガンの法則を使う if (!(str !=
null && !str.isEmpty())) { ... } if (str == null || str.isEmpty()) { ... }
36.
リテラルを返す式を論理演算に ● 片方がbooleanリテラルの条件式は論理演算に boolean f
= str == null ? true : str.isEmpty(); boolean f = str == null || str.isEmpty();
37.
大事なものはインデントを浅く ● 早期リターン if (hoge) { Foo
foo = bar.getSomething(); return foo.getImportantValue(); } return null; if (!hoge) { return null; } Foo foo = bar.getSomething(); return foo.getImportantValue();
38.
ifでbooleanを反転させない ● booleanリテラルを返すとき、条件が なりたったときにはtrue、elseでは falseを返すようにする。 if (hoge) { someProc(); return
false; } else { anotherProc(); return true; } if (!hoge) { anotherProc(); return true; } else { someProc(); return false; }
39.
オーバーロード ● 引数省略のために使う ● 処理を集約させる ● 引数が多いものを前に void foo(int count,
String message) { IntStream.range(0, count) .mapToObj(i -> i + ":" + message) .forEach(System.out::println); } void foo(String message) { foo(1, message); } void foo() { foo(null); }
40.
処理が違うならメソッド名を変える List<Product> find(Author a); List<Product>
find(Category c); List<Product> findByAuthor(Author a); List<Product> findByCategory(Category c);
41.
Java 8 ● Stream ● Optional ● FunctionalInterface ● ラムダ ● Date and
Time
42.
Stream ● forEachのifをfilterにできる ● forEachでの値変換はmapにできる ● forEachの入れ子はflatMapにできる ● count() > 0は使わない
43.
forEachのifをfilterにできる strs.forEach(s -> { if
(s.length() >= 5) { return; } String upper = s.toUpperCase(); Stream.of(upper.split(",")) .forEach(Syastem.out::println); }); strs.stream() .filter(s -> s.length() < 5) .forEach(s -> { String upper = s.toUpperCase(); Stream.of(upper.split(",")) .forEach(System.out::println); });
44.
forEachでの値変換はmapにできる strs.stream() .filter(s -> s.length()
< 5) .forEach(s -> { String upper = s.toUpperCase(); Stream.of(upper.split(",")) .forEach(System.out::println); }); strs.stream() .filter(s -> s.length() < 5) .map(s -> s.toUpperCase()) .forEach(upper -> { Stream.of(upper.split(",")) .forEach(System.out::println); });
45.
forEachの入れ子はflatMapにできる strs.stream() .filter(s -> s.length()
< 5) .map(s -> s.toUpperCase()) .forEach(upper -> { Stream.of(upper.split(",")) .forEach(System.out::println); }); strs.stream() .filter(s -> s.length() < 5) .map(s -> s.toUpperCase()) .flatMap(upper -> Stream.of(upper.split(","))) .forEach(System.out::println);
46.
同じオブジェクトには同じ変数 strs.stream() .filter(s -> s.length()
< 5) .map(s -> s.toUpperCase()) .flatMap(upper -> Stream.of(upper.split(","))) .forEach(System.out::println); strs.stream() .filter(a -> a.length() < 5) .map(b -> b.toUpperCase()) .flatMap(upper -> Stream.of(upper.split(","))) .forEach(System.out::println);
47.
Streamで書くメリット ● 行われる操作が限定される ● 変数の行く先を追わなくてよい ● 結果、読みやすくなる strs.stream() .filter(s -> s.length()
< 5) .map(s -> s.toUpperCase()) .flatMap(upper -> Stream.of(upper.split(","))) .forEach(System.out::println);
48.
count() > 0は使わない strs.stream().filter(s
-> s.length() > 5).count() > 0 strs.stream().anyMatch(s -> s.length() > 5)
49.
例外処理はあきらめる ● 例外と関数型プログラミングは相性が悪い ● あきらめてtry〜catchを書く ● streamをあきらめてfor文を使う
50.
Optional ● ifPresentのifをfilterにできる ● ifPresentでの値変換はmapにできる ● ifPresentの入れ子はflatMapにできる ● 引数には使わない ● orElseThrowにException::newを書かない
51.
ifPresentのifをfilterに strOpt.ifPresent(s -> { if
(s.length() >= 5) { return; } String upper = s.toUpperCase(); findSome(upper) // return Optional .ifPresent(Syastem.out::println); }); strOpt.filter(s -> s.length() >= 5) .ifPresent(s -> { String upper = s.toUpperCase(); findSome(upper) // return Optional .ifPresent(System.out::println); });
52.
ifPresentでの値変換をmapに strOpt.filter(s -> s.length()
>= 5) .ifPresent(s -> { String upper = s.toUpperCase(); findSome(upper) // return Optional .ifPresent(System.out::println); }); strOpt.filter(s -> s.length() >= 5) .map(s -> s.toUpperCase()) .ifPresent(upper -> { findSome(upper) // return Optional .ifPresent(System.out::println); });
53.
ifPresentの入れ子をflatMapに strOpt.filter(s -> s.length()
>= 5) .map(s -> s.toUpperCase()) .ifPresent(upper -> { findSome(upper) // return Optional .ifPresent(System.out::println); }); strOpt.filter(s -> s.length() >= 5) .map(s -> s.toUpperCase()) .flatMap(upper -> findSome(upper)) .ifPresent(System.out::println);
54.
どこかで見た。 ● Optional.ifPresentはStream.forEachと同じ – Optionalを要素1つまでのStreamと考える
55.
引数にOptionalを使わない ● メソッド定義者がnullに対応する ● フレームワークの入り口は除く
56.
OrElseThrowにException::newを 渡さない ● なにかのキーから値を取得しようと思って失敗 している。 ● 例外の原因を究明するためにはキーの値が必要 ● 例外メッセージにキーの値を含める必要がある
57.
FunctionalInterface ● 実装したクラスを作らない ● ラムダを割り当てた変数を作らない String twice(String s)
{ return s + s; } strs.stream() .map(Util::twice) .forEach(System.out::println); Function<String, String> twice = s -> s + s; strs.stream() .map(twice) .forEach(System.out::println);
58.
ラムダ ● むやみにAtomicInteger/Longを使わない AtomicInteger count =
new AtomicInteger(0); strs.stream() .filter(s -> s.length() < 5) .forEach(s -> count.incrementAndGet()); int[] count = {0}; strs.stream() .filter(s -> s.length() < 5) .forEach(s -> ++count[0]);
59.
Date and Time ● 自分で時間を計算しない long
TIME_OUT_MILLIS = 3 * 60 * 60 * 1000; long TIME_OUT_MILLIS = Duration.ofHours(3).toMillis();
60.
Java7以前 ● LinkedListは使わない ● IOExeptionをRuntimeExceptionでラップ しない
61.
LinkedListは使わない ● ほとんどの場合、ArrayListのほうが速い ● LinkedList.remove/insertの実装がひどい – 値をたどってから操作を行う – 途中への値挿入・削除が効率いいという連結リスト のメリットを持っていない
62.
IOExceptionを RuntimeExceptionでラップしない ● UncheckedIOExceptionを使う try { readFile(); } catch
(IOException ex) { throw new RuntimeException(); } try { readFile(); } catch (IOException ex) { throw new UncheckedIOException(); }
63.
まとめ ● 細かいことを積み重ねるとケアレスミスが減っ ていきます。 ● 1ヶ月くらいで慣れて自然にバグが減ります(個 人の感想です)
Download


















































![ラムダ
●
むやみにAtomicInteger/Longを使わない
AtomicInteger count = new AtomicInteger(0);
strs.stream()
.filter(s -> s.length() < 5)
.forEach(s -> count.incrementAndGet());
int[] count = {0};
strs.stream()
.filter(s -> s.length() < 5)
.forEach(s -> ++count[0]);](https://image.slidesharecdn.com/java8andnblog-170520092057/75/Java8-and-NetBeans-58-2048.jpg)



























































![[豆ナイト]Java small object programming](https://cdn.slidesharecdn.com/ss_thumbnails/javasmall-objectprogramming-121027014424-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)































