Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
MicroAd, Inc.(Engineer)
817 views
アドテクに携わって培った アプリをハイパフォーマンスに保つ設計とコーディング
Developers Boost 2019での登壇資料です
Technology
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 31
2
/ 31
3
/ 31
4
/ 31
5
/ 31
6
/ 31
7
/ 31
8
/ 31
9
/ 31
10
/ 31
11
/ 31
12
/ 31
13
/ 31
14
/ 31
15
/ 31
16
/ 31
17
/ 31
18
/ 31
19
/ 31
20
/ 31
21
/ 31
22
/ 31
23
/ 31
24
/ 31
25
/ 31
26
/ 31
27
/ 31
28
/ 31
29
/ 31
30
/ 31
31
/ 31
More Related Content
PDF
マイクロアドのデータ基盤について アドテクを支える基盤〜10Tバイト/日のビッグデータを処理する〜
by
MicroAd, Inc.(Engineer)
PDF
SPARQLでオープンデータ活用!
by
uedayou
PDF
Linked Open Data(LOD)の基本理念と基盤となる技術
by
Kouji Kozaki
PPTX
セマンティック・ウェブのためのRdf owl入門解説.ch5
by
Takahiro Kubo
PPTX
オープンデータをLOD化するデータソン in 高槻
by
Kouji Kozaki
PDF
仕様起因の手戻りを減らして開発効率アップを目指すチャレンジ 【DeNA TechCon 2020 ライブ配信】
by
DeNA
PPTX
リアルタイムPoint cloudデータのビジュアライゼーションについて
by
Ryousuke Wayama
PDF
Linked Open Dataとは
by
Linked Open Dataチャレンジ実行委員会
マイクロアドのデータ基盤について アドテクを支える基盤〜10Tバイト/日のビッグデータを処理する〜
by
MicroAd, Inc.(Engineer)
SPARQLでオープンデータ活用!
by
uedayou
Linked Open Data(LOD)の基本理念と基盤となる技術
by
Kouji Kozaki
セマンティック・ウェブのためのRdf owl入門解説.ch5
by
Takahiro Kubo
オープンデータをLOD化するデータソン in 高槻
by
Kouji Kozaki
仕様起因の手戻りを減らして開発効率アップを目指すチャレンジ 【DeNA TechCon 2020 ライブ配信】
by
DeNA
リアルタイムPoint cloudデータのビジュアライゼーションについて
by
Ryousuke Wayama
Linked Open Dataとは
by
Linked Open Dataチャレンジ実行委員会
What's hot
PDF
ナレッジグラフ/LOD利用技術の入門(後編)
by
KnowledgeGraph
PDF
Micrometer/Prometheusによる大規模システムモニタリング #jsug #sf_26
by
Yahoo!デベロッパーネットワーク
PDF
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
by
Cloudera Japan
PDF
ROS2勉強会 4章前半
by
tomohiro kuwano
PPTX
Redmineでメトリクスを見える化する方法
by
Hidehisa Matsutani
KEY
Go言語のスライスを理解しよう
by
Yasutaka Kawamoto
PDF
GitHub Codespaces と Azure でつくる、エンタープライズレベルの開発環境
by
Kazumi OHIRA
PPTX
Linked Dataの基本原則 -LODを公開するときに知っておきたい基本技術-
by
Kouji Kozaki
PDF
Laravelを用いたゲームサーバーのチューニング
by
NOW PRODUCTION
PDF
Python 3.9からの新定番zoneinfoを使いこなそう
by
Ryuji Tsutsui
PDF
2. BigQuery ML を用いた時系列データの解析 (ARIMA model)
by
幸太朗 岩澤
PDF
オントロジー工学に基づく 知識の体系化と利用
by
Kouji Kozaki
PDF
ナレッジグラフ/LOD利用技術の入門(前編)
by
KnowledgeGraph
PDF
CycleGANで顔写真をアニメ調に変換する
by
meownoisy
PDF
Hadoop/Spark を使うなら Bigtop を使い熟そう! ~並列分散処理基盤のいま、から Bigtop の最近の取り組みまで一挙ご紹介~(Ope...
by
NTT DATA Technology & Innovation
PDF
Linked Open Data勉強会2020 前編:LODの基礎・作成・公開
by
KnowledgeGraph
PDF
Swiftで、Webサーバにデータを送信・登録しよう!
by
Kanako Kobayashi
PDF
オントロジー工学に基づくセマンティック技術(1)オントロジー工学入門
by
Kouji Kozaki
PDF
WikidataとOSM
by
Kouji Kozaki
PDF
Azure kinect DKハンズオン
by
Takashi Yoshinaga
ナレッジグラフ/LOD利用技術の入門(後編)
by
KnowledgeGraph
Micrometer/Prometheusによる大規模システムモニタリング #jsug #sf_26
by
Yahoo!デベロッパーネットワーク
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
by
Cloudera Japan
ROS2勉強会 4章前半
by
tomohiro kuwano
Redmineでメトリクスを見える化する方法
by
Hidehisa Matsutani
Go言語のスライスを理解しよう
by
Yasutaka Kawamoto
GitHub Codespaces と Azure でつくる、エンタープライズレベルの開発環境
by
Kazumi OHIRA
Linked Dataの基本原則 -LODを公開するときに知っておきたい基本技術-
by
Kouji Kozaki
Laravelを用いたゲームサーバーのチューニング
by
NOW PRODUCTION
Python 3.9からの新定番zoneinfoを使いこなそう
by
Ryuji Tsutsui
2. BigQuery ML を用いた時系列データの解析 (ARIMA model)
by
幸太朗 岩澤
オントロジー工学に基づく 知識の体系化と利用
by
Kouji Kozaki
ナレッジグラフ/LOD利用技術の入門(前編)
by
KnowledgeGraph
CycleGANで顔写真をアニメ調に変換する
by
meownoisy
Hadoop/Spark を使うなら Bigtop を使い熟そう! ~並列分散処理基盤のいま、から Bigtop の最近の取り組みまで一挙ご紹介~(Ope...
by
NTT DATA Technology & Innovation
Linked Open Data勉強会2020 前編:LODの基礎・作成・公開
by
KnowledgeGraph
Swiftで、Webサーバにデータを送信・登録しよう!
by
Kanako Kobayashi
オントロジー工学に基づくセマンティック技術(1)オントロジー工学入門
by
Kouji Kozaki
WikidataとOSM
by
Kouji Kozaki
Azure kinect DKハンズオン
by
Takashi Yoshinaga
Similar to アドテクに携わって培った アプリをハイパフォーマンスに保つ設計とコーディング
PDF
Nds#24 単体テスト
by
Kazumune Katagiri
PDF
AndroidでDIxAOP
by
nfc research
KEY
1.29.user,user,user
by
Tonny Xu
PDF
ケーススタディ/実装 【クラウドアプリケーションのためのオブジェクト指向分析設計講座 第46回】
by
Tomoharu ASAMI
PDF
DDD 20121106 SEA Forum November
by
増田 亨
PDF
ドメイン駆動設計 ( DDD ) をやってみよう
by
増田 亨
PDF
Spring3.1概要x di
by
Yuichi Hasegawa
PDF
アドテクを支える技術 〜1日40億リクエストを捌くには〜
by
MicroAd, Inc.(Engineer)
PDF
ドメイン駆動設計(DDD)の実践Part2
by
増田 亨
PPT
Rpscala2011 0601
by
Hajime Yanagawa
PDF
実装(1) 【クラウドアプリケーションのためのオブジェクト指向分析設計講座 第30回】
by
Tomoharu ASAMI
PDF
文書をプログラムにする技術 - SimpleModeler + Mindmap & SmartDox
by
Tomoharu ASAMI
PDF
アドテク×Scala×パフォーマンスチューニング
by
Yosuke Mizutani
PDF
ScalaMatsuri 2016
by
Yoshitaka Fujii
PDF
ドメイン駆動設計 の 実践 Part3 DDD
by
増田 亨
PDF
継続的8章
by
shinjiyoshida
PDF
設計/原理 【クラウドアプリケーションのためのオブジェクト指向分析設計講座 第28回】
by
Tomoharu ASAMI
PDF
Agile japan2010 rakuten様プレゼン資料
by
Akiko Kosaka
PDF
A Model-Based Development Process for Dependable Robots
by
Keiju Anada
PDF
テスト駆動開発のはじめ方
by
Shuji Watanabe
Nds#24 単体テスト
by
Kazumune Katagiri
AndroidでDIxAOP
by
nfc research
1.29.user,user,user
by
Tonny Xu
ケーススタディ/実装 【クラウドアプリケーションのためのオブジェクト指向分析設計講座 第46回】
by
Tomoharu ASAMI
DDD 20121106 SEA Forum November
by
増田 亨
ドメイン駆動設計 ( DDD ) をやってみよう
by
増田 亨
Spring3.1概要x di
by
Yuichi Hasegawa
アドテクを支える技術 〜1日40億リクエストを捌くには〜
by
MicroAd, Inc.(Engineer)
ドメイン駆動設計(DDD)の実践Part2
by
増田 亨
Rpscala2011 0601
by
Hajime Yanagawa
実装(1) 【クラウドアプリケーションのためのオブジェクト指向分析設計講座 第30回】
by
Tomoharu ASAMI
文書をプログラムにする技術 - SimpleModeler + Mindmap & SmartDox
by
Tomoharu ASAMI
アドテク×Scala×パフォーマンスチューニング
by
Yosuke Mizutani
ScalaMatsuri 2016
by
Yoshitaka Fujii
ドメイン駆動設計 の 実践 Part3 DDD
by
増田 亨
継続的8章
by
shinjiyoshida
設計/原理 【クラウドアプリケーションのためのオブジェクト指向分析設計講座 第28回】
by
Tomoharu ASAMI
Agile japan2010 rakuten様プレゼン資料
by
Akiko Kosaka
A Model-Based Development Process for Dependable Robots
by
Keiju Anada
テスト駆動開発のはじめ方
by
Shuji Watanabe
More from MicroAd, Inc.(Engineer)
PDF
20240229 DEIM2024 【技術報告】広告配信における安定して拡張性のある大量データ処理基盤の必要性と活用
by
MicroAd, Inc.(Engineer)
PDF
Kafka Connect:Iceberg Sink Connectorを使ってみる
by
MicroAd, Inc.(Engineer)
PDF
Apache Kafkaでの大量データ処理がKubernetesで簡単にできて嬉しかった話
by
MicroAd, Inc.(Engineer)
PDF
Chromeの3rd Party Cookie廃止とインターネット広告への影響
by
MicroAd, Inc.(Engineer)
PDF
ベアメタルで実現するSpark&Trino on K8sなデータ基盤
by
MicroAd, Inc.(Engineer)
PDF
DDD&Scalaで作られたプロダクトはその後どうなったか?(Current state of products made with DDD & Scala)
by
MicroAd, Inc.(Engineer)
PDF
InternetWeek2022 - インターネット広告の羅針盤
by
MicroAd, Inc.(Engineer)
PDF
マイクロアドにおけるデータストアの使い分け
by
MicroAd, Inc.(Engineer)
PDF
データセンターネットワークの構成について
by
MicroAd, Inc.(Engineer)
PDF
インフラ領域の技術スタックや業務内容について紹介
by
MicroAd, Inc.(Engineer)
PDF
RTBにおける機械学習の活用事例
by
MicroAd, Inc.(Engineer)
PDF
アドテクを支える基盤 〜10Tバイト/日のビッグデータを処理する〜
by
MicroAd, Inc.(Engineer)
PDF
アドテクに機械学習を組み込むための推論の高速化
by
MicroAd, Inc.(Engineer)
PDF
アドテクを支える技術 〜1日40億リクエストを捌くには〜
by
MicroAd, Inc.(Engineer)
PDF
RTBにおける機械学習の活用事例
by
MicroAd, Inc.(Engineer)
PDF
社内問い合わせ&申請・承認業務の 管理方法 - Jira Service Management 事例紹介 -
by
MicroAd, Inc.(Engineer)
PDF
Digdagを用いた大規模広告配信ログデータの加工と運用
by
MicroAd, Inc.(Engineer)
PDF
これから機械学習エンジニアとして戦っていくみなさんへ ~MLOps というマインドセットについて~
by
MicroAd, Inc.(Engineer)
PDF
インターネット広告の概要とシステム設計
by
MicroAd, Inc.(Engineer)
PDF
Cumulus Linuxを導入したワケ
by
MicroAd, Inc.(Engineer)
20240229 DEIM2024 【技術報告】広告配信における安定して拡張性のある大量データ処理基盤の必要性と活用
by
MicroAd, Inc.(Engineer)
Kafka Connect:Iceberg Sink Connectorを使ってみる
by
MicroAd, Inc.(Engineer)
Apache Kafkaでの大量データ処理がKubernetesで簡単にできて嬉しかった話
by
MicroAd, Inc.(Engineer)
Chromeの3rd Party Cookie廃止とインターネット広告への影響
by
MicroAd, Inc.(Engineer)
ベアメタルで実現するSpark&Trino on K8sなデータ基盤
by
MicroAd, Inc.(Engineer)
DDD&Scalaで作られたプロダクトはその後どうなったか?(Current state of products made with DDD & Scala)
by
MicroAd, Inc.(Engineer)
InternetWeek2022 - インターネット広告の羅針盤
by
MicroAd, Inc.(Engineer)
マイクロアドにおけるデータストアの使い分け
by
MicroAd, Inc.(Engineer)
データセンターネットワークの構成について
by
MicroAd, Inc.(Engineer)
インフラ領域の技術スタックや業務内容について紹介
by
MicroAd, Inc.(Engineer)
RTBにおける機械学習の活用事例
by
MicroAd, Inc.(Engineer)
アドテクを支える基盤 〜10Tバイト/日のビッグデータを処理する〜
by
MicroAd, Inc.(Engineer)
アドテクに機械学習を組み込むための推論の高速化
by
MicroAd, Inc.(Engineer)
アドテクを支える技術 〜1日40億リクエストを捌くには〜
by
MicroAd, Inc.(Engineer)
RTBにおける機械学習の活用事例
by
MicroAd, Inc.(Engineer)
社内問い合わせ&申請・承認業務の 管理方法 - Jira Service Management 事例紹介 -
by
MicroAd, Inc.(Engineer)
Digdagを用いた大規模広告配信ログデータの加工と運用
by
MicroAd, Inc.(Engineer)
これから機械学習エンジニアとして戦っていくみなさんへ ~MLOps というマインドセットについて~
by
MicroAd, Inc.(Engineer)
インターネット広告の概要とシステム設計
by
MicroAd, Inc.(Engineer)
Cumulus Linuxを導入したワケ
by
MicroAd, Inc.(Engineer)
アドテクに携わって培った アプリをハイパフォーマンスに保つ設計とコーディング
1.
アドテクに携わって培った アプリをハイパフォーマンス に保つ設計とコーディング 株式会社マイクロアド 松宮 康二 (まっつー) Developers
Boost 2019
2.
自己紹介 ● 名前: 松宮
康二(まっつー) ● 最近触ってるもの ● 仕事 ○ 新卒4年目 ○ アドテク系サーバサイドエンジニア ○ DSP開発チームのリーダー ● 最近の趣味 ○ ラーメン作り ● Twitter ○ @mattsu6666 2
3.
もくじ ● 広告配信システムの宿命 ※色々用語が出てきますが、そんなに重要ではないのでご安心下さい ●
オンメモリ戦略 ● リアルタイムなデータにはRedis ● アクターによる処理の分離 ● まとめ 3
4.
4 広告配信システムの宿命
5.
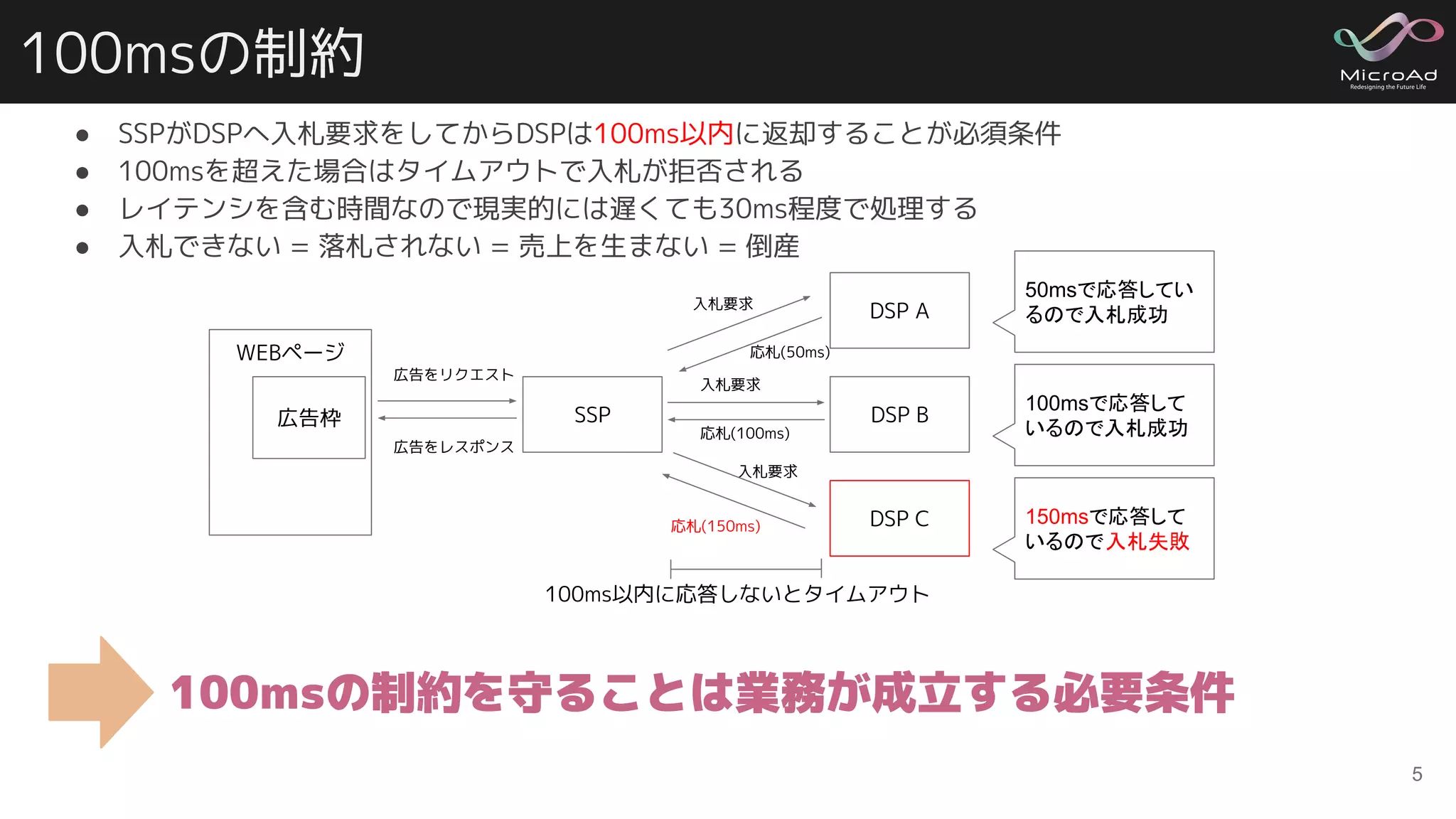
100msの制約 ● SSPがDSPへ入札要求をしてからDSPは100ms以内に返却することが必須条件 ● 100msを超えた場合はタイムアウトで入札が拒否される ●
レイテンシを含む時間なので現実的には遅くても30ms程度で処理する ● 入札できない = 落札されない = 売上を生まない = 倒産 5 100msの制約を守ることは業務が成立する必要条件 SSP DSP A DSP B DSP C WEBページ 広告枠 入札要求 100ms以内に応答しないとタイムアウト 応札(50ms) 広告をリクエスト 広告をレスポンス 応札(100ms) 応札(150ms) 入札要求 入札要求 50msで応答してい るので入札成功 100msで応答して いるので入札成功 150msで応答して いるので入札失敗
6.
1つのエンドポイントに全ての機能が詰まっている ● 一般的なWebアプリ等と異なり、エンドポイントはSSP毎に1つだけ ○ (設計次第だが)マイクロアドではSSP毎にエンドポイントを分けている ○
そのため、1つのAPIに対して機能追加し続けるイメージ ● ビジネスのスケールとともに機能は増え続ける ● 機能が増えても100msの制約は不変 ● しかし機能追加は避けては通れない 6 機能追加は業務を継続する必要条件 SSP A DSP 入札要求 POST /rtb/a SSP B 入札要求 POST /rtb/b SSP C 入札要求 POST /rtb/c 位置情報を使う機能 ユーザの性別とか判定する機能 ユーザと似たユーザを検索する機能 行動履歴を使う機能 ブラックリストユーザ判定機能 ヽ(・ω・ヽ*) PDM オフライン購買データを使う機能 新機能追加して! RTBの内部処理 ・・・ 機能追加をすればする程、RTBの内部処理は 複雑かつ高負荷になっていく。
7.
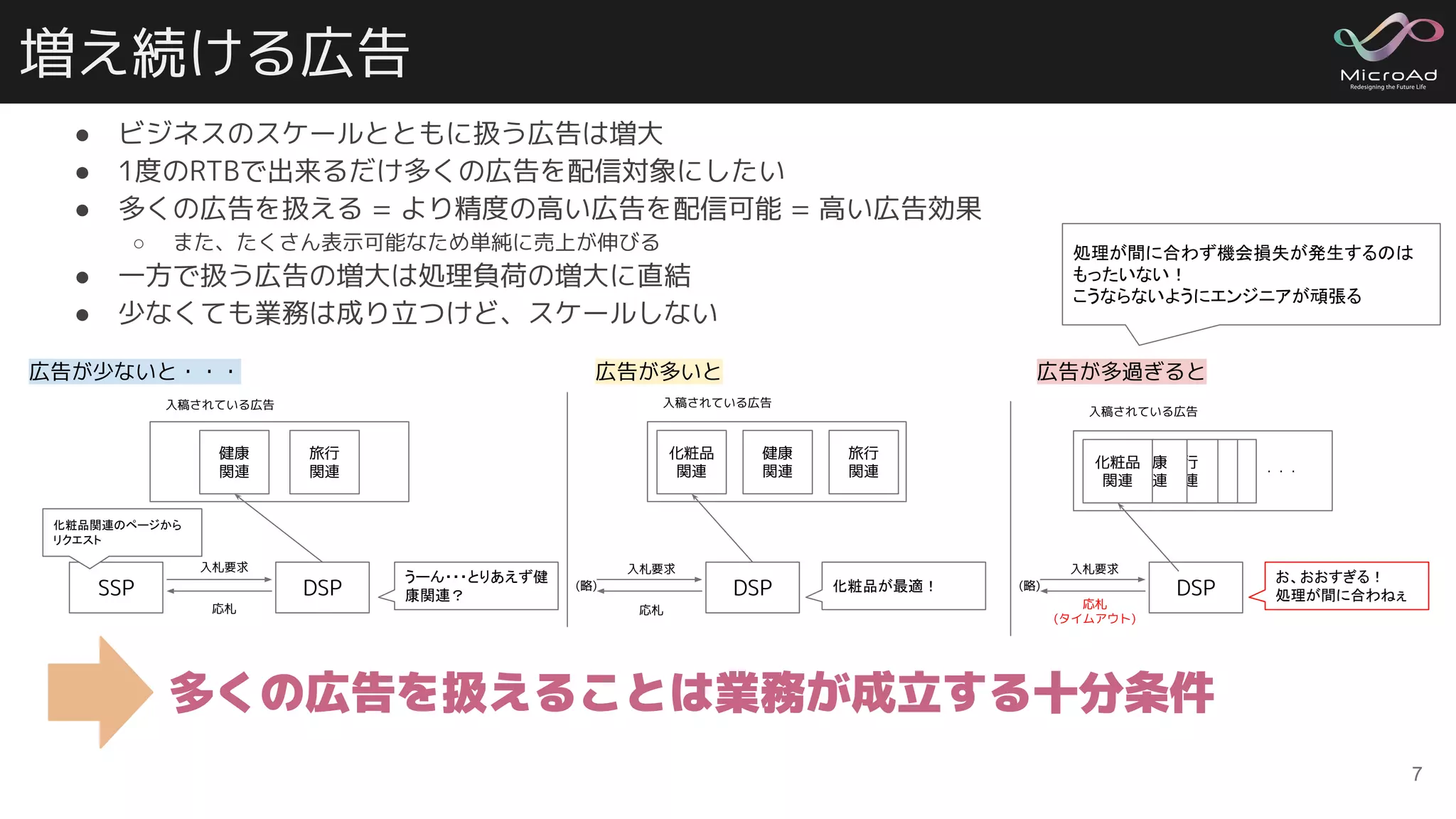
増え続ける広告 ● ビジネスのスケールとともに扱う広告は増大 ● 1度のRTBで出来るだけ多くの広告を配信対象にしたい ●
多くの広告を扱える = より精度の高い広告を配信可能 = 高い広告効果 ○ また、たくさん表示可能なため単純に売上が伸びる ● 一方で扱う広告の増大は処理負荷の増大に直結 ● 少なくても業務は成り立つけど、スケールしない 7 多くの広告を扱えることは業務が成立する十分条件 SSP DSP 入札要求 応札 化粧品関連のページから リクエスト うーん・・・とりあえず健 康関連? DSP 化粧品が最適!(略) 入札要求 応札 DSP(略) 入札要求 応札 (タイムアウト) 化粧品 関連 健康 関連 旅行 関連 健康 関連 旅行 関連 入稿されている広告 旅行 関連 健康 関連 化粧品 関連 ・・・ お、おおすぎる! 処理が間に合わねぇ 広告が少ないと・・・ 広告が多いと 広告が多過ぎると 処理が間に合わず機会損失が発生するのは もったいない! こうならないようにエンジニアが頑張る 入稿されている広告 入稿されている広告
8.
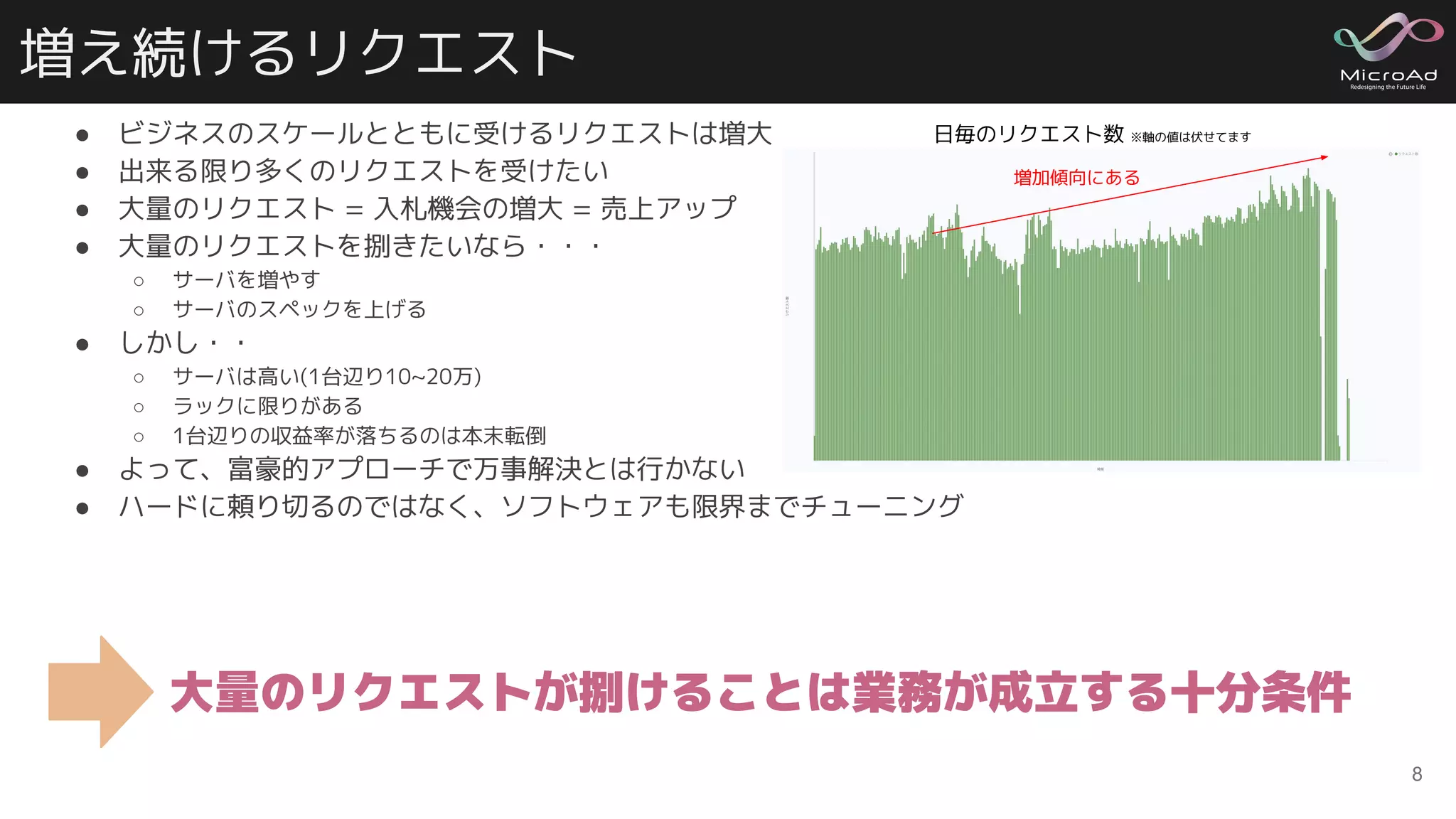
増え続けるリクエスト ● ビジネスのスケールとともに受けるリクエストは増大 ● 出来る限り多くのリクエストを受けたい ●
大量のリクエスト = 入札機会の増大 = 売上アップ ● 大量のリクエストを捌きたいなら・・・ ○ サーバを増やす ○ サーバのスペックを上げる ● しかし・・ ○ サーバは高い(1台辺り10~20万) ○ ラックに限りがある ○ 1台辺りの収益率が落ちるのは本末転倒 ● よって、富豪的アプローチで万事解決とは行かない ● ハードに頼り切るのではなく、ソフトウェアも限界までチューニング 8 大量のリクエストが捌けることは業務が成立する十分条件 日毎のリクエスト数 ※軸の値は伏せてます 増加傾向にある
9.
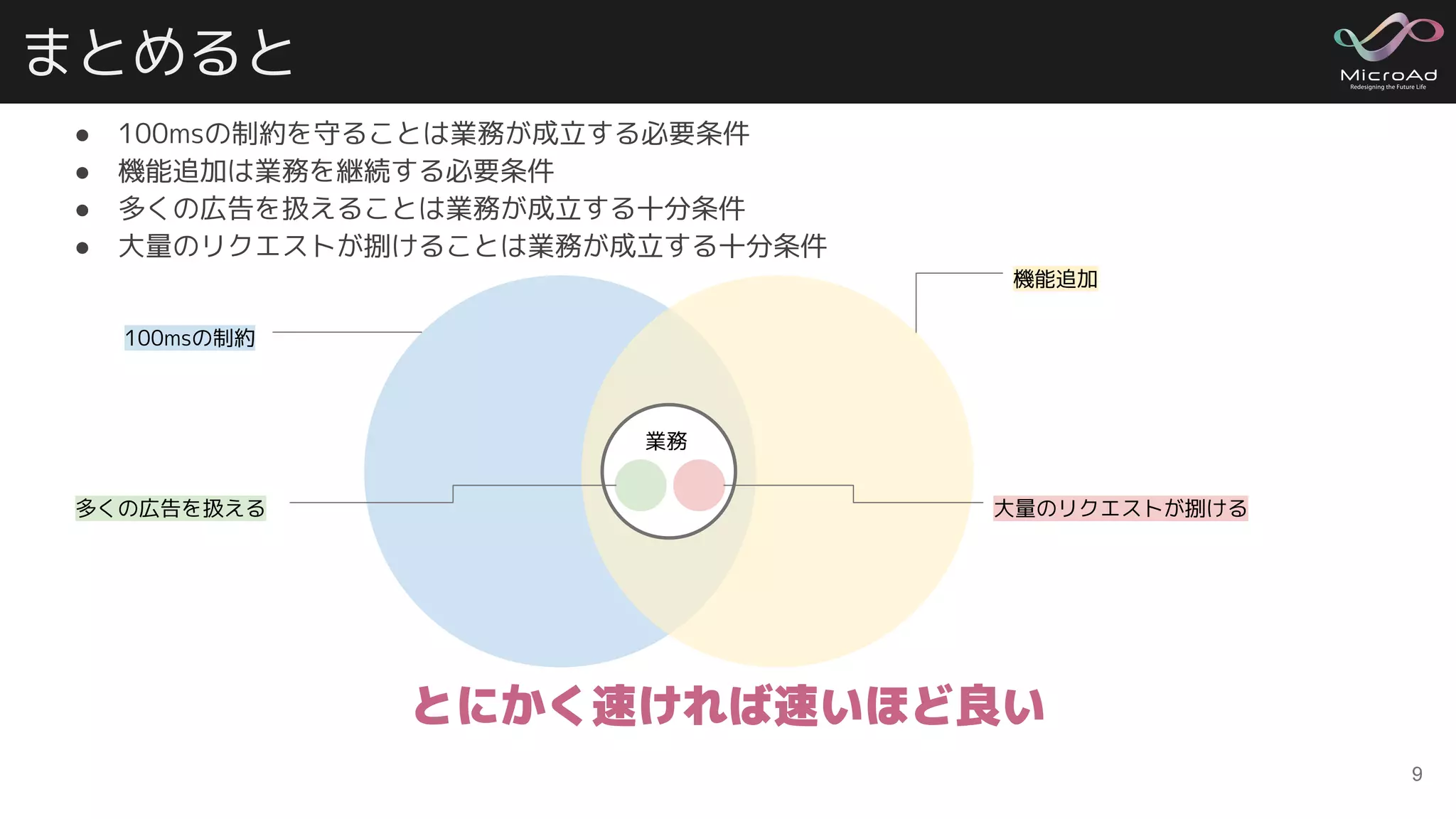
まとめると ● 100msの制約を守ることは業務が成立する必要条件 ● 機能追加は業務を継続する必要条件 ●
多くの広告を扱えることは業務が成立する十分条件 ● 大量のリクエストが捌けることは業務が成立する十分条件 9 とにかく速ければ速いほど良い 100msの制約 機能追加 多くの広告を扱える 大量のリクエストが捌ける 業務
10.
10 オンメモリ戦略とIO
11.
オンメモリ戦略 ● アプリケーションのボトルネックの大部分はI/O ○ RTT ○
記憶装置へのランダムアクセス ● 載せれるデータはローカルのメモリ上に持てるだけ持つ ○ いわゆるオンメモリ戦略 ● オンメモリ化の条件 ○ ある程度の更新間隔を許容(数分~数十分は古くても良い) ○ 件数が膨大過ぎない(メモリに載る容量か) ○ 揮発しても良いデータ(もしくは、どこかで永続化されている) ● 以上の条件を満たせばメモリに載せる ● 単純な戦略だが最も効果的 ● ただし、メモリには限界があるので無敵ではない 11 アプリ DB キャッシュ 定期的にDBのデータをキャッシュ アプリ DB 毎回DBに問い合わせるので遅い 常に最新のデータを取得できるが、 本当にその必要がある? 速度を犠牲にしてまで最新データにこだわるべき か? 最新のデータは使えないが、ローカルのメモリに キャッシュするので高速。 ただし、データの容量等の様々な制限はある 引用: https://people.eecs.berkeley.edu/~rcs/research/interactive_latency.html メインメモリの参照は100ns SSDのランダムアクセスは16μs ≒ 16000ns 単純計算で160倍の速度差 さらに、ネットワークのレイテンシを考えればオン メモリ化が如何に効果的かわかる
12.
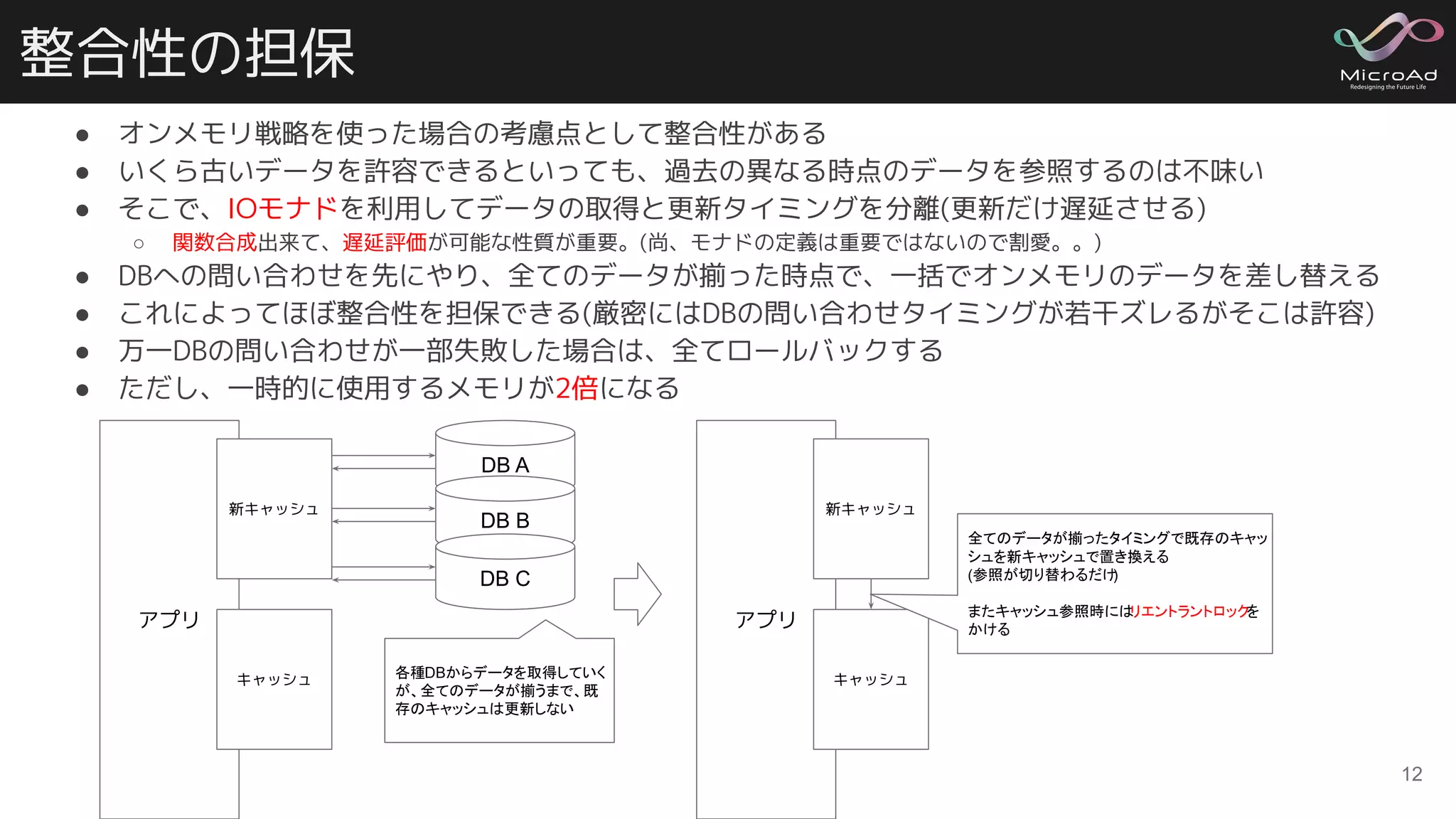
整合性の担保 ● オンメモリ戦略を使った場合の考慮点として整合性がある ● いくら古いデータを許容できるといっても、過去の異なる時点のデータを参照するのは不味い ●
そこで、IOモナドを利用してデータの取得と更新タイミングを分離(更新だけ遅延させる) ○ 関数合成出来て、遅延評価が可能な性質が重要。(尚、モナドの定義は重要ではないので割愛。。) ● DBへの問い合わせを先にやり、全てのデータが揃った時点で、一括でオンメモリのデータを差し替える ● これによってほぼ整合性を担保できる(厳密にはDBの問い合わせタイミングが若干ズレるがそこは許容) ● 万一DBの問い合わせが一部失敗した場合は、全てロールバックする ● ただし、一時的に使用するメモリが2倍になる 12 アプリ DB A 新キャッシュ DB B DB C キャッシュ アプリ 新キャッシュ キャッシュ各種DBからデータを取得していく が、全てのデータが揃うまで、既 存のキャッシュは更新しない 全てのデータが揃ったタイミングで既存のキャッ シュを新キャッシュで置き換える (参照が切り替わるだけ) またキャッシュ参照時にはリエントラントロックを かける
13.
IOを使った実装例の前に、RepositoryとDao ● オンメモリ戦略を実装する上でRepositoryとDaoを明確に区別するようにした ○ RepositoryとはDDD文脈での用語のこと。 ●
Repositoryはクライアントから参照され、クライアント都合のクラス ○ クライアントはRedisを参照しているのか、MySQLを参照しているのか、メモリを参照しているかは気にしない ● Daoはデータベースを参照し、データベース都合のクラス ○ クライアントの都合に左右され辛い ● 利用例としては以下のパターンに分類している 13 - RepositoryAはDaoを持っている。 Daoから取得したデータを加工してクライア ントに返すケースで有効 - RepositoryBはフィールドを持つ。 オンメモリ化するケースで使う - RepositoryCは実装がDao。 取得したデータをそのままクライアントが使 えるようなケースで有効 RepositoryとDaoとClientの関係
14.
IOを使った実装例 ● 定期的にキャッシュを更新する機能(Loaderと呼んでいる)によってDaoからロードしたデータを Repositoryに反映する ● IOを使うことでロードのタイミングと反映のタイミングを分離 14 class
UserLoader( userDao: UserDao, ageDao: AgeDao, userRepository: UserRepository ) { def load(dependency: Dependency): Either[Throwable, IO[Unit]] = { for { r1 <- userDao.find(dependency) r2 <- ageDao.find(dependency) state = buildFrom(r1, r2) } yield IO { userRepository.update(state) } } toEither } class Loader( userLoader: UserLoader, hogeLoader: HogeLoader ) { def load(dependency: Dependency): Either[Throwable, IO[Unit]] = { for { userIO <- userLoader.load(dependency) hogeIO <- hogeLoader.load(dependency) } yield userIO append hogeIO } } LoaderはDaoから取得したデータをRepositoryへ反映する 複数のIOをappendによって一つのIOにまとめていく 言語はScalaです
15.
IOを使った実装例 ● Daoを使ってDBからデータを取得する 15 class UserLoader( userDao:
UserDao, ageDao: AgeDao, userRepository: UserRepository ) { def load(dependency: Dependency): Either[Throwable, IO[Unit]] = { for { r1 <- userDao.find(dependency) r2 <- ageDao.find(dependency) state = buildFrom(r1, r2) } yield IO { userRepository.update(state) } } toEither } class Loader( userLoader: UserLoader, hogeLoader: HogeLoader ) { def load(dependency: Dependency): Either[Throwable, IO[Unit]] = { for { userIO <- userLoader.load(dependency) hogeIO <- hogeLoader.load(dependency) } yield userIO append hogeIO } } LoaderはDaoから取得したデータをRepositoryへ反映する 複数のIOをappendによって一つのIOにまとめていく
16.
IOを使った実装例 ● 取得したデータを加工 16 class UserLoader( userDao:
UserDao, ageDao: AgeDao, userRepository: UserRepository ) { def load(dependency: Dependency): Either[Throwable, IO[Unit]] = { for { r1 <- userDao.find(dependency) r2 <- ageDao.find(dependency) state = buildFrom(r1, r2) } yield IO { userRepository.update(state) } } toEither } class Loader( userLoader: UserLoader, hogeLoader: HogeLoader ) { def load(dependency: Dependency): Either[Throwable, IO[Unit]] = { for { userIO <- userLoader.load(dependency) hogeIO <- hogeLoader.load(dependency) } yield userIO append hogeIO } } LoaderはDaoから取得したデータをRepositoryへ反映する 複数のIOをappendによって一つのIOにまとめていく
17.
IOを使った実装例 ● IOを生成し、ブロック内でUserRepositoryを更新する ● ただし、IOに囲まれているので遅延評価される 17 class
UserLoader( userDao: UserDao, ageDao: AgeDao, userRepository: UserRepository ) { def load(dependency: Dependency): Either[Throwable, IO[Unit]] = { for { r1 <- userDao.find(dependency) r2 <- ageDao.find(dependency) state = buildFrom(r1, r2) } yield IO { userRepository.update(state) } } toEither } class Loader( userLoader: UserLoader, hogeLoader: HogeLoader ) { def load(dependency: Dependency): Either[Throwable, IO[Unit]] = { for { userIO <- userLoader.load(dependency) hogeIO <- hogeLoader.load(dependency) } yield userIO append hogeIO } } LoaderはDaoから取得したデータをRepositoryへ反映する 複数のIOをappendによって一つのIOにまとめていく
18.
IOを使った実装例 ● 複数のLoaderからIOの結果を得る 18 class UserLoader( userDao:
UserDao, ageDao: AgeDao, userRepository: UserRepository ) { def load(dependency: Dependency): Either[Throwable, IO[Unit]] = { for { r1 <- userDao.find(dependency) r2 <- ageDao.find(dependency) state = buildFrom(r1, r2) } yield IO { userRepository.update(state) } } toEither } class Loader( userLoader: UserLoader, hogeLoader: HogeLoader ) { def load(dependency: Dependency): Either[Throwable, IO[Unit]] = { for { userIO <- userLoader.load(dependency) hogeIO <- hogeLoader.load(dependency) } yield userIO append hogeIO } } LoaderはDaoから取得したデータをRepositoryへ反映する 複数のIOをappendによって一つのIOにまとめていく
19.
IOを使った実装例 ● 複数のIOを合成したIOを返す ● IOを実行すれば、合成したIOは全て実行される ○
つまりRepositoryのupdateが実行される 19 class UserLoader( userDao: UserDao, ageDao: AgeDao, userRepository: UserRepository ) { def load(dependency: Dependency): Either[Throwable, IO[Unit]] = { for { r1 <- userDao.find(dependency) r2 <- ageDao.find(dependency) state = buildFrom(r1, r2) } yield IO { userRepository.update(state) } } toEither } class Loader( userLoader: UserLoader, hogeLoader: HogeLoader ) { def load(dependency: Dependency): Either[Throwable, IO[Unit]] = { for { userIO <- userLoader.load(dependency) hogeIO <- hogeLoader.load(dependency) } yield userIO append hogeIO } } LoaderはDaoから取得したデータをRepositoryへ反映する 複数のIOをappendによって一つのIOにまとめていく 整合性の問題をほぼクリア!
20.
20 リアルタイムなデータにはRedis
21.
リアルタイムなデータはインメモリデータベース ● オンメモリ戦略を適用できないデータはどうするか? ○ リアルタイム性が求められるデータ ○
ローカルのメモリには乗り切らないデータ ● リモートホストのインメモリデータベースにキャッシュする ○ 通信は発生するがデータは高速で読める ○ マイクロアドでは主にRedisを利用 (NoSQLの一つ、KVSとも) ● データが巨大過ぎる場合はRedis Clusterを利用。 ● 出来るだけ多くのデータを保持するためにMessagePackを使ってシリアライズ ● Redisの場合はString型(Key/Value形式)以外にHash型、List型、Set型などの型がサポートされている 21 user1_action1 user1_action2 user1_action3 user2_action1 user2_action2 http://aaa.com http://bbb.com http://ccc.com http://aaa.com http://bbb.com key value user1 user2 http://aaa.com http://bbb.com http://ccc.com http://aaa.com http://bbb.com key value action1 action2 action3 field action1 action2 String型 Hash型 キーを単純にし、検索性能を改善できる場合がある
22.
メモリ節約!MessagePackでシリアライズ ● 複雑なデータをRedisに入れたいけど、メモリは節約したいケースに利用 ● MessagePackはバイナリ形式のデータフォーマット ●
JSONのようにkey/value形式(map型)で保持できる (他にもbool, int, float, arrayなどがある) ● シリアライズ後のサイズはJSONより小さくなる (適切な型を使えば) ○ ただし、バイナリなので目で見て理解は難しい ● 人が見るデータではなくシステムが参照するデータなので可読性は気にする必要がない 22 引用: https://msgpack.org/ja.html val objectMapper = new ObjectMapper(new MessagePackFactory()) objectMapper.registerModule(DefaultScalaModule) @JsonIgnoreProperties(ignoreUnknown = true) case class Record(compact: Boolean, schema: Int) JSONよりサイズが小さくなる仕組み (公式サイトより) ObjectMapperで簡単にデシリアライズ出来て便利
23.
独自フォーマットを作ってた時期もありました ● MessagePackよりもっと容量削減したフォーマットを作れるのでは? ○ 実際、昔は独自フォーマットを使っていた ●
独自フォーマットを使うとより小さいサイズで同じデータを表現可能かもしれないが・・・ ○ シリアライザ、デシリアライザをいちいち実装する必要があったり、フォーマット仕様をメンテしないといけなかったり、仕様 変更に強いフォーマットでないとメンテが辛かったり、ツール類を独自で開発したりetc... ● とにかくメンテナンスのコストが増えていく ● よほどの事が無ければ、広く一般的に使われているフォーマットを選ぶのがベターだと思います。 23 ユーザID ユーザ名バージョン 1byte 8byte 1~n byte ユーザID 年齢 ユーザ名バージョン 1byte 8byte 1byte 1~n byte private def decodeV1(value: Array[Byte]): User = { val buffer = ByteBuffer(value).order(ByteOrder.LITTLE_ENDIAN) buffer.byte // 最初の1バイトはバージョンのため,飛ばす User( buffer.long, // ユーザID new String(buffer.bytes(a.readableBytes)) // ユーザ名 ) } バージョン管理したり、 クライアントのコードを修正する必要があった 複数バージョンが混在して実装がゴチャゴチャすることも・・ 年齢追加前の実装例。バージョンが上がれば改修が必要 仕様変更で年齢が追加された! 独自フォーマットの例
24.
24 アクターによる処理の分離
25.
アクターモデル ● アクターはメッセージ駆動の計算実体(スレッドに似ている) ○ アクターは非同期に実行される ●
アクター同士が協調して1つのアプリケーションを構成する ● アトミックやロックを使わず、安全に並行並列処理が実装できる ○ アクターはメールボックス(メッセージキューみたいな)を持っていて、1度に1つ処理 ● アクターはfire-and-forget(撃ちっぱなし)の性質によって、非同期処理を実現している ● スケーラビリティのためにアクター同士は疎結合になっている ○ 空間/位置: 位置透過性とも。同じノード、異なるノード等、どこにアクターがいても良い ○ 時間: アクターはタスクの完了について何も保証しないし、期待もしない ○ インターフェース: アクター同士は何も共有しない。インタフェースが正しいかとか関係ない 25 Actor Actor Actor メッセージ送信 メッセージ送信 メッセージ送信 アクターシステム メールボックス (メッセージキュー) アクターは非同期で動作するのでア クターの数だけ並行並列に動作可 能 ロックとかアトミックな操作は一切不 要 メッセージを受信し て何か処理
26.
アクターモデルを使った処理の分離 ● 広告配信システムの本領は広告を配信すること ○ しかし、それ以外にも色々やっている(ログの書き出し,
DBの更新, 他サービスとの連携等) ● 例えば、出来る限り高速に応答したいが、ログの書き出しは多少遅くても良い ● 本質でない処理にCPUのリソースを割くのは勿体ない。そこでアクターモデルを活用 ○ fire-and-forgetの性質によって応答を待つ必要はない ○ アクターは位置透過性なのでログの書き出しはリモートホストで処理してもいい ● ただし、メッセージが到達する信頼性は「at-most-once」 ○ つまり、メッセージは喪失する可能性があるので重要なメッセージは送れない ○ at-least-onceを保証する方法も一応可能。ただアクターモデルの旨味が消える 26 RTB処理はログ記録の応答を一切待たないの でログ記録の影響を受けない ログ記録がリモートホストに存在する場合、ログ は喪失する可能性がある ログの重要度によって、対応方法を変える必要 がある ←ログが消滅!!! 重要なログだったらヤバイ・・・
27.
ログのためにデータを保持する必要がない ● アクターモデルを使うとRTBの本質でない処理をメッセージを介して異なるシステムに分離可能 ● これにより、本質でないデータを保持する必要がなくなる ●
従来の方法だとログ用のデータを保持するフィールドやクラスが必要があったが、その必要がない 27 処理A 処理B 処理C ログ記録 処理Aで残 したい情報 処理Bで残 したい情報処理Bで残 したい情報 処理Bで残 したい情報処理Bで残 したい情報処理Cで残 したい情報 処理A 処理B 処理C ログ記録 処理Aで残 したい情報 処理Bで残 したい情報 処理Cで残 したい情報 メッセージ送信 ログ記録の 引数に渡す 従来の方法だとログを記録する直前まで必要なデータを保持 アクターを使った場合は必要なデータを保持しない
28.
まとめ ● なぜ広告配信システムで性能が求められるかを説明した ○ 100msの制約、機能追加は必要条件 ○
多くの広告を扱える、大量のリクエストが捌けることは十分条件 ● オンメモリ戦略 ○ アプリケーションのボトルネックの大部分はI/O ○ オンメモリ戦略は効果的だが、いくつかの条件がある ○ 完璧に整合性を担保するのが難しい ● リアルタイムなデータにはRedis ○ オンメモリ戦略を適用できない場合はインメモリデータベースを活用 ○ 適切な型を使い検索に特化した設計にする ○ メモリを出来る限り節約するためにMessagePackを利用 ● アクターによる処理の分離 ○ アクターモデルを活用したログ処理の分離 28
29.
29 実はまだまだ課題があります・・・ - 定期的な更新ではなくイベント駆動による更新をしたい - 更新時/参照時にロックをかけているが、 異なるタイミングで参照するデータがあるため、たまに不整合が・・ -
リモートアクターを使うとメッセージが喪失する可能性があって困るetc...
30.
We Are Hiring!! 30 マイクロアドでは、広告配信システムを一緒に作りたい人を 募集しています! https://recruit.microad.co.jp/ 公式アカウント
@microad_dev もよろしくお願いします。
31.
31 ご清聴ありがとうございました!
Download







![IOを使った実装例
● 定期的にキャッシュを更新する機能(Loaderと呼んでいる)によってDaoからロードしたデータを
Repositoryに反映する
● IOを使うことでロードのタイミングと反映のタイミングを分離
14
class UserLoader(
userDao: UserDao,
ageDao: AgeDao,
userRepository: UserRepository
) {
def load(dependency: Dependency): Either[Throwable, IO[Unit]] = {
for {
r1 <- userDao.find(dependency)
r2 <- ageDao.find(dependency)
state = buildFrom(r1, r2)
} yield IO { userRepository.update(state) }
} toEither
}
class Loader(
userLoader: UserLoader,
hogeLoader: HogeLoader
) {
def load(dependency: Dependency): Either[Throwable, IO[Unit]] = {
for {
userIO <- userLoader.load(dependency)
hogeIO <- hogeLoader.load(dependency)
} yield
userIO append
hogeIO
}
}
LoaderはDaoから取得したデータをRepositoryへ反映する 複数のIOをappendによって一つのIOにまとめていく
言語はScalaです](https://image.slidesharecdn.com/adtechmattsudevst-191130042633/75/slide-14-2048.jpg)
![IOを使った実装例
● Daoを使ってDBからデータを取得する
15
class UserLoader(
userDao: UserDao,
ageDao: AgeDao,
userRepository: UserRepository
) {
def load(dependency: Dependency): Either[Throwable, IO[Unit]] = {
for {
r1 <- userDao.find(dependency)
r2 <- ageDao.find(dependency)
state = buildFrom(r1, r2)
} yield IO { userRepository.update(state) }
} toEither
}
class Loader(
userLoader: UserLoader,
hogeLoader: HogeLoader
) {
def load(dependency: Dependency): Either[Throwable, IO[Unit]] = {
for {
userIO <- userLoader.load(dependency)
hogeIO <- hogeLoader.load(dependency)
} yield
userIO append
hogeIO
}
}
LoaderはDaoから取得したデータをRepositoryへ反映する 複数のIOをappendによって一つのIOにまとめていく](https://image.slidesharecdn.com/adtechmattsudevst-191130042633/75/slide-15-2048.jpg)
![IOを使った実装例
● 取得したデータを加工
16
class UserLoader(
userDao: UserDao,
ageDao: AgeDao,
userRepository: UserRepository
) {
def load(dependency: Dependency): Either[Throwable, IO[Unit]] = {
for {
r1 <- userDao.find(dependency)
r2 <- ageDao.find(dependency)
state = buildFrom(r1, r2)
} yield IO { userRepository.update(state) }
} toEither
}
class Loader(
userLoader: UserLoader,
hogeLoader: HogeLoader
) {
def load(dependency: Dependency): Either[Throwable, IO[Unit]] = {
for {
userIO <- userLoader.load(dependency)
hogeIO <- hogeLoader.load(dependency)
} yield
userIO append
hogeIO
}
}
LoaderはDaoから取得したデータをRepositoryへ反映する 複数のIOをappendによって一つのIOにまとめていく](https://image.slidesharecdn.com/adtechmattsudevst-191130042633/75/slide-16-2048.jpg)
![IOを使った実装例
● IOを生成し、ブロック内でUserRepositoryを更新する
● ただし、IOに囲まれているので遅延評価される
17
class UserLoader(
userDao: UserDao,
ageDao: AgeDao,
userRepository: UserRepository
) {
def load(dependency: Dependency): Either[Throwable, IO[Unit]] = {
for {
r1 <- userDao.find(dependency)
r2 <- ageDao.find(dependency)
state = buildFrom(r1, r2)
} yield IO { userRepository.update(state) }
} toEither
}
class Loader(
userLoader: UserLoader,
hogeLoader: HogeLoader
) {
def load(dependency: Dependency): Either[Throwable, IO[Unit]] = {
for {
userIO <- userLoader.load(dependency)
hogeIO <- hogeLoader.load(dependency)
} yield
userIO append
hogeIO
}
}
LoaderはDaoから取得したデータをRepositoryへ反映する 複数のIOをappendによって一つのIOにまとめていく](https://image.slidesharecdn.com/adtechmattsudevst-191130042633/75/slide-17-2048.jpg)
![IOを使った実装例
● 複数のLoaderからIOの結果を得る
18
class UserLoader(
userDao: UserDao,
ageDao: AgeDao,
userRepository: UserRepository
) {
def load(dependency: Dependency): Either[Throwable, IO[Unit]] = {
for {
r1 <- userDao.find(dependency)
r2 <- ageDao.find(dependency)
state = buildFrom(r1, r2)
} yield IO { userRepository.update(state) }
} toEither
}
class Loader(
userLoader: UserLoader,
hogeLoader: HogeLoader
) {
def load(dependency: Dependency): Either[Throwable, IO[Unit]] = {
for {
userIO <- userLoader.load(dependency)
hogeIO <- hogeLoader.load(dependency)
} yield
userIO append
hogeIO
}
}
LoaderはDaoから取得したデータをRepositoryへ反映する 複数のIOをappendによって一つのIOにまとめていく](https://image.slidesharecdn.com/adtechmattsudevst-191130042633/75/slide-18-2048.jpg)
![IOを使った実装例
● 複数のIOを合成したIOを返す
● IOを実行すれば、合成したIOは全て実行される
○ つまりRepositoryのupdateが実行される
19
class UserLoader(
userDao: UserDao,
ageDao: AgeDao,
userRepository: UserRepository
) {
def load(dependency: Dependency): Either[Throwable, IO[Unit]] = {
for {
r1 <- userDao.find(dependency)
r2 <- ageDao.find(dependency)
state = buildFrom(r1, r2)
} yield IO { userRepository.update(state) }
} toEither
}
class Loader(
userLoader: UserLoader,
hogeLoader: HogeLoader
) {
def load(dependency: Dependency): Either[Throwable, IO[Unit]] = {
for {
userIO <- userLoader.load(dependency)
hogeIO <- hogeLoader.load(dependency)
} yield
userIO append
hogeIO
}
}
LoaderはDaoから取得したデータをRepositoryへ反映する 複数のIOをappendによって一つのIOにまとめていく
整合性の問題をほぼクリア!](https://image.slidesharecdn.com/adtechmattsudevst-191130042633/75/slide-19-2048.jpg)



![独自フォーマットを作ってた時期もありました
● MessagePackよりもっと容量削減したフォーマットを作れるのでは?
○ 実際、昔は独自フォーマットを使っていた
● 独自フォーマットを使うとより小さいサイズで同じデータを表現可能かもしれないが・・・
○ シリアライザ、デシリアライザをいちいち実装する必要があったり、フォーマット仕様をメンテしないといけなかったり、仕様
変更に強いフォーマットでないとメンテが辛かったり、ツール類を独自で開発したりetc...
● とにかくメンテナンスのコストが増えていく
● よほどの事が無ければ、広く一般的に使われているフォーマットを選ぶのがベターだと思います。
23
ユーザID ユーザ名バージョン
1byte 8byte 1~n byte
ユーザID 年齢 ユーザ名バージョン
1byte 8byte 1byte 1~n byte
private def decodeV1(value: Array[Byte]): User = {
val buffer = ByteBuffer(value).order(ByteOrder.LITTLE_ENDIAN)
buffer.byte // 最初の1バイトはバージョンのため,飛ばす
User(
buffer.long, // ユーザID
new String(buffer.bytes(a.readableBytes)) // ユーザ名
)
}
バージョン管理したり、
クライアントのコードを修正する必要があった
複数バージョンが混在して実装がゴチャゴチャすることも・・
年齢追加前の実装例。バージョンが上がれば改修が必要
仕様変更で年齢が追加された!
独自フォーマットの例](https://image.slidesharecdn.com/adtechmattsudevst-191130042633/75/slide-23-2048.jpg)












































































