Download as PDF, PPTX































![Example:
私は中路です。
よろしくお願いします。
[0.2, 0.3, ……0.2]
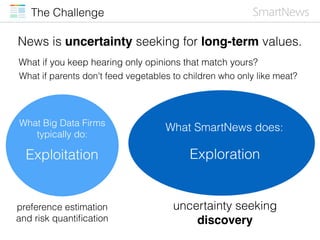
Will LeBron James deliver
an NBA championship to
Cleveland?
[0.1, 0.4, ……0.1]
Paragraph Vector
(dimension ∼ several 100)](https://image.slidesharecdn.com/smartnewsdocumentclassification-150428133649-conversion-gate02/85/SmartNews-Globally-Scalable-Web-Document-Classification-Using-Word2Vec-32-320.jpg)


![Word Vector in word2vec Model
Every word is mapped to unique word vector
with good properties.
[0.1, 0.2, ……0.2]=
[0.1, 0.1, ……-0.1]=
[0.3, 0.4, ……0]=
[0.3, 0.3, ……0.3]=
Germany Berlin
Paris
France
…
“Germany - Berlin = France - Paris”
vFrance
vParis
vGermany
vBerlin](https://image.slidesharecdn.com/smartnewsdocumentclassification-150428133649-conversion-gate02/85/SmartNews-Globally-Scalable-Web-Document-Classification-Using-Word2Vec-35-320.jpg)


![Example:
私は中路です。
よろしくお願いします。
[0.2, 0.3, ……0.2]
Will LeBron James deliver
an NBA championship to
Cleveland?
[0.1, 0.4, ……0.1]
Paragraph Vectors
(dimension ∼ 100s)](https://image.slidesharecdn.com/smartnewsdocumentclassification-150428133649-conversion-gate02/85/SmartNews-Globally-Scalable-Web-Document-Classification-Using-Word2Vec-38-320.jpg)


![Procedure to Create Paragraph Vector
Feature Extractor
[0.2, 0.3, ……0.2]
d
˜uw ˜vw
Paragraph Vector :
Lmaximize
Ldocmaximize](https://image.slidesharecdn.com/smartnewsdocumentclassification-150428133649-conversion-gate02/85/SmartNews-Globally-Scalable-Web-Document-Classification-Using-Word2Vec-41-320.jpg)
![Text Classification
Ordinary text classification architecture:
② live data
([0.1, -0.1, …])
① training
([0.1, 0.3, …], entertainment)
([0.2, -0.3, …], sports)
([0.1, 0.1, …], entertainment)
features
? ?
…
entertainment
sports
([0.1, -0.2, …], politics)
…
sports
training
algorithm
classifier
feature
extraction](https://image.slidesharecdn.com/smartnewsdocumentclassification-150428133649-conversion-gate02/85/SmartNews-Globally-Scalable-Web-Document-Classification-Using-Word2Vec-42-320.jpg)












The document discusses a machine learning approach for web document classification using techniques such as word2vec and paragraph vectors. It outlines the algorithm's structure, including content extraction and text classification, emphasizing scalability and precision, particularly for multilingual settings. The document also highlights the challenges of optimizing user engagement in news delivery and invites engineering talent to join the SmartNews team.
























































