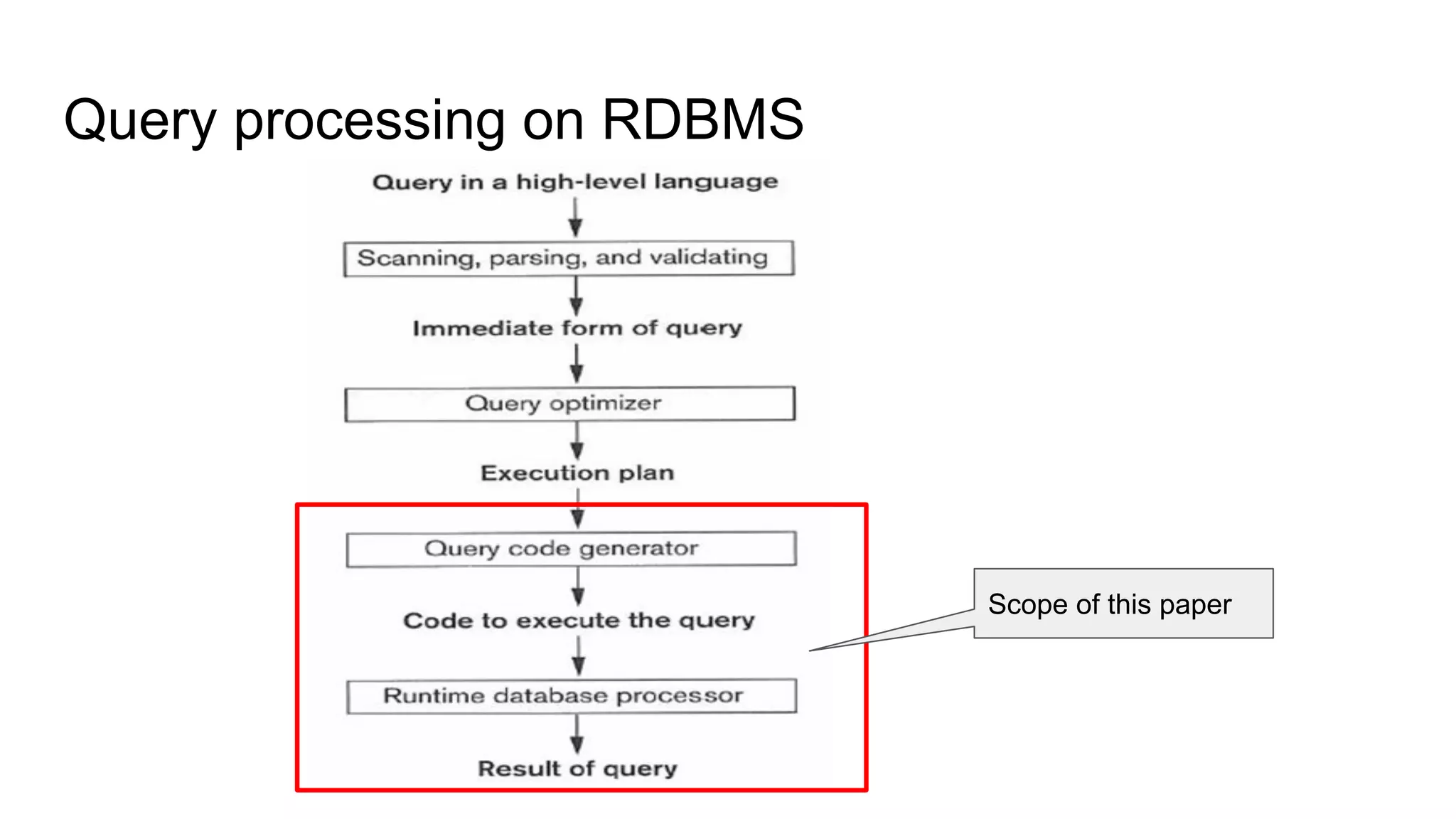
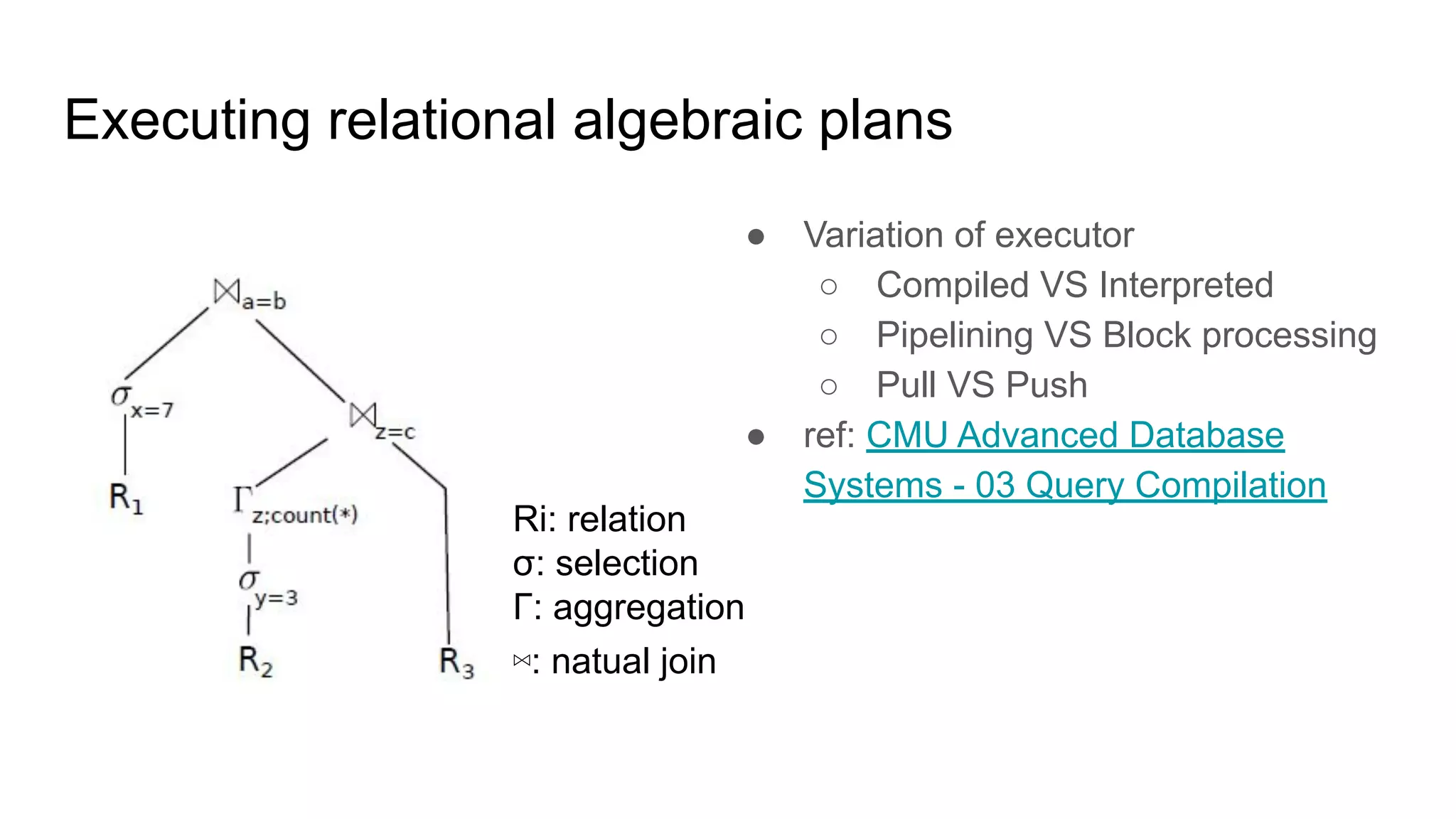
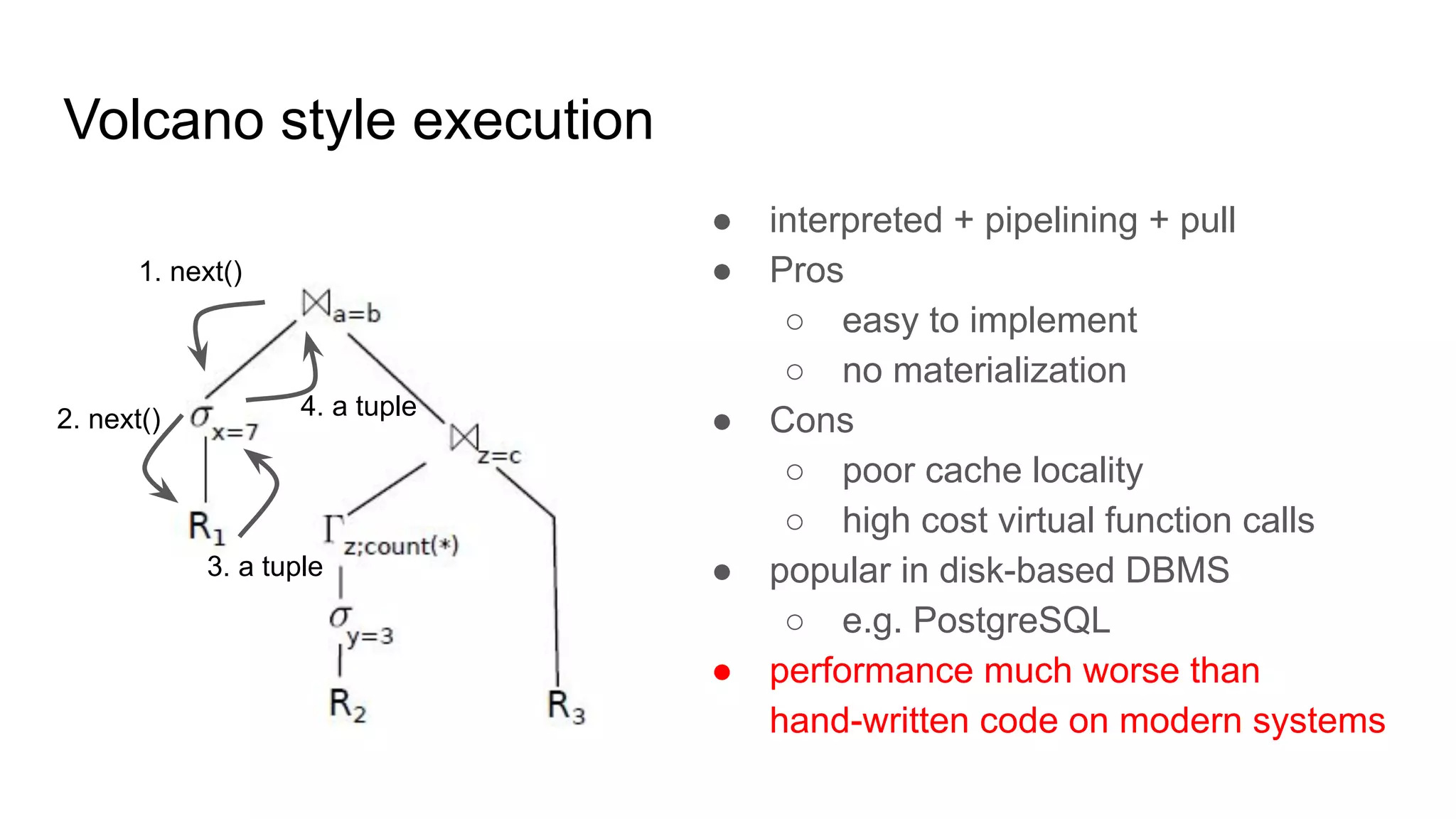
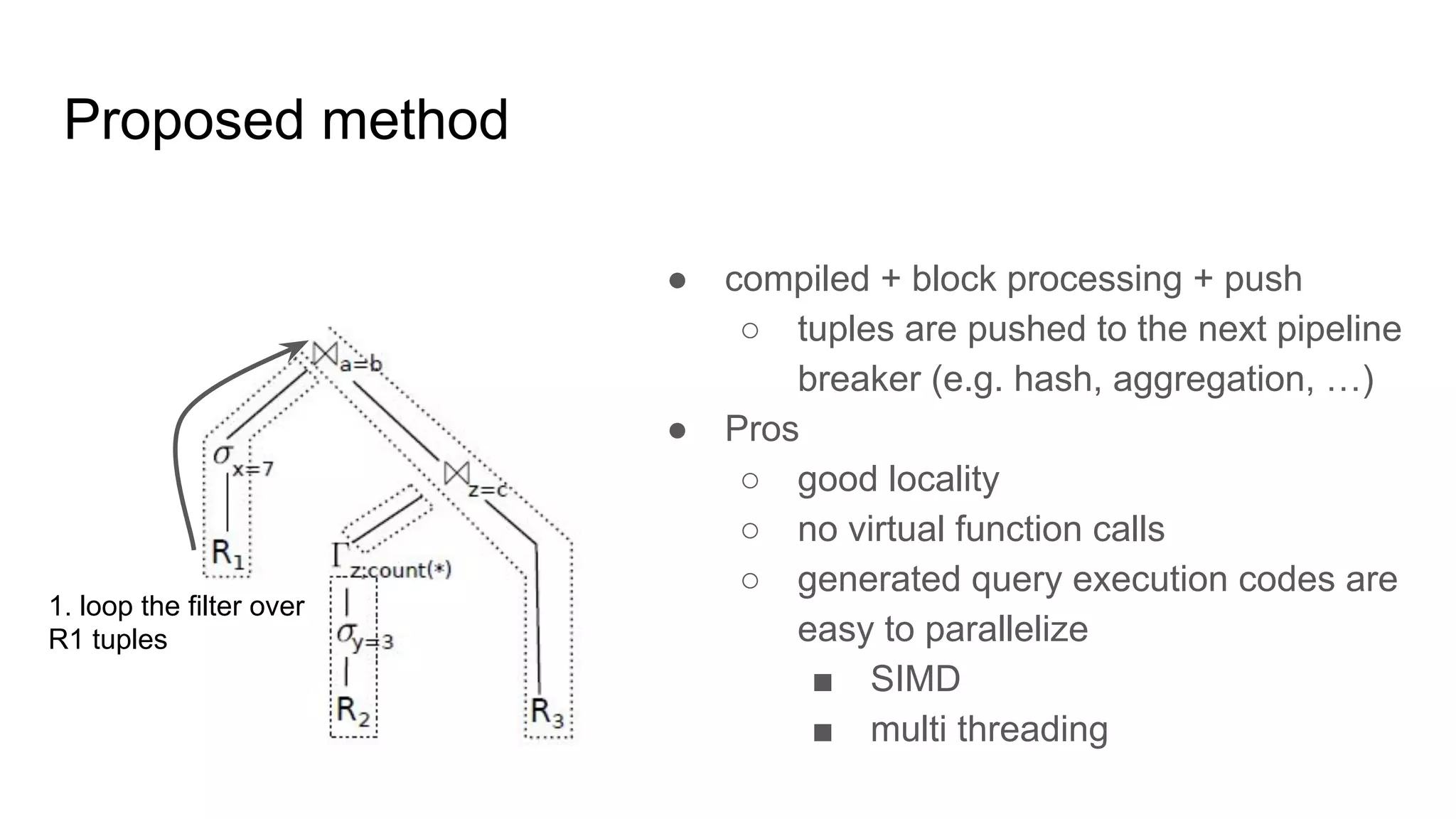
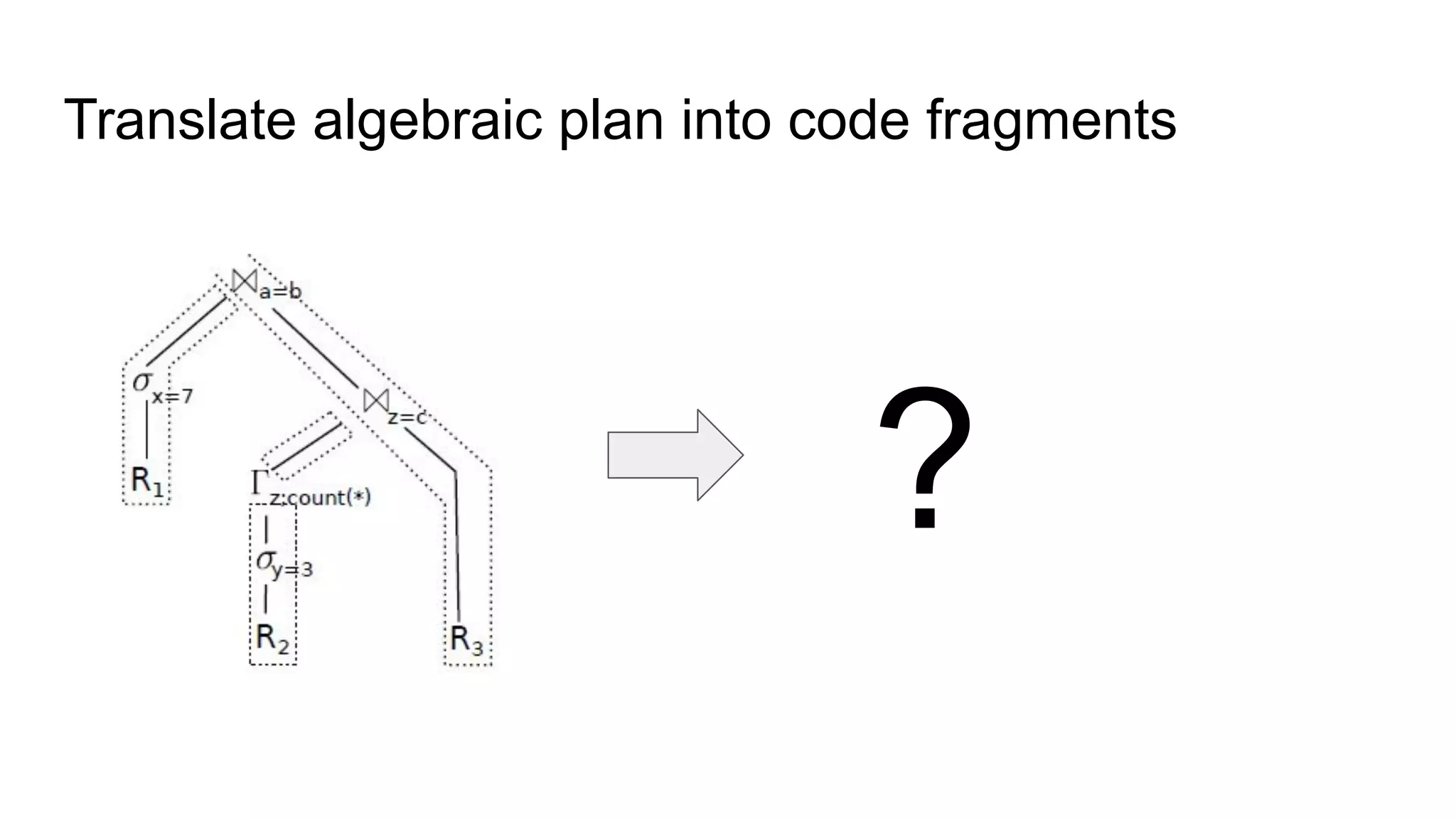
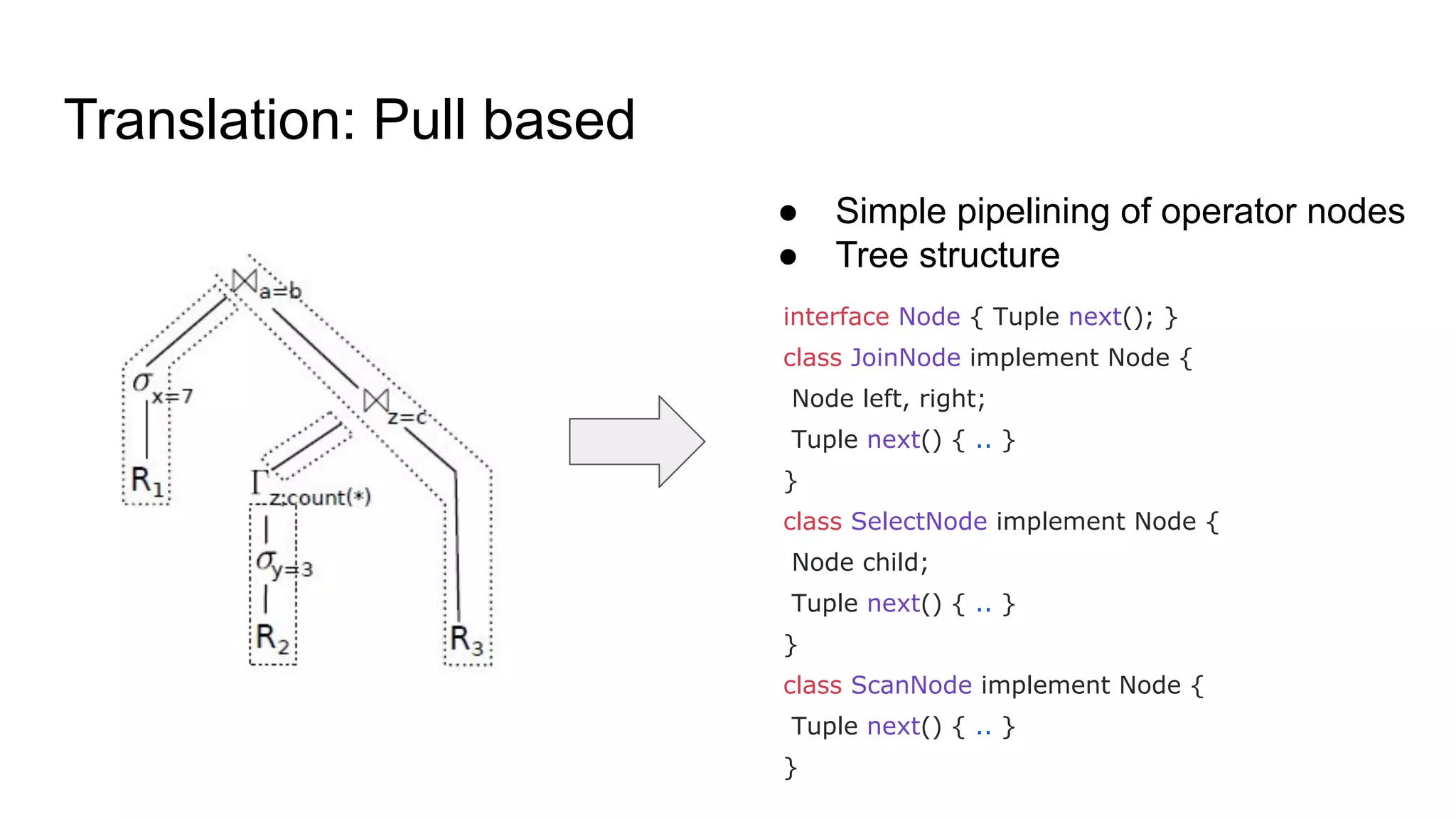
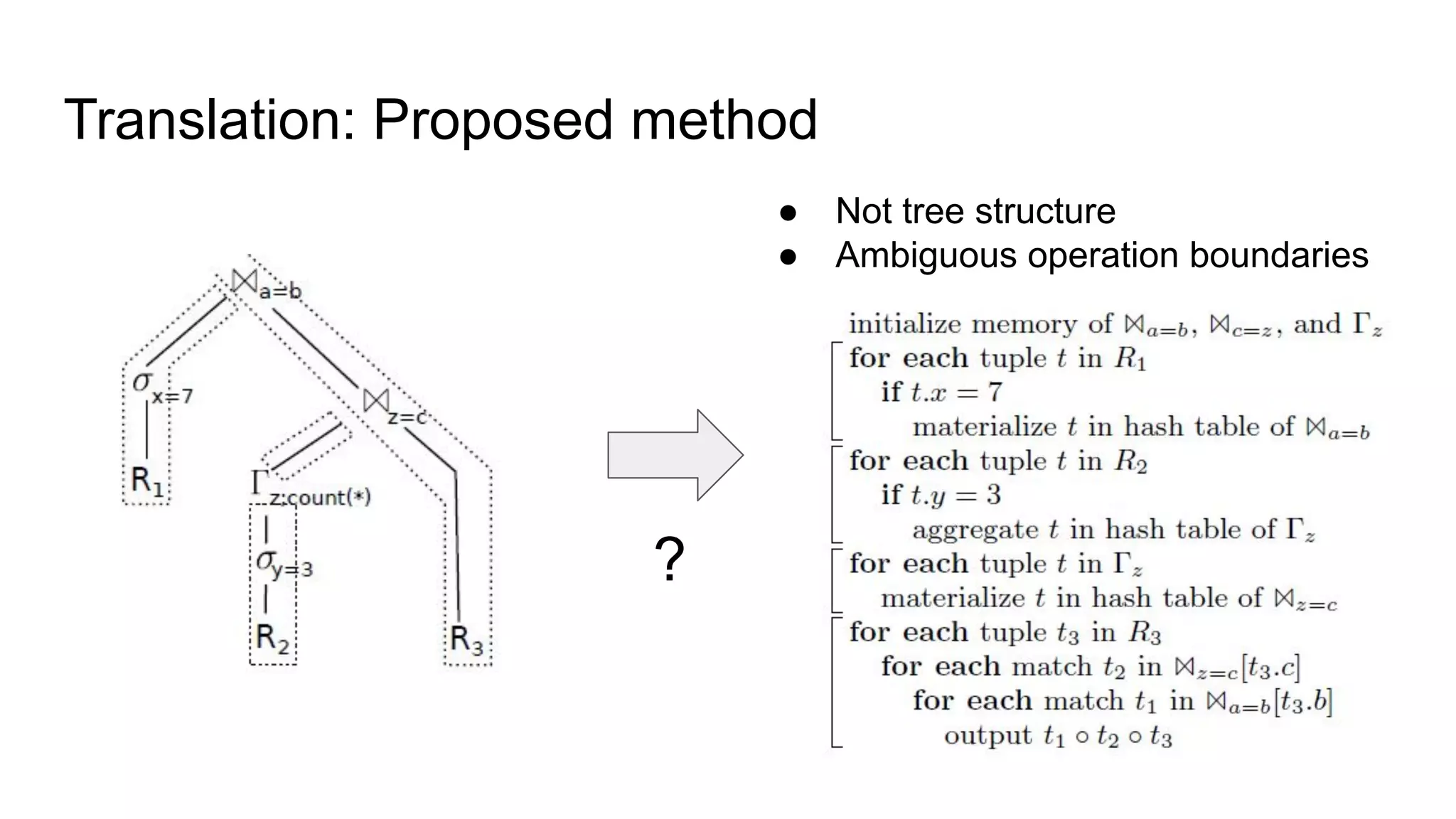
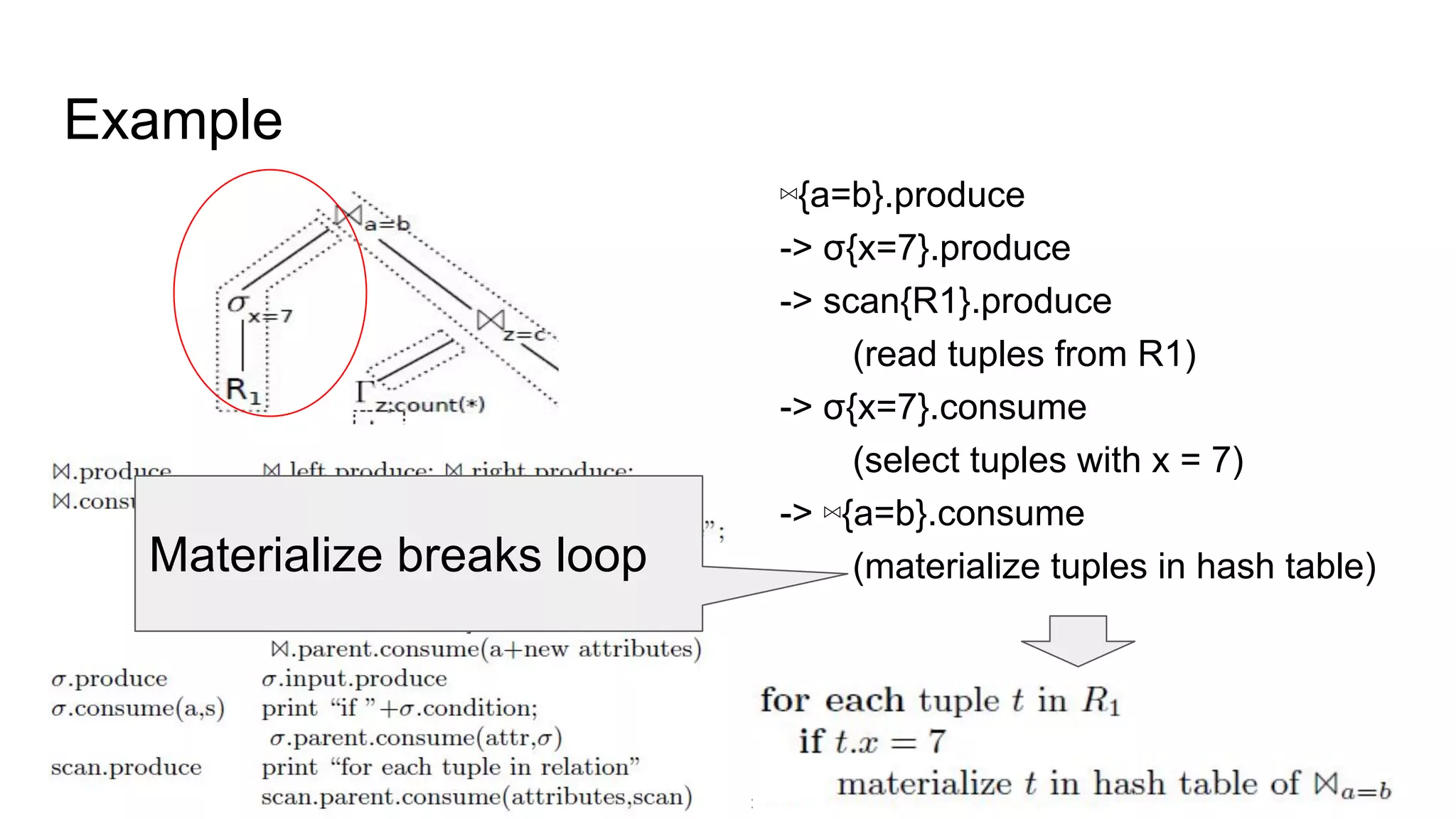
The document discusses a paper on optimizing query execution in modern database management systems (DBMS), particularly focusing on compiling efficient query plans for both Online Transaction Processing (OLTP) and Online Analytical Processing (OLAP) workloads. It contrasts different execution models such as interpreted versus compiled, and pipelining versus block processing, ultimately proposing a method that uses compiled code with block processing and push techniques for improved performance and locality. The paper emphasizes the benefits and challenges of using LLVM alongside C++ for faster compilation and better control in generating machine code.






















![[PromCon2018] Prometheus Monitoring Mixins: Using Jsonnet to Package Together...](https://cdn.slidesharecdn.com/ss_thumbnails/prometheusmonitoringmixins-180809132927-thumbnail.jpg?width=640&height=640&fit=bounds)





















































