Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Hiroshi Watanabe
PDF, PPTX
7,950 views
ハイパースレッディングの並列化への影響
8000コア規模の計算実行時に、ハイパースレッディングが並列化効率に与える影響を調べた。
Technology
◦
Read more
5
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 13
2
/ 13
3
/ 13
4
/ 13
5
/ 13
6
/ 13
7
/ 13
8
/ 13
9
/ 13
10
/ 13
11
/ 13
12
/ 13
13
/ 13
More Related Content
PDF
20分でわかるgVisor入門
by
Shuji Yamada
PPTX
pg_bigmで全文検索するときに気を付けたい5つのポイント(第23回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PDF
CPU / GPU高速化セミナー!性能モデルの理論と実践:実践編
by
Fixstars Corporation
PDF
雑なMySQLパフォーマンスチューニング
by
yoku0825
PDF
組み込み関数(intrinsic)によるSIMD入門
by
Norishige Fukushima
PDF
PostgreSQLバックアップの基本
by
Uptime Technologies LLC (JP)
PDF
PostgreSQLアーキテクチャ入門(INSIGHT OUT 2011)
by
Uptime Technologies LLC (JP)
PPTX
Reserved Instance 及び Savings Plan を感覚的に理解する
by
陽一 佐竹
20分でわかるgVisor入門
by
Shuji Yamada
pg_bigmで全文検索するときに気を付けたい5つのポイント(第23回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
CPU / GPU高速化セミナー!性能モデルの理論と実践:実践編
by
Fixstars Corporation
雑なMySQLパフォーマンスチューニング
by
yoku0825
組み込み関数(intrinsic)によるSIMD入門
by
Norishige Fukushima
PostgreSQLバックアップの基本
by
Uptime Technologies LLC (JP)
PostgreSQLアーキテクチャ入門(INSIGHT OUT 2011)
by
Uptime Technologies LLC (JP)
Reserved Instance 及び Savings Plan を感覚的に理解する
by
陽一 佐竹
What's hot
PPTX
WayOfNoTrouble.pptx
by
Daisuke Yamazaki
PPTX
PostgreSQL14の pg_stat_statements 改善(第23回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PDF
3種類のTEE比較(Intel SGX, ARM TrustZone, RISC-V Keystone)
by
Kuniyasu Suzaki
PDF
Isolation Level について
by
Takashi Hoshino
PDF
Optuna Dashboardの紹介と設計解説 - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
PDF
実践! Argo cd & rollouts による canary release(cndt2021)
by
HayatoOkuma1
PPTX
MQ入門
by
HIRA
PDF
PlaySQLAlchemy: SQLAlchemy入門
by
泰 増田
PDF
Swagger ではない OpenAPI Specification 3.0 による API サーバー開発
by
Yahoo!デベロッパーネットワーク
PDF
先端技術とメディア表現1 #FTMA15
by
Yoichi Ochiai
PDF
Deep Learning Lab 異常検知入門
by
Shohei Hido
PDF
CTF for ビギナーズ バイナリ講習資料
by
SECCON Beginners
PDF
20190206 AWS Black Belt Online Seminar Amazon SageMaker Basic Session
by
Amazon Web Services Japan
PPTX
M5StackをRustで動かす
by
Kenta IDA
PDF
不均衡データのクラス分類
by
Shintaro Fukushima
PDF
AWSとオンプレミスを繋ぐときに知っておきたいルーティングの基礎知識(CCSI監修!)
by
Trainocate Japan, Ltd.
PDF
【Zabbix2.0】snmpttによるトラップメッセージの編集 #Zabbix #自宅ラック勉強会
by
真乙 九龍
PDF
高速な倍精度指数関数expの実装
by
MITSUNARI Shigeo
PPTX
やってはいけない空振りDelete
by
Yu Yamada
PDF
SQLアンチパターン - 開発者を待ち受ける25の落とし穴 (拡大版)
by
Takuto Wada
WayOfNoTrouble.pptx
by
Daisuke Yamazaki
PostgreSQL14の pg_stat_statements 改善(第23回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
3種類のTEE比較(Intel SGX, ARM TrustZone, RISC-V Keystone)
by
Kuniyasu Suzaki
Isolation Level について
by
Takashi Hoshino
Optuna Dashboardの紹介と設計解説 - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
実践! Argo cd & rollouts による canary release(cndt2021)
by
HayatoOkuma1
MQ入門
by
HIRA
PlaySQLAlchemy: SQLAlchemy入門
by
泰 増田
Swagger ではない OpenAPI Specification 3.0 による API サーバー開発
by
Yahoo!デベロッパーネットワーク
先端技術とメディア表現1 #FTMA15
by
Yoichi Ochiai
Deep Learning Lab 異常検知入門
by
Shohei Hido
CTF for ビギナーズ バイナリ講習資料
by
SECCON Beginners
20190206 AWS Black Belt Online Seminar Amazon SageMaker Basic Session
by
Amazon Web Services Japan
M5StackをRustで動かす
by
Kenta IDA
不均衡データのクラス分類
by
Shintaro Fukushima
AWSとオンプレミスを繋ぐときに知っておきたいルーティングの基礎知識(CCSI監修!)
by
Trainocate Japan, Ltd.
【Zabbix2.0】snmpttによるトラップメッセージの編集 #Zabbix #自宅ラック勉強会
by
真乙 九龍
高速な倍精度指数関数expの実装
by
MITSUNARI Shigeo
やってはいけない空振りDelete
by
Yu Yamada
SQLアンチパターン - 開発者を待ち受ける25の落とし穴 (拡大版)
by
Takuto Wada
Viewers also liked
PDF
短距離古典分子動力学計算の 高速化と大規模並列化
by
Hiroshi Watanabe
PDF
AVX命令を用いたLJの力計算のSIMD化
by
Hiroshi Watanabe
PDF
短距離ハイブリッド並列分子動力学コードの設計思想と説明のようなもの
by
Hiroshi Watanabe
PDF
短距離ハイブリッド並列分子動力学コードの設計思想と説明のようなもの 〜並列編〜
by
Hiroshi Watanabe
PDF
空間分割
by
amusementcreators
PDF
衝突判定
by
Moto Yan
PDF
CMSI計算科学技術特論A(12) 古典分子動力学法の高速化1
by
Computational Materials Science Initiative
PDF
Cedec2015 ゲームサーバー基盤の新しい選択肢
by
Maho Takara
PDF
負の二項分布について
by
Hiroshi Shimizu
PDF
20150821 Azure 仮想マシンと仮想ネットワーク
by
Kuninobu SaSaki
短距離古典分子動力学計算の 高速化と大規模並列化
by
Hiroshi Watanabe
AVX命令を用いたLJの力計算のSIMD化
by
Hiroshi Watanabe
短距離ハイブリッド並列分子動力学コードの設計思想と説明のようなもの
by
Hiroshi Watanabe
短距離ハイブリッド並列分子動力学コードの設計思想と説明のようなもの 〜並列編〜
by
Hiroshi Watanabe
空間分割
by
amusementcreators
衝突判定
by
Moto Yan
CMSI計算科学技術特論A(12) 古典分子動力学法の高速化1
by
Computational Materials Science Initiative
Cedec2015 ゲームサーバー基盤の新しい選択肢
by
Maho Takara
負の二項分布について
by
Hiroshi Shimizu
20150821 Azure 仮想マシンと仮想ネットワーク
by
Kuninobu SaSaki
More from Hiroshi Watanabe
PDF
Enjoy supercomputing
by
Hiroshi Watanabe
PDF
CMSI計算科学技術特論A(8) 高速化チューニングとその関連技術2
by
Hiroshi Watanabe
PDF
CMSI計算科学技術特論A(8) 高速化チューニングとその関連技術1
by
Hiroshi Watanabe
PDF
MDとはなにか
by
Hiroshi Watanabe
PDF
Huge-Scale Molecular Dynamics Simulation of Multi-bubble Nuclei
by
Hiroshi Watanabe
PDF
130613-debug
by
Hiroshi Watanabe
PDF
Tuning, etc.
by
Hiroshi Watanabe
Enjoy supercomputing
by
Hiroshi Watanabe
CMSI計算科学技術特論A(8) 高速化チューニングとその関連技術2
by
Hiroshi Watanabe
CMSI計算科学技術特論A(8) 高速化チューニングとその関連技術1
by
Hiroshi Watanabe
MDとはなにか
by
Hiroshi Watanabe
Huge-Scale Molecular Dynamics Simulation of Multi-bubble Nuclei
by
Hiroshi Watanabe
130613-debug
by
Hiroshi Watanabe
Tuning, etc.
by
Hiroshi Watanabe
ハイパースレッディングの並列化への影響
1.
1/13 ハイパースレッディングの 並列化効率への影響 東京大学物性研究所 渡辺宙志
2.
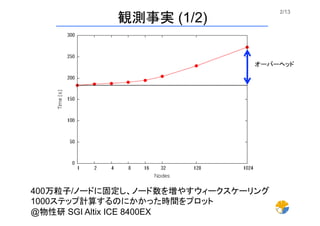
2/13 400万粒子/ノードに固定し、ノード数を増やすウィークスケーリング 1000ステップ計算するのにかかった時間をプロット @物性研 SGI Altix
ICE 8400EX 観測事実 (1/2) オーバーヘッド
3.
3/13 観測事実 (2/2) (1) 粒度が疎、つまり計算時間に比して通信時間が相当 短いはずなのに、ウィークスケーリングで高並列時に 性能が劣化する (2) 力の計算時間を測定してみると、通信を含まないは ずなのにプロセスごとに時間がばらついている (3) 時間のばらつきはプロセス数を増やすと大きくなり、 全体同期により性能劣化を招いている (4) まったく同じ計算をしても、遅いプロセスは毎回異なる システムノイズ(OSジッタ)だろうか? しかしOSジッタにしては影響が大きすぎる
4.
4/13 調べたいこと (1) プロセスの実行時間の揺らぎを精密に調べる (2) ハイパースレッディング(HT) の並列性能への影響を 調べる
5.
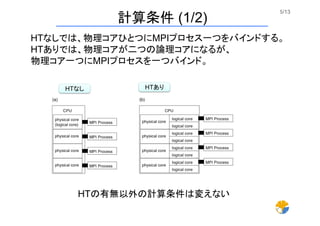
5/13 HTなし HTあり HTなしでは、物理コアひとつにMPIプロセス一つをバインドする。 HTありでは、物理コアが二つの論理コアになるが、 物理コア一つにMPIプロセスを一つバインド。 計算条件 (1/2) HTの有無以外の計算条件は変えない
6.
6/13 計算条件 (2/2) 東京大学物性研究所 システムB SGI
Altix ICE 8400EX CPU: Intel Xeon X5570 2.93GHz 4コア/CPU、2CPU/ノード 計算資源: 計算条件: カットオフ2.5σのLennard-Jones粒子系 時間ステップ 0.001、数密度: 0.5 粒子数: 50万粒子/コア、 400万粒子/ノード Flat-MPIによる領域分割 計算コード:http://mdacp.sourceforge.net/ 測定日:2011年6月 ※ HT無効の計算は1ノードから1024ノードまで数点を、 HTを有効にした計算は、1024ノード、8192コアの一点のみを計算
7.
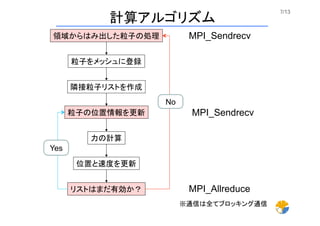
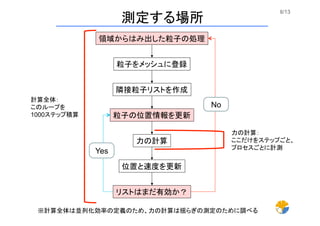
7/13 粒子をメッシュに登録 隣接粒子リストを作成 力の計算 位置と速度を更新 リストはまだ有効か? No Yes 領域からはみ出した粒子の処理 粒子の位置情報を更新 MPI_Sendrecv MPI_Sendrecv MPI_Allreduce 計算アルゴリズム ※通信は全てブロッキング通信
8.
8/13 粒子をメッシュに登録 隣接粒子リストを作成 力の計算 位置と速度を更新 リストはまだ有効か? No Yes 領域からはみ出した粒子の処理 粒子の位置情報を更新 測定する場所 計算全体: このループを 1000ステップ積算 力の計算: ここだけをステップごと、 プロセスごとに計測 ※計算全体は並列化効率の定義のため、力の計算は揺らぎの測定のために調べる
9.
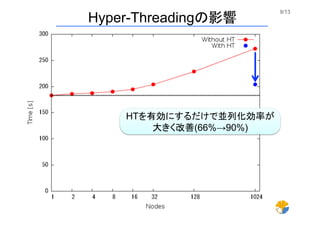
9/13 Hyper-Threadingの影響 HTを有効にするだけで並列化効率が 大きく改善(66%→90%)
10.
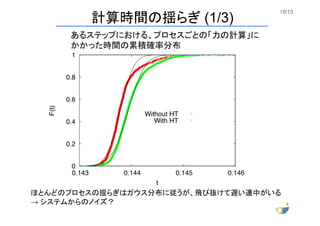
10/13 あるステップにおける、プロセスごとの「力の計算」に かかった時間の累積確率分布 ほとんどのプロセスの揺らぎはガウス分布に従うが、飛び抜けて遅い連中がいる → システムからのノイズ? 計算時間の揺らぎ (1/3)
11.
11/13 誤差関数でフィットしてみる 特徴的な時間「τ」 ガウス分布の標準偏差に相当 HTなし:平均時間 143.785 [ms]
標準偏差 0.29 [ms] HTあり:平均時間 143.940 [ms] 標準偏差 0.36 [ms] 一番遅かったプロセス: HTなし: 221.543 [ms] HTあり: 164.009 [ms] 平均からのずれが256σ 統計情報からはHTなしの方が優れている(平均も揺らぎも小さい)が・・・ 一番遅いプロセスの実行時間がHTにより大きく改善された 計算時間の揺らぎ (2/3)
12.
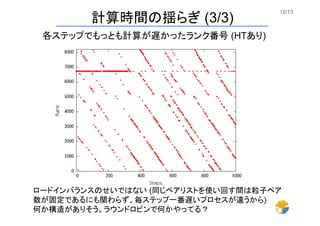
12/13 計算時間の揺らぎ (3/3) 各ステップでもっとも計算が遅かったランク番号 (HTあり)
ロードインバランスのせいではない (同じペアリストを使い回す間は粒子ペア 数が固定であるにも関わらず、毎ステップ一番遅いプロセスが違うから) 何か構造がありそう。ラウンドロビンで何かやってる?
13.
13/13 まとめのようなもの (1) Hyper-Threading Technologyを有効にすることで 並列化効率が大きく向上→HTによるスムーズなス レッドの切り替えが要因? (2) 揺らぐ時間は80ミリ秒といったオーダー → OSジッタとしては大きすぎる (3)
通信を含まないはずの領域を測定しているのに、計 算時間が大きく揺らぐ →通信の後処理が割り込んでいる?
Download






![11/13
誤差関数でフィットしてみる
特徴的な時間「τ」
ガウス分布の標準偏差に相当
HTなし:平均時間 143.785 [ms] 標準偏差 0.29 [ms]
HTあり:平均時間 143.940 [ms] 標準偏差 0.36 [ms]
一番遅かったプロセス:
HTなし: 221.543 [ms]
HTあり: 164.009 [ms]
平均からのずれが256σ
統計情報からはHTなしの方が優れている(平均も揺らぎも小さい)が・・・
一番遅いプロセスの実行時間がHTにより大きく改善された
計算時間の揺らぎ (2/3)](https://image.slidesharecdn.com/130523ht-130523222246-phpapp02/85/slide-11-320.jpg)