
Recommended
More Related Content
Viewers also liked
Viewers also liked (11)
Similar to Minimal Effort Ingest for DPC Metadata meeting
Similar to Minimal Effort Ingest for DPC Metadata meeting (20)
Recently uploaded
Recently uploaded (20)
Minimal Effort Ingest for DPC Metadata meeting
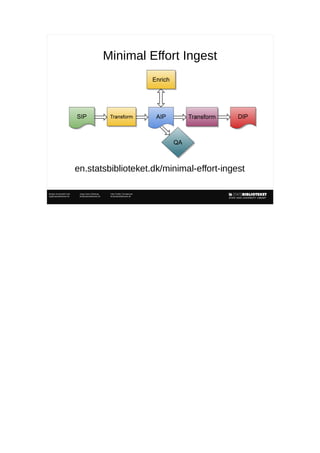
- 1. Bolette Ammitzbøll Jurik Asger Askov Blekinge Kåre Fiedler Christiansen baj@statsbiblioteket.dk abr@statsbiblioteket.dk kfc@statsbiblioteket.dk Minimal Effort Ingest en.statsbiblioteket.dk/minimal-effort-ingest
- 2. Dec 3, 2015 2 Bolette Ammitzbøll Jurik Asger Askov Blekinge Kåre Fiedler Christiansen baj@statsbiblioteket.dk abr@statsbiblioteket.dk kfc@statsbiblioteket.dk State and University Library ● A National Library – Responsible for preserving the Danish Cultural Heritage ● Many diverse collections, from many legacy systems – These collections must be preserved, but very few users want access.
- 3. Dec 3, 2015 3 Bolette Ammitzbøll Jurik Asger Askov Blekinge Kåre Fiedler Christiansen baj@statsbiblioteket.dk abr@statsbiblioteket.dk kfc@statsbiblioteket.dk What is Minimal Effort Ingest? ● A different approach to ingest and Quality Assurance ● In OAIS detailed QA is part of ingest – Strict compliance required before ingest ● Minimal Effort Ingest postpones most of QA – Data ingested as is – QA is done just after ingest - or even later, if resources are sparse – Failure in QA is handled within the repository
- 4. Dec 3, 2015 4 Bolette Ammitzbøll Jurik Asger Askov Blekinge Kåre Fiedler Christiansen baj@statsbiblioteket.dk abr@statsbiblioteket.dk kfc@statsbiblioteket.dk Why do Minimal Effort Ingest? ● Secure the incoming data quickly ● Old collections are preserved – even if resources for QA are not available ● Update and rerun preservation actions as needed
- 5. Dec 3, 2015 5 Bolette Ammitzbøll Jurik Asger Askov Blekinge Kåre Fiedler Christiansen baj@statsbiblioteket.dk abr@statsbiblioteket.dk kfc@statsbiblioteket.dk Minimal Effort Ingest – An example ● Collection: Wav files and a CSV file with metadata 1) Ingest all the files, just as File Objects 2) Generate technical metadata for the File Objects 3) Parse the CSV file and create Track Objects 4) Generate Access Copies for the Track Objects 5) Verify that the Track Metadata is correct 1) Simple checks such as duration 2) Complex checks could be akin to forensics 6) Do speech2text to generate better indexes You can do as many of these as you have the budget for. If you do only 1, the collection is still well preserved If you also do 2, you will be able to plan for format preservation risks If you do 3 the collection can be made available for discovery If you do 4 the collection can be made available for access If you do 5, you can verify that your collection actually contain what you believe it do If you do 6, you can improve the discovery greatly Do note that point 4 and 5 can be done in reverse order, if quality is more important than access.
- 6. Dec 3, 2015 6 Bolette Ammitzbøll Jurik Asger Askov Blekinge Kåre Fiedler Christiansen baj@statsbiblioteket.dk abr@statsbiblioteket.dk kfc@statsbiblioteket.dk In a timely fashion... ● The important matter is that everything, data and metadata and context, is available when needed, and not before ● This includes information not known at the time of creation ● So the question becomes not – How much metadata do I need? ● but rather – When would I need this metadata? Some metadata is only available at the time of creation, even if it is only used much later, eg. digitization hardware. While it is good practice to get as much metadata as possible as early is possible, do not assume you can get all. Some require tools (speech2text, OCR) which are still improving Some metadata require special skills to both generate and understand The most important metadata might not be something the creator can provide Journals and citation-counts is one such example. Truthfulness is another.
- 7. Dec 3, 2015 7 Bolette Ammitzbøll Jurik Asger Askov Blekinge Kåre Fiedler Christiansen baj@statsbiblioteket.dk abr@statsbiblioteket.dk kfc@statsbiblioteket.dk Expensive Understandings ● In our experience, the most expensive part of digital preservation is understanding your collection ● This cost turned out to be fairly constant, irrespective of the collection size ● This is even more true for Research Data ● Preserving the files and preserving the understanding are very different challenges Understanding a collection allows you to build data models and to do QA Datamodels are important for Access systems. QA is only really important, if you are able to get a better version of the data. When receiving these data from a provider, you can often request a new version, if something is broken. When “represerving” an old collection or when getting research data, the data is what it is, broken or not. QA becomes less valuable, as a broken file is still more valuable than no file Preserving understanding. Is it nessessary, and how much? Should I preserve the jpeg spec along with my jpeg files? How about a dictionary?
- 8. Dec 3, 2015 8 Bolette Ammitzbøll Jurik Asger Askov Blekinge Kåre Fiedler Christiansen baj@statsbiblioteket.dk abr@statsbiblioteket.dk kfc@statsbiblioteket.dk Preservation Events ● Our archival record's life will often consist of these three phases 1) Raw Ingest 2) Enrichment and transformation to data model 3) Preservation Actions ● The history of a Record should include all these phases. This happens naturally if the transformation happens inside the repository. ● Unfortunately, many traditional systems do their most important transformations before ingest. With Minimal Effort Ingest, even the preparation happens inside the repository. So whatever version/event tracking system the repository uses, will also list the initial transformations. It is hard to prove authenticity if you cannot show what changes happened from “files on disk” to “SIP” even if you know everything that happened from “SIP” and onwards.
- 9. Dec 3, 2015 9 Bolette Ammitzbøll Jurik Asger Askov Blekinge Kåre Fiedler Christiansen baj@statsbiblioteket.dk abr@statsbiblioteket.dk kfc@statsbiblioteket.dk Preservation 2.0? ● Web 1.0 was the web of static webpages, and the user would read but never contribute ● Web 2.0 is perhaps best exemplified by Wikis, where the user is also an editor ● Records are updated, but with strong versioning and history This does not mean everybody can edit, it means that the system is build around the concept of updating and enriching content. We still envisage a strong Curatorial presence. The dead archival record is past. Records in the repository are alive. They are updated, changed and interlinked during their lifetime. Design your preservation systems not as the archives of old, but as the wikis of today.
Editor's Notes
- You can do as many of these as you have the budget for. If you do only 1, the collection is still well preserved If you also do 2, you will be able to plan for format preservation risks If you do 3 the collection can be made available for discovery If you do 4 the collection can be made available for access If you do 5, you can verify that your collection actually contain what you believe it do If you do 6, you can improve the discovery greatly Do note that point 4 and 5 can be done in reverse order, if quality is more important than access.
- Some metadata is only available at the time of creation, even if it is only used much later, eg. digitization hardware. While it is good practice to get as much metadata as possible as early is possible, do not assume you can get all. Some require tools (speech2text, OCR) which are still improving Some metadata require special skills to both generate and understand The most important metadata might not be something the creator can provide Journals and citation-counts is one such example. Truthfulness is another.
- Understanding a collection allows you to build data models and to do QA Datamodels are important for Access systems. QA is only really important, if you are able to get a better version of the data. When receiving these data from a provider, you can often request a new version, if something is broken. When “represerving” an old collection or when getting research data, the data is what it is, broken or not. QA becomes less valuable, as a broken file is still more valuable than no file Preserving understanding. Is it nessessary, and how much? Should I preserve the jpeg spec along with my jpeg files? How about a dictionary?
- With Minimal Effort Ingest, even the preparation happens inside the repository. So whatever version/event tracking system the repository uses, will also list the initial transformations. It is hard to prove authenticity if you cannot show what changes happened from “files on disk” to “SIP” even if you know everything that happened from “SIP” and onwards.
- This does not mean everybody can edit, it means that the system is build around the concept of updating and enriching content. We still envisage a strong Curatorial presence. The dead archival record is past. Records in the repository are alive. They are updated, changed and interlinked during their lifetime. Design your preservation systems not as the archives of old, but as the wikis of today.