Download as PDF, PPTX










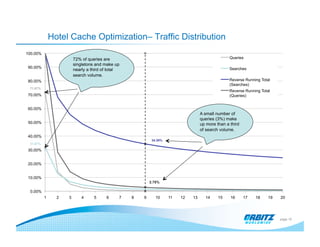



The machine learning team at Orbitz, established in 2009, aims to enhance the customer experience through data-driven methods in hotel search optimizations and cache management. They encountered significant data access challenges but implemented Hadoop and Hive to improve data processing and analysis capabilities. Their work focuses on optimizing cache strategies and traffic management to improve search performance while controlling the impact on suppliers.









































