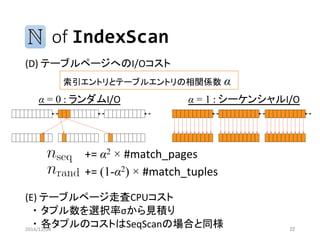
of HashJoin
2014/12/0430
record
record
record
record
record
record
record
record
record
record
バケツ数: 2
record
record
record
record
record
record
record
record
record
record
バケツ数: 5
record
record
record
record
record
record
record
record
record
record
build
平均2.5回のタプル比較
平均1回のタプル比較
2.00E+06
2.20E+06
2.40E+06
2.60E+06
2.80E+06
0
50000
100000
150000
Cost
inner表選択数
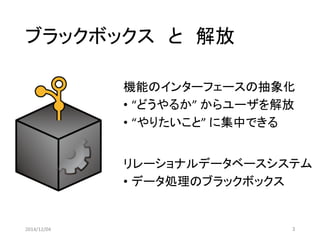
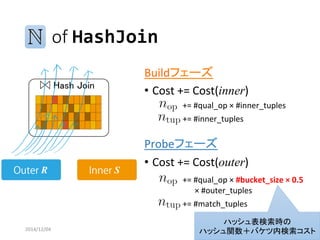
Cost Estimation of Hash Join
・PostgreSQLのバケツサイズ戦略
→ inner表選択数に応じて2倍ずつ増やす
・バケットサイズ拡大直後はコストが低下
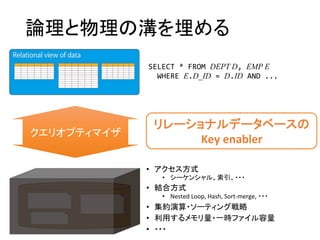
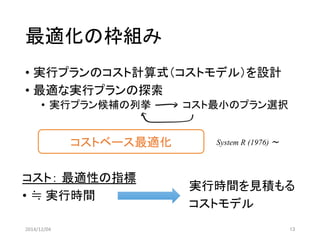
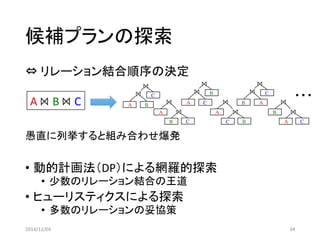
候補プランの探索
⇔リレーション結合順序の決定
愚直に列挙すると組み合わせ爆発
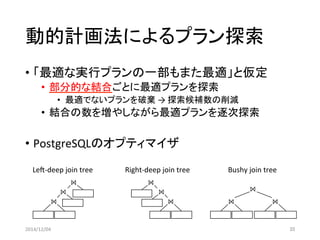
•動的計画法(DP)による網羅的探索
•少数のリレーション結合の王道
•ヒューリスティクスによる探索
•多数のリレーションの妥協策
2014/12/04 34
A⨝B⨝C
A
B
⨝
C
⨝
A
C
⨝
B
⨝
B
A
⨝
C
⨝
A
B
⨝
C
⨝
A
C
⨝
B
⨝
B
A
⨝
C
⨝
・・・
































![PostgreSQL!
クエリ最適化の研究
•System R (1976)
•動的計画法によるコストベース最適化
•Challenging な取り組み
•Multi-query optimization [T.Sellis, 1987]
•Dynamic mid-query re-optimization [N.Kabraet.al., 1998]
•Query progress indicator [G.Luoet.al., 2004]
•Access cost estimation on distributed object storage [B.Araiet.al., 2010]
•Query optimization for hierarchical partitioning [H.Herodotouet.al., 2011]
•SDN-powered optimizer on distributed storage [P.Xionget.al., 2014]
•Cost estimation improvement with proactive subset query execution [A.Duttet.al., 2014]
•Pilot Run によるUDFコスト推定[K.Karanasoset.al., 2014]
2014/12/04 42](https://image.slidesharecdn.com/pgconj2014-141206002910-conversion-gate02/85/slide-42-320.jpg)



























































