Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
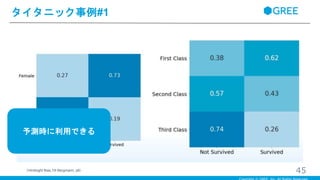
Change Language
Language
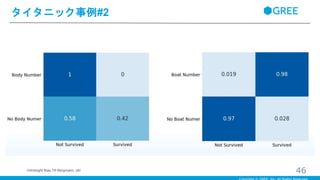
English
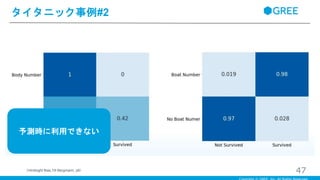
Español
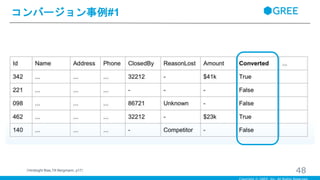
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
gree_tech
PPTX, PDF
8,271 views
DataEngConf NYC’18 セッションサマリー #1
グリー開発本部 Meetup #1 DataEngConf NYC報告会で発表された資料です。 https://gree.connpass.com/event/107057/
Engineering
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 63
2
/ 63
3
/ 63
4
/ 63
5
/ 63
6
/ 63
7
/ 63
8
/ 63
9
/ 63
10
/ 63
11
/ 63
12
/ 63
13
/ 63
14
/ 63
15
/ 63
16
/ 63
17
/ 63
18
/ 63
19
/ 63
20
/ 63
21
/ 63
22
/ 63
23
/ 63
24
/ 63
25
/ 63
26
/ 63
27
/ 63
28
/ 63
29
/ 63
30
/ 63
31
/ 63
32
/ 63
33
/ 63
34
/ 63
35
/ 63
36
/ 63
37
/ 63
38
/ 63
39
/ 63
40
/ 63
41
/ 63
42
/ 63
43
/ 63
44
/ 63
45
/ 63
46
/ 63
47
/ 63
48
/ 63
49
/ 63
50
/ 63
51
/ 63
52
/ 63
53
/ 63
54
/ 63
55
/ 63
56
/ 63
57
/ 63
58
/ 63
59
/ 63
60
/ 63
61
/ 63
62
/ 63
63
/ 63
More Related Content
PPTX
アナザーエデンを支える技術〜効率的なコンテンツ制作のための開発基盤〜
by
gree_tech
PPTX
第一回☆GREE AI Programming ContestでTensorFlow
by
gree_tech
PDF
[Livesence Tech Night] グリーにおけるHiveの運用
by
gree_tech
PDF
行ってみよう、やってみよう!
by
gree_tech
PPTX
グリーにおけるAWS移行の必然性
by
gree_tech
PDF
エンジニア以外の方が自らSQLを使ってセグメント分析を行うカルチャーをどのように作っていったか
by
gree_tech
PDF
インフラエンジニアの楽しい標準化活動
by
gree_tech
PPTX
グリーで行われている勉強会とその特徴 ✕ 勉強会を主催してみた話
by
gree_tech
アナザーエデンを支える技術〜効率的なコンテンツ制作のための開発基盤〜
by
gree_tech
第一回☆GREE AI Programming ContestでTensorFlow
by
gree_tech
[Livesence Tech Night] グリーにおけるHiveの運用
by
gree_tech
行ってみよう、やってみよう!
by
gree_tech
グリーにおけるAWS移行の必然性
by
gree_tech
エンジニア以外の方が自らSQLを使ってセグメント分析を行うカルチャーをどのように作っていったか
by
gree_tech
インフラエンジニアの楽しい標準化活動
by
gree_tech
グリーで行われている勉強会とその特徴 ✕ 勉強会を主催してみた話
by
gree_tech
What's hot
PPTX
[デブサミ秋2015] 新卒入社エンジニアが 2年間fluentdを運用して学んだ事いろいろ
by
gree_tech
PPTX
クラウドの積極的利活用による生産性向上と経営に寄与する仕組みづくり
by
gree_tech
PPTX
消滅都市5周年の運営を支えた技術とその歴史
by
gree_tech
PDF
Googleのインフラ技術から考える理想のDevOps
by
Etsuji Nakai
PPTX
ハイブリッドクラウドで変わるインフラストラクチャ設計
by
gree_tech
PPTX
DataEngConf NYC’18 セッションサマリー #2
by
gree_tech
PDF
【16-E-4】残業ゼロで開発スピードが10倍に!もう元の開発体制には戻れないデンソー流のアジャイル開発
by
Developers Summit
PDF
Cedec2015_「消滅都市」運用の一年
by
gree_tech
PPTX
インターネットの維持 近況
by
gree_tech
PPTX
Sumo Logic活用事例とその運用
by
gree_tech
PDF
Developers Summit 2018: ストリームとバッチを融合したBigData Analytics ~事例とデモから見えてくる、これからのデー...
by
オラクルエンジニア通信
PDF
GitLabのAutoDevOpsを試してみた
by
富士通クラウドテクノロジーズ株式会社
PDF
【17-D-1】今どきのアーキテクチャを現場の立場で斬る
by
Developers Summit
PPTX
インターネットの維持再考(導入編)
by
gree_tech
PDF
Developers Summit 2018 | IoTサービスを始める際に必要なこととは
by
SORACOM,INC
PDF
6製品1サービスの開発にPortfolio for JIRAを使ってみた
by
Hiroshi Ohnuki
PDF
Yahoo!ブラウザーアプリのプロダクトマネージャーが考えていること
by
Yahoo!デベロッパーネットワーク
PDF
[db tech showcase Tokyo 2016] B15: サイバーエージェント アドテクスタジオの次世代データ分析基盤紹介 by 株式会社サイ...
by
Insight Technology, Inc.
PDF
データファースト開発
by
Katsunori Kanda
PDF
DevOps at ChatWork
by
Masaki Yamamoto
[デブサミ秋2015] 新卒入社エンジニアが 2年間fluentdを運用して学んだ事いろいろ
by
gree_tech
クラウドの積極的利活用による生産性向上と経営に寄与する仕組みづくり
by
gree_tech
消滅都市5周年の運営を支えた技術とその歴史
by
gree_tech
Googleのインフラ技術から考える理想のDevOps
by
Etsuji Nakai
ハイブリッドクラウドで変わるインフラストラクチャ設計
by
gree_tech
DataEngConf NYC’18 セッションサマリー #2
by
gree_tech
【16-E-4】残業ゼロで開発スピードが10倍に!もう元の開発体制には戻れないデンソー流のアジャイル開発
by
Developers Summit
Cedec2015_「消滅都市」運用の一年
by
gree_tech
インターネットの維持 近況
by
gree_tech
Sumo Logic活用事例とその運用
by
gree_tech
Developers Summit 2018: ストリームとバッチを融合したBigData Analytics ~事例とデモから見えてくる、これからのデー...
by
オラクルエンジニア通信
GitLabのAutoDevOpsを試してみた
by
富士通クラウドテクノロジーズ株式会社
【17-D-1】今どきのアーキテクチャを現場の立場で斬る
by
Developers Summit
インターネットの維持再考(導入編)
by
gree_tech
Developers Summit 2018 | IoTサービスを始める際に必要なこととは
by
SORACOM,INC
6製品1サービスの開発にPortfolio for JIRAを使ってみた
by
Hiroshi Ohnuki
Yahoo!ブラウザーアプリのプロダクトマネージャーが考えていること
by
Yahoo!デベロッパーネットワーク
[db tech showcase Tokyo 2016] B15: サイバーエージェント アドテクスタジオの次世代データ分析基盤紹介 by 株式会社サイ...
by
Insight Technology, Inc.
データファースト開発
by
Katsunori Kanda
DevOps at ChatWork
by
Masaki Yamamoto
Similar to DataEngConf NYC’18 セッションサマリー #1
PDF
Spark + AI Summit 2020セッションのハイライト(Spark Meetup Tokyo #3 Online発表資料)
by
NTT DATA Technology & Innovation
PDF
動的モデル 【クラウドアプリケーションのためのオブジェクト指向分析設計講座 第6回】
by
Tomoharu ASAMI
PDF
5th長崎QDGオープニング&開催レポート
by
NaITE_Official
PDF
Linked Open Dataで市民協働と情報技術者をつなげる試み
by
Shun Shiramatsu
PDF
4th長崎QDG オープニング & 開催レポート
by
NaITE_Official
PDF
10大ニュースで振り返るpg con2013
by
NTT DATA OSS Professional Services
PPTX
ICDE 2007 Overview Presentation
by
Yu Suzuki
PDF
20110305_Code4Lib2011参加報告会:田辺浩介参加報告
by
Code4Lib JAPAN
PPTX
SIGGRAPH 2019 Report
by
Kazuyuki Miyazawa
PPTX
Spark+AI Summit Europe 2019 セッションハイライト(Spark Meetup Tokyo #2 講演資料)
by
NTT DATA Technology & Innovation
PDF
5th長崎QDGオープニングセッション
by
NaITE_Official
PDF
【Jpug勉強会】10大ニュースで振り返るpg con2013
by
Daichi Egawa
PDF
「Linked dataとLinked Open Data」アート・ドキュメンテーション学会
by
KAMURA
PDF
VLDB2015 会議報告
by
Yuto Hayamizu
PDF
イベント企画運営の経験と実際 / The history of organizing events by me
by
whywaita
PPTX
【UDC2015】大阪ブロック
by
CSISi
PDF
分析/イベント駆動 【クラウドアプリケーションのためのオブジェクト指向分析設計講座 第17回】
by
Tomoharu ASAMI
PPTX
ODSC East 2017 Report
by
Takeshi Akutsu
PDF
オープンデータと Linked Open Data(LOD)@神戸R
by
Kouji Kozaki
PDF
Code4Lib 2010報告会・発表ダイジェスト
by
Masao Takaku
Spark + AI Summit 2020セッションのハイライト(Spark Meetup Tokyo #3 Online発表資料)
by
NTT DATA Technology & Innovation
動的モデル 【クラウドアプリケーションのためのオブジェクト指向分析設計講座 第6回】
by
Tomoharu ASAMI
5th長崎QDGオープニング&開催レポート
by
NaITE_Official
Linked Open Dataで市民協働と情報技術者をつなげる試み
by
Shun Shiramatsu
4th長崎QDG オープニング & 開催レポート
by
NaITE_Official
10大ニュースで振り返るpg con2013
by
NTT DATA OSS Professional Services
ICDE 2007 Overview Presentation
by
Yu Suzuki
20110305_Code4Lib2011参加報告会:田辺浩介参加報告
by
Code4Lib JAPAN
SIGGRAPH 2019 Report
by
Kazuyuki Miyazawa
Spark+AI Summit Europe 2019 セッションハイライト(Spark Meetup Tokyo #2 講演資料)
by
NTT DATA Technology & Innovation
5th長崎QDGオープニングセッション
by
NaITE_Official
【Jpug勉強会】10大ニュースで振り返るpg con2013
by
Daichi Egawa
「Linked dataとLinked Open Data」アート・ドキュメンテーション学会
by
KAMURA
VLDB2015 会議報告
by
Yuto Hayamizu
イベント企画運営の経験と実際 / The history of organizing events by me
by
whywaita
【UDC2015】大阪ブロック
by
CSISi
分析/イベント駆動 【クラウドアプリケーションのためのオブジェクト指向分析設計講座 第17回】
by
Tomoharu ASAMI
ODSC East 2017 Report
by
Takeshi Akutsu
オープンデータと Linked Open Data(LOD)@神戸R
by
Kouji Kozaki
Code4Lib 2010報告会・発表ダイジェスト
by
Masao Takaku
More from gree_tech
PPTX
アナザーエデンPC版リリースへの道のり 〜WFSにおけるマルチプラットフォーム対応の取り組み〜
by
gree_tech
PDF
GREE VR Studio Laboratory「XR-UX Devプロジェクト」の成果紹介
by
gree_tech
PPTX
REALITYアバターを様々なメタバースで活躍させてみた - GREE VR Studio Laboratory インターン研究成果発表
by
gree_tech
PPTX
アプリ起動時間高速化 ~推測するな、計測せよ~
by
gree_tech
PPTX
長寿なゲーム事業におけるアプリビルドの効率化
by
gree_tech
PPTX
Cloud Spanner をより便利にする運用支援ツールの紹介
by
gree_tech
PPTX
WFSにおけるCloud SpannerとGKEを中心としたGCP導入事例の紹介
by
gree_tech
PPTX
SINoALICE -シノアリス- Google Cloud Firestoreを用いた観戦機能の実現について
by
gree_tech
PPTX
海外展開と負荷試験
by
gree_tech
PPTX
翻訳QAでのテスト自動化の取り組み
by
gree_tech
PPTX
組み込み開発のテストとゲーム開発のテストの違い
by
gree_tech
PPTX
サーバーフレームワークに潜んでる脆弱性検知ツール紹介
by
gree_tech
PPTX
データエンジニアとアナリストチーム兼務になった件について
by
gree_tech
PPTX
シェアドサービスとしてのデータテクノロジー
by
gree_tech
PPTX
「ドキュメント見つからない問題」をなんとかしたい - 横断検索エンジン導入の取り組みについて-
by
gree_tech
PPTX
「Atomic Design × Nuxt.js」コンポーネント毎に責務の範囲を明確にしたら幸せになった話
by
gree_tech
PPTX
比較サイトの検索改善(SPA から SSR に変換)
by
gree_tech
PPTX
コードの自動修正によって実現する、機能開発を止めないフレームワーク移行
by
gree_tech
PPTX
「やんちゃ、足りてる?」〜ヤンマガWebで挑戦を続ける新入りエンジニア〜
by
gree_tech
PPTX
法人向けメタバースプラットフォームの開発の裏側をのぞいてみた(仮)
by
gree_tech
アナザーエデンPC版リリースへの道のり 〜WFSにおけるマルチプラットフォーム対応の取り組み〜
by
gree_tech
GREE VR Studio Laboratory「XR-UX Devプロジェクト」の成果紹介
by
gree_tech
REALITYアバターを様々なメタバースで活躍させてみた - GREE VR Studio Laboratory インターン研究成果発表
by
gree_tech
アプリ起動時間高速化 ~推測するな、計測せよ~
by
gree_tech
長寿なゲーム事業におけるアプリビルドの効率化
by
gree_tech
Cloud Spanner をより便利にする運用支援ツールの紹介
by
gree_tech
WFSにおけるCloud SpannerとGKEを中心としたGCP導入事例の紹介
by
gree_tech
SINoALICE -シノアリス- Google Cloud Firestoreを用いた観戦機能の実現について
by
gree_tech
海外展開と負荷試験
by
gree_tech
翻訳QAでのテスト自動化の取り組み
by
gree_tech
組み込み開発のテストとゲーム開発のテストの違い
by
gree_tech
サーバーフレームワークに潜んでる脆弱性検知ツール紹介
by
gree_tech
データエンジニアとアナリストチーム兼務になった件について
by
gree_tech
シェアドサービスとしてのデータテクノロジー
by
gree_tech
「ドキュメント見つからない問題」をなんとかしたい - 横断検索エンジン導入の取り組みについて-
by
gree_tech
「Atomic Design × Nuxt.js」コンポーネント毎に責務の範囲を明確にしたら幸せになった話
by
gree_tech
比較サイトの検索改善(SPA から SSR に変換)
by
gree_tech
コードの自動修正によって実現する、機能開発を止めないフレームワーク移行
by
gree_tech
「やんちゃ、足りてる?」〜ヤンマガWebで挑戦を続ける新入りエンジニア〜
by
gree_tech
法人向けメタバースプラットフォームの開発の裏側をのぞいてみた(仮)
by
gree_tech
DataEngConf NYC’18 セッションサマリー #1
1.
DataEngConf NYC’18 セッションサマリー #1 グリー開発本部
Meetup #1 2018/11/22 グリー株式会社 開発本部 DataEngineeringGroup 鈴木 隆史
2.
自己紹介 ■氏名:鈴木隆史 (@t24kc) ■所属:開発本部 データエンジニアチーム 応用人工知能チーム ■業務:GCP/AWS環境のデータ基盤開発 直近ではVTuberデータ基盤開発、社内BIツール開発、 機械学習ツール開発、チャットボット開発などを担当 2
3.
1. DataEngConfについて 2. セッション紹介#1 3.
セッション紹介#2 4. 感想 DataEngConfについて 3
4.
DataEngConf NYC’18について 4 https://www.dataengconf.com/nyc-event-2018
5.
■概要 ・データ基盤構築のツールやノウハウを共有するコミュニティイベント ・Facebook、Netflix、Lyftなど40以上の企業がスピーカー ・Hakka Labsがコミュニティベース ■日程 ・2018/11/08(木) -
09(金) ・コロンビア大学@NYC, USA ■参加者 ・400人近くの人が参加 DataEngConf NYC’18について 5
6.
イベント風景 6
7.
■カテゴリ ・Data Engineering ・Data Science・Analytics ・AI
Products ・Hero Engineering(少人数・低工数で大影響を与えたデータシステム) Sessionについて 7
8.
■ETTLプロセス @Datadog ・これまでのETLの課題について ・拡張したETTLプロセスについて ・Datadogで採用しているワークフローエンジンについて ■機械学習におけるデータリーク @Salesforce ・データリークとその問題点について ・データリークの検出判断基準と抑える方法について 本日のテーマ 8
9.
ETTLプロセス @Datadog 1. DataEngConfについて 2.
ETTLプロセス @Datadog 3. 機械学習におけるデータリーク @Salesforce 4. 感想 9
10.
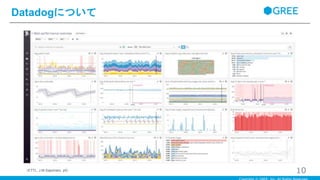
Datadogについて 10(ETTL, J.M.Saponaro, p5)
11.
■一元的な監視 ・マルチクラウドのスタック全体のサービス状態の一元的な監視 ■豊富な描画機能 ・多彩なビジュアライゼーションと、探索的なグラフ描画 ■機械学習ロジック ・複数のトリガーから検出された異常値を通知可能 主な特徴 11
12.
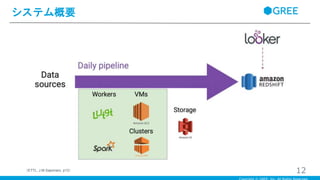
システム概要 12(ETTL, J.M.Saponaro, p13)
13.
対応データソース 13(ETTL, J.M.Saponaro, p11)
14.
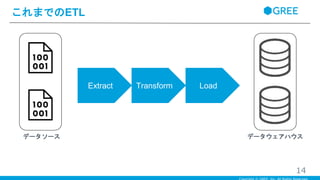
これまでのETL 14 データソース データウェアハウス Extract Transform
Load
15.
■データソース対応 ・常に変化し続け、複数のデータソースに対応する必要がある ■backfill ・過去データを楽にbackfillできること ■信頼性、堅牢性 ・長期間データ保持するにあたって必要 ■機密性 ・セキュリティ、コンプライアンスなどの要件 ETLで必要な基盤機能 15
16.
■データソース対応コスト ・データソースが増えたり、スキーマが変更された際のコスト高 ■タスク依存関係 ・特定のタスクが、別のタスクに強く依存している ・1つの障害がパイプライン全体の障害に繋がる ■backfillコスト ・1から計算し直すため、backfillの実行が長時間かかる ■定義configの肥大化 ・データ変換を定義する関数が、システムの拡大に伴って肥大化する これまでのETLの問題点 16
17.
■データソース対応コスト ・データソースが増えたり、スキーマが変更された際のコスト高 ■タスク依存関係 ・特定のタスクが、別のタスクに強く依存している ・1つの障害がパイプライン全体の障害に繋がる ■backfillコスト ・1から計算し直すため、backfillの実行が長時間かかる ■定義configの肥大化 ・データ変換を定義する関数が、システムの拡大に伴って肥大化する これまでのETLの問題点 17 これらの課題を解決する ETTLプロセスとワークフローについて
18.
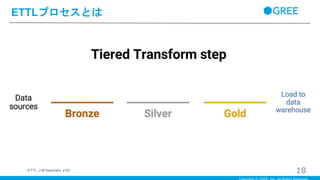
ETTLプロセスとは 18(ETTL, J.M.Saponaro, p19)
19.
■役割 ・すべてのデータソースから1つの場所に生データを集めること ・ここではフィルター、変換、名前変更は実行しない ・単純に構造化データとして集計するだけ ■メリット ・各データソースでタスク実行できるように抽象化 ・新しいデータセットを簡単に追加できる ・データを保持しているため、途中から再処理が可能 Bronze 19
20.
Bronze 20(ETTL, J.M.Saponaro, p22)
21.
■役割 ・オブジェクトを1:1にマッピングできるように正規化 ・フィルター、クリーニング、列の選択・操作、名前変更、型キャストを サポートしている ■メリット ・新しいデータソースの追加のコストを緩和できる ・変換が階層化しているため、Pipeline全体を修正する必要はない ・影響があるタスクからbackfillするだけで良い ・他のタスクでSilverを再利用することも可能 Silver 21
22.
Silver 22(ETTL, J.M.Saponaro, p25)
23.
■役割 ・Sparkを利用してDWHにロードする ・複数Silverデータの集計・変換にはSparkで分散処理 ・ここでの出力が最終的なオブジェクトとなる ・用途に応じた使い分け (truncate&insert, only insert,
replace, upsert) Gold 23
24.
Gold 24(ETTL, J.M.Saponaro, p27)
25.
■データソース対応コスト ・Bronzeでデータソースごとのタスクが抽象化し、追加が簡略化 ・スキーマ変更に対して、階層化した対象レイヤーのみの修正で完結 ■backfillコスト ・影響がある階層レイヤーからのbackfillで完結 ■信頼性、堅牢性 ・Bronzeで生データ保持しているため、長期間のデータ信頼性や、再処理も 可能 ETTLによるこれまでの課題解決 25
26.
■タスク依存関係 ・タスク分解しても依存関係問題は存在する ・Datadogでは30以上の依存関係上で、370程度のタスクが存在する ・依存関係が深くなるほど運用コストは肥大化する ETTLで解決できない課題 26
27.
■タスク依存関係 ・タスク分解しても依存関係問題は存在する ・Datadogでは30以上の依存関係上で、370程度のタスクが存在する ・依存関係が深くなるほど運用コストは肥大化する ETTLで解決できない課題 27 タスク依存関係解決に用いられた ワークフローエンジンについて
28.
■概要 ・Python製のスクリプト型ワークフローエンジン ・タスク間のロジック定義で依存関係を解決 ・エラー発生で処理停止、途中から再実行可能 ・出力の有無で冪等性を担保 ・Hadoop、BigQuery、各クエリエンジンと連携可能 Luigiについて 28
29.
■Task ・処理の最小単位 ■Target ・Taskの出力対象のこと (S3、HDFSなど) ■Parameter ・Taskの引数として与えることができる情報 (日付や期間など) Luigi内部用語 29
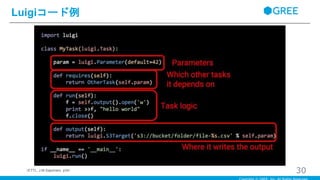
30.
Luigiコード例 30(ETTL, J.M.Saponaro, p34)
31.
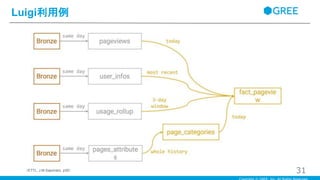
Luigi利用例 31(ETTL, J.M.Saponaro, p35)
32.
■タスク依存関係 ・Luigiを利用することで、データの冪等性や依存関係をサポート Luigiによるこれまでの課題解決 32
33.
■ETTLについて ・弊社では、データソースが複数に跨ることが少なく データソースに適した少数のDWHを構築 ・一元的なDWHやBIツール開発には ETTLのような階層タスク管理が必要 所感#1 33
34.
■ワーフクローについて ・宣言型ワークフローについて ・DigdagやAzkabanを利用し、SQLでETLすることが多い ・SQLの場合は非ENも対応でき、日付変刻した定形クエリを再実行でき るので対応工数低いのがメリット ・スクリプト型ワークフローについて ・タスク間の依存関係が複雑な場合にメリット ・変換も柔軟に対応できる ・場所によって宣言型とスクリプト型の使い分けが有効 所感#2 34
35.
■スピーカー Jean-Mathieu Saponaro Data Engineer
& Internal Analytics Team Lead ■セッション https://www.dataengconf.com/speaker/extract-tiered-transform-load-a-pipeline-for-a-modular-scalable- and-observable-internal-analytics-platform 出典 35
36.
機械学習におけるデータリーク @Salesforce 1. DataEngConfについて 2. ETTLプロセス
@Datadog 3. 機械学習におけるデータリーク @Salesforce 4. 感想 36
37.
Salesforceについて 37(Hindsight Bias,Till Bergmann,
p2)
38.
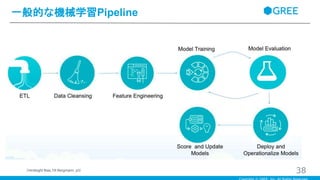
一般的な機械学習Pipeline 38(Hindsight Bias,Till Bergmann,
p3)
39.
Pipelineの肥大化 39(Hindsight Bias,Till Bergmann,
p4)
40.
Pipelineの肥大化 40(Hindsight Bias,Till Bergmann,
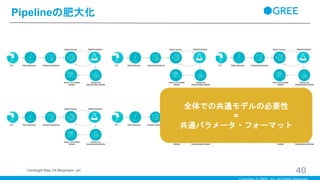
p4) 全体での共通モデルの必要性 = 共通パラメータ・フォーマット
41.
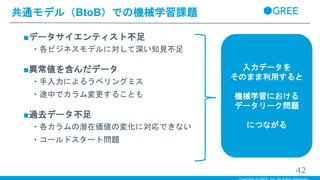
■データサイエンティスト不足 ・各ビジネスモデルに対して深い知見不足 ■異常値を含んだデータ ・手入力によるラベリングミス ・途中でカラム変更することも ■過去データ不足 ・各カラムの潜在価値の変化に対応できない ・コールドスタート問題 共通モデル(BtoB)での機械学習課題 41
42.
■データサイエンティスト不足 ・各ビジネスモデルに対して深い知見不足 ■異常値を含んだデータ ・手入力によるラベリングミス ・途中でカラム変更することも ■過去データ不足 ・各カラムの潜在価値の変化に対応できない ・コールドスタート問題 共通モデル(BtoB)での機械学習課題 42 入力データを そのまま利用すると 機械学習における データリーク問題 につながる
43.
■予測時に利用できるデータ、できないデータ ・予測時に知りえない情報を学習すると、モデル性能が悪化 機械学習におけるデータリーク 43
44.
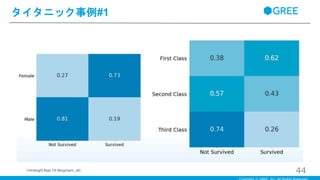
タイタニック事例#1 44(Hindsight Bias,Till Bergmann,
p8)
45.
タイタニック事例#1 45(Hindsight Bias,Till Bergmann,
p8) 予測時に利用できる
46.
タイタニック事例#2 46(Hindsight Bias,Till Bergmann,
p9)
47.
タイタニック事例#2 47(Hindsight Bias,Till Bergmann,
p9) 予測時に利用できない
48.
コンバージョン事例#1 48(Hindsight Bias,Till Bergmann,
p17)
49.
コンバージョン事例#1 49(Hindsight Bias,Till Bergmann,
p17) ReasonLost = no Conversion
50.
コンバージョン事例#1 50(Hindsight Bias,Till Bergmann,
p17) Amount = Conversion
51.
コンバージョン事例#1 51(Hindsight Bias,Till Bergmann,
p17) ClosedBy ≒ Conversion
52.
■精度問題 ・データリークの特徴量を訓練時に利用してしまうと、訓練時には高い精度 が出るが、予測時には精度が全く出ない ■問題となるケース ・企業データなどの過去データがなかったり、時系列情報がない場合 ・マスターテーブルの値が特定トリガーで途中変更がある場合 ・データセット全体で標準化、正規化を実施した場合 データリークの問題点 52
53.
■分割クロスバリデーション、ホールドアウト ・原則的に訓練、テスト、検証データを分割して保持 ・分割データごとにパラメータは再計算する必要あり ・外れ値除去、次元削減、特殊選択も再処理 データリークを抑える方法 53
54.
■全体のNULL率判定 ・訓練データで非NULLでも、検証時にNULLのデータが多いときは削除 ■精度の差 ・訓練精度と検証精度の差が大きいときは、意図しない特徴量が含まれてい る可能性あり ■日付パラメータ ・学習データの日付に乖離がある場合は、モデル精度がずれる可能性がある データリーク特徴量の削除基準 54
55.
■全体のNULL率判定 ・訓練データで非NULLでも、検証時にNULLのデータが多いときは削除 ■精度の差 ・訓練精度と検証精度の差が大きいときは、意図しない特徴量が含まれてい る可能性あり ■日付パラメータ ・学習データの日付に乖離がある場合は、モデル精度がずれる可能性がある データリーク特徴量の削除基準 55 削除閾値を設ける必要性
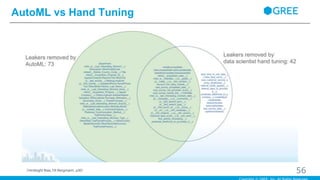
56.
AutoML vs Hand
Tuning 56(Hindsight Bias,Till Bergmann, p30)
57.
■全体のモデル最適化を優先 ・1つのモデルに特化して最適化をするのでく、 数千の全体の精度を悪化させない閾値を設ける ■閾値選択 ・残すべき特徴量と、除去するべき特徴量の閾値判断が難しくなる ■多くの試行錯誤 ・アルゴリズムに変換できるヒューリスティックな手法も時には必要 共通モデル利用時の方針 57
58.
■時系列データの重要性 ・自社に時系列のデータを保持している場合は、素直にデータリーク特徴量 を削除できる ・企業データのような過去・時系列データがない場合には、データリーク特 徴量の除去に試行錯誤しそう ■共通モデルの難しさ ・全体のモデル最適化の特徴選択には、経験則が必要になりそう 所感 58
59.
■スピーカー Till Bergmann Data Scientist ■セッション https://www.dataengconf.com/speaker/hindsight-bias-how-to-deal-with-label-leakage-at-scale 出典 59
60.
感想 1. DataEngConfについて 2. ETTLプロセス
@Datadog 3. 機械学習におけるデータリーク @Salesforce 4. 感想 60
61.
■変化し続けるデータ ・データの急成長・多様化の共通メッセージが強調されていた ・データ基盤やデータサイエンスや機械学習の分野でも データの変化に柔軟に対応していく必要性がある 感想 61
62.
Thank you 62
Editor's Notes
#6
・日本人は殆どいなく、日本コミュニティは見た限りなかった
#7
・コロンビア大学やイベントの写真 ・イベント中は宇宙食という名のケータリングを食べられた
#8
・1日あたり8回のKeynote/Sessionの公演があった ・大枠でDataEngineering、DataScience・Analytics、AI Products、Hero Trackという4つのSessionに分かれている ・Hero Engineeringとは、少人数・低工数で多くの影響を与えたデータシステムの紹介 ・大規模なカンファレンスとは異なり、1企業のメインスピーカーがあるのではなく、各企業からスピーカーが選出されている ・そのため、Keynoteはサマリな内容ではなくでは、他Sessionと同様に1つの企業からの取り組みの紹介がされていた
#9
・データエンジニアリング系から1つ、機械学習系から1つピックアップして紹介する ・その中で企業の知名度があり、セッション難易度がほど良い感じのものを選んだ
#11
・スタック全体からリアルタイムに詳細なメトリック監視を行うことができる運用監視クラウドサービス
#13
・データフローにはLuigi、分散処理にはSpark、DWHにはRedshift、BIツールにはLookerを利用 ・1日あたり1兆を超えるシステムログやリクエストを捌いている
#14
・40を超えるデータソースから取得することができる ・インフラデータ、サービストラフィック、売上情報、インフラコストなど
#15
・ほとんどの企業では、オペレータがDataを取り出し巨大なコードに変換してDWHに出力するETLプロセスを保持している
#19
・DatadogではETLを拡張したETTL(Extract Tiered Transform Load)プロセスを採用している ・Tiered Transformとはデータの階層化変換のことで、一度にデータの変換をするのではなく、いくつかのステップに分けてデータの変換を行う ・ブロンズ、シルバー、ゴールドの3つのステップに分解している ・原則的に各ステップの中間データはS3に保存される ・途中のパイプラインのデータは保持して、繰り返しジョブが実行できるようになっている
#20
・すべてのデータソースから1つの場所に生データを集めること(主にS3に保存) ・ここではフィルター、変換、名前の変更などは実施しない ・単純に構造化データとして集計するだけ ・メリット ・データソースごとに1つの基本タスクを実行するように抽象化しているため、新しいデータセットを簡単に追加できる ・データを保持しているため、それ以降の処理に問題がある場合、ブロンズから処理をやり直すことができる
#21
・各データソースから、データを構造化して保存している
#22
・オブジェクトを1:1にマッピングできるように正規化する ・フィルター、データクリーニング、列の選択・操作、名前の変更、型キャストをサポートしている ・メリット ・新しいデータソースのカラム変更に対して、同じフォーマットになるようにオブジェクトを変換する ・データが変化した場合は、変換を階層化しているため、影響があるジョブからbackfillするだけで済む ・パイプライン全体を修正する必要はなく、新しいデータソースの変更による問題を緩和できる ・他タスクでシルバー関数を再利用することもできる
#23
・Bronzeで構造化したデータを型キャストや名前変更など、正規化しているのが分かる
#24
・Sparkを利用してSilverのデータを集計してDWHにロードする ・ここの複数レイヤーからデータ集計・変換にマシンパワーが必要なのでSparkを利用して分散処理 ・ここでの出力が最終的にDWHで利用するオブジェクトを含んでいる ・import方針として、truncate&insert、insert only、replace、upsertをサポートしている
#25
・Silverデータを集計・変換してGoldに出力している
#26
・複数の変化するデータソースへの対応 ・データソースごとに1つの基本タスクを実行するように抽象化しているため、新しいデータセットを簡単に追加できる ・新しいデータソースのカラム変更に対して、同じフォーマットになるようにオブジェクトを変換する ・パイプライン全体を修正する必要はなく、新しいデータソースの変更による問題を緩和できる ・過去データのbackfillのしやすさ ・変換を階層化しているため、影響があるジョブからbackfillするだけで済む ・長期間データの信頼性、堅牢性 ・各レイヤーでデータを保持しているため、それ以降の処理に問題がある場合、ブロンズから処理をやり直すことができる ・セキュリティ、コンプライアンスなどの要件をクリアできる機密性 ・クラウドではIAMソリューション設定、BIツールでは権限設定をすればコントロールすることができる
#27
・このようにTransformを階層化し、タスク分解しているが、依存関係の問題は依然として存在する ・Datadogでは30以上の依存関係の中に、370程度のタスクによってDWHを構築している ・依存関係が深くなるほど、システムのメンテナンスコストが上がってしまう
#28
・そのため、ワーフフローエンジンを利用してタスク依存関係を解決する
#29
・Spotifyが開発したデータフロー制御のワークフローエンジンがOSS化したもの ・Luigiの利用によりタスクの依存関係の問題を緩和させることができる ・特徴 ・Pythonで定義され、複数のバッチ処理を組み合わせたジョブを制御できる ・タスク間のロジックを定義することで依存関係を解決できる ・エラーが発生したら処理を停止し、失敗したところから再開できる ・出力の有無で冪等性を担保できる ・プラットフォームに依存しないため、HadoopやBigQuery、各種クエリエンジンとの連携が可能 ・範囲外(記載しない) ・リアルタイム処理、分散処理、スケジュール起動、トリガ起動 ・あくまでも司令塔としての役割
#31
・OtherTaskを親に持つ ・hello worldを出力して(ここでデータの変換などが可能) ・s3のbucketにアウトプット ・Datadogでの使い方 ・Datadogでは1データソースに1基盤クラス ・各Task特有のパラメータで定義できるライブラリを開発して利用している
#32
・このように複雑な依存関係もLuigiを利用することで簡易管理できる
#34
・弊社でも、生データから中間テーブルを作成して、その後に再度集計してデータマート用のテーブルを作成することはある ・とはいえ、データソースが複数に跨ることは少なく、各データソースごとに最適なDWHを利用している ・DWHを一元管理するためには、ETTLのような管理が必要になってくるだろう
#35
・弊社では、DigdagやAzkabanなどの宣言型のワークフローエンジンを利用している ・特にSQLでETL対応していることが多い ・SQLの場合は、日付パラメータを変更した定形クエリを何度も実行することが多いため、宣言型のほうが対応工数は小さくなることが多い ・クエリの場合は、非ENであっても対応できるのもメリット ・Luigiなどのスクリプト型のワークフローは、状態処理やスクリプト中の変換などが容易 ・スクリプト定義ができるので、タスク間の依存関係が複雑な場合も有効 ・クエリではない、ETLプロセスの場合はスクリプト型のワークフローだと柔軟に対応できる ・場所によってワーフフローを使い分けるのも良さそう
#38
・クラウド型の顧客管理や営業管理などのビジネスアプリケーションを提供するSaaS
#39
・ETLでデータを集計して、前処理で外れ値の除去、次元削減、特徴選択をし、訓練データと検証データに分けてモデルを作成して、精度を検証して、本番にdeployして精度を確認して、またモデルを更新する
#40
・15万社以上の企業が、Salesforceのアプリケーションを利用している ・そのため、各企業ごとのユースケースにあったモデルを作成しようと思うと、非常に工数がかかる ・1つ1つに専用のモデルを作成するのではなく、全体で共通のモデル作成する必要性が出てきている ・共通モデルを利用するためには、共通のデータフォーマットやパラメータを利用する必要がある
#41
・15万社以上の企業が、Salesforceのアプリケーションを利用している ・そのため、各企業ごとのユースケースにあったモデルを作成しようと思うと、非常に工数がかかる ・1つ1つに専用のモデルを作成するのではなく、全体で共通のモデル作成する必要性が出てきている ・共通モデルを利用するためには、共通のデータフォーマットやパラメータを利用する必要がある
#42
・全体で共通モデルを利用したいが、企業によってデータはバラバラ ・データサイエンティスト不足 ・各ビジネスモデルの深い知見の不足 ・各パイプラインの自動化ができていない ・常に変化し、異常値を含んだデータ ・手入力によるラベリングミス ・途中でカラム変更することがある ・過去のデータがない ・各カラムの潜在価値の変化を把握できない ・コールドスタート問題
#43
・かといって、入力されているデータをそのまま学習データに利用すると問題が発生する ・それは、時系列ではないため答えとなるカラムが存在するデータを学習に利用してしまっているから ・このような問題をデータリーク問題という
#44
・予測時に利用できるデータ、できないデータが存在する ・予測時には知りえない情報を学習に利用してしまうと、モデルの性能が著しく悪くなってしまう ・企業データのように、時系列でなかったり、急にマスターデータとして登録される場合に発生しやすい ・一つ一つ別のモデルにする場合は、データを確認すればデータリークのカラムを判断できるが、共通モデルで何千もの予測をするモデルであると確認が困難になる
#45
・性別と生存率、客室クラスと生存率の関係のヒートマップグラフ
#46
・性別と生存率、客室クラスと生存率の関係のヒートマップグラフ
#47
・身体識別番号と生存率、救命艇番号と生存率の関係 ・一見、生存率と非常に高い因果関係があるように見えるが、これらの番号は、亡くなった後や救助船に乗った後に決まったデータ ・データとして見るのは問題ないが、これらのデータは事前には分からない ・事後にしか確認できないデータを訓練データとして利用すると、トレーニング時に高い精度が出たとしても、予測時には精度が出ない
#48
・身体識別番号と生存率、救命艇番号と生存率の関係 ・一見、生存率と非常に高い因果関係があるように見えるが、これらの番号は、亡くなった後や救助船に乗った後に決まったデータ ・データとして見るのは問題ないが、これらのデータは事前には分からない ・事後にしか確認できないデータを訓練データとして利用すると、トレーニング時に高い精度が出たとしても、予測時には精度が出ない
#49
・一見関係ないようなデータもデータリークに繋がっていることがある、その例を紹介する
#50
・ReasonLostはコンバージョンしなかったと同意
#51
・Amountはコンバージョンしたと同意
#52
・ClosedByはコンバージョンしたと類似
#53
・企業データの共通モデル作成時に、時系列の情報がなかったり過去データがなかったりする場合は、どこに正解に紐付いたデータが潜んでいるか分からない ・訓練時には高い精度が出ても、予測時には全く精度が出ない ・overfittingと似ているが微妙に違っている 問題となるのは、 ・企業データなどの過去データがなかったり、時系列情報がない場合 ・マスターテーブルの値が、特定トリガーで途中で変更がある場合 ・データセット全体を正規化・標準化してクロスバリデーションを実施すると、データリークしたことになる(意外と陥りやすい) ・平均値、最大値、標準偏差などのスケーリング係数が、訓練データの全体分布が共有されてしまう
#54
まず一般的な方法だが ・分割クロスバリデーションでデータ準備をする ・全体で標準化しないように、分割データごとにパラメータを計算して、テストデータを準備するのもOK ・外れ値の除去、次元削減、特徴選択などのタスクを含むクロスバリデーション内では、パラメータを再計算するのがよい ・全データの特殊選択を行った値でクロスバリデーションをすると、検証データにもその特殊選択が利用されてパフォーマンス分析に偏りが発生する ・検証データセットを保持する ・訓練データとテストデータと検証データに分割し、検証データセットを保持する方法もある ・モデル作成には訓練データとテストデータを利用して、最終モデルは検証データを利用する
#55
次に特徴選択について エンタープライズデータなどの過去データや時系列判定ができない場合 ・全体のNULL率が高い ・訓練データで非NULLでも検証時にNULLデータが多いカラムは削除する ・訓練精度と検証精度の差が激しい ・精度の差があるときは意図しないカラムが含まれている可能性が高い ・確率分布に変換して比較すると判定しやすい ・日付が大幅にずれているもの ・学習データの日付が離れている場合、モデルがずれる可能性があるので、日付データはまとめる
#56
・全体で共通のモデルを利用しているため、個別に敷地を設けるのではなく、全体で共通の閾値を設ける必要がある ・Salesforceではこのような閾値定めた動的特徴選択エンジンを動かしている
#57
・これまでの特徴量基準による特徴選択を実施した動的特徴量削除モデルと、人が手動で特徴選択したモデルのカラムについてのグラフ ・AutoMLでもHand Tuningでも共通のカラムが多く、実サービスでも十分に利用できる ・必ずしもAutoMLの選択したカラムが正しいわけではないが、AutoMLで選択したカラムを見て人が気づきを得ることも多い
#58
・全体でのモデル最適化を優先 ・1つのモデルでの最適化ではなく、数千の精度を悪くするような閾値を選ばない ・閾値選択は難しい ・良い特徴量と、除去するべき特徴量の閾値判定 ・多くの試行錯誤 ・アルゴリズムに変換できるヒューリスティックな手法が必要となることもある
#59
・時系列データの重要性 ・Salesforceのように企業データを利用する場合は、データリークカラムの除去に試行錯誤している ・弊社でモデルを作成する際は、基本的に多くのログを保持しているため、素直に予測時に利用できないカラム除去が重要 ・共通モデルの難しさ ・1つのモデルでの最適化は決して難しくないが、全体で共通のモデルの精度を向上させる場合のデータリークは問題になる ・時系列判断が難しい場合の、不要カラム削除の閾値判断はヒューリスティックな判断も必要になりそう
Download


















































![[Livesence Tech Night] グリーにおけるHiveの運用](https://cdn.slidesharecdn.com/ss_thumbnails/livesencetechnight-150602053505-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[db tech showcase Tokyo 2016] B15: サイバーエージェント アドテクスタジオの次世代データ分析基盤紹介 by 株式会社サイ...](https://cdn.slidesharecdn.com/ss_thumbnails/6i9kohhirrcoablwy2vg-signature-de1723da869232faf642797bf4411177191c3ef937923c1c3c4b18848e6dd30c-poli-160721053413-thumbnail.jpg?width=640&height=640&fit=bounds)









































