Download as PDF, PPTX

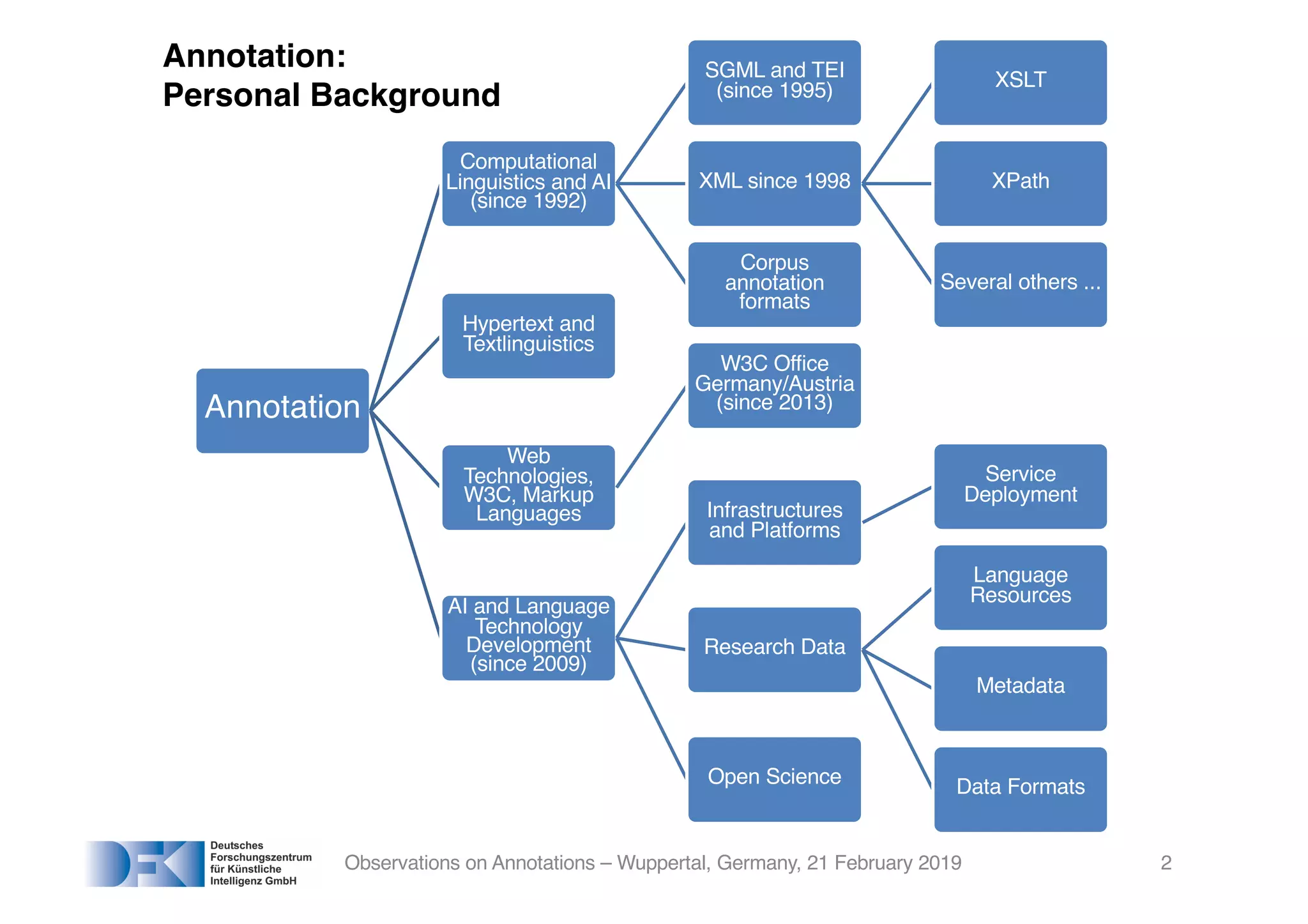



![Annotations
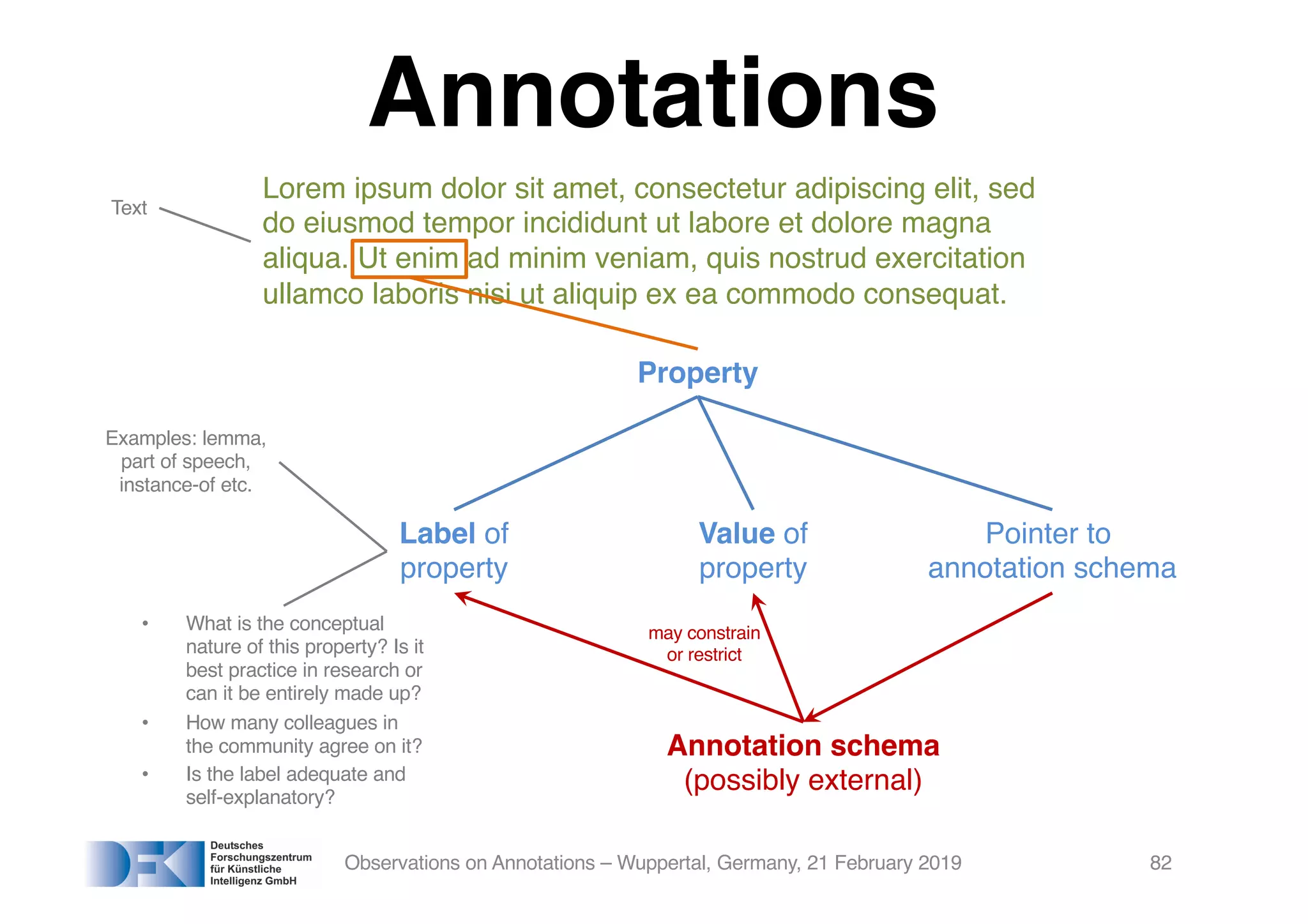
• Definition/“Definition”:
Secondary data added to a piece of primary data –
in science, this is, often, research data.
• Wikipedia:
An annotation is a metadatum (e.g., a post, explanation,
markup) attached to [a?] location or other data.
http://www.merriam-webster.com
Observations on Annotations – Wuppertal, Germany, 21 February 2019 6](https://image.slidesharecdn.com/wuppertal-final-distribution-190223102214/75/Observations-on-Annotations-From-Computational-Linguistics-and-the-World-Wide-Web-to-Artificial-Intelligence-and-back-again-6-2048.jpg)
![• Literature and education:
– Textual scholarship: Textual scholarship is a discipline that often
uses the technique of annotation to describe or add additional
historical context to texts and physical documents.
– Learning and instruction: As part of guided noticing [annotation]
involves highlighting, naming or labelling and commenting
aspects of visual representations to help focus learners' attention
on specific visual aspects. In other words, it means the assignment
of typological representations (culturally meaningful categories),
to topological representations (e.g. images).
• Software engineering:
– Text documents: Markup languages like XML and HTML annotate
text in a way that is syntactically distinguishable from that text.
They can be used to add information about the desired visual
presentation, or machine-readable semantic information, as in
the semantic web.
• Linguistics:
– In linguistics, annotations include comments and metadata; these
non-transcriptional annotations are also non-linguistic.
Observations on Annotations – Wuppertal, Germany, 21 February 2019 7](https://image.slidesharecdn.com/wuppertal-final-distribution-190223102214/75/Observations-on-Annotations-From-Computational-Linguistics-and-the-World-Wide-Web-to-Artificial-Intelligence-and-back-again-7-2048.jpg)









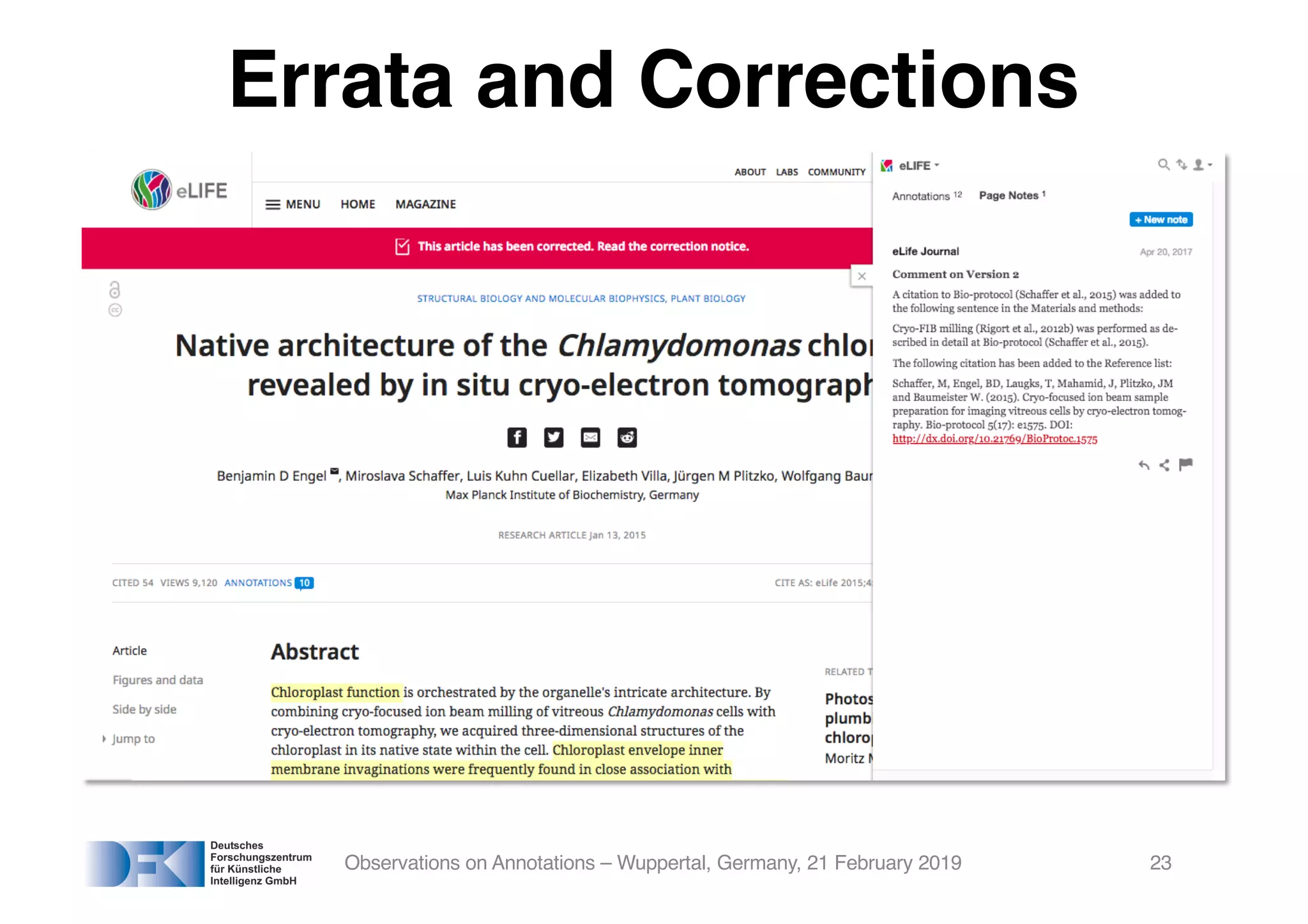

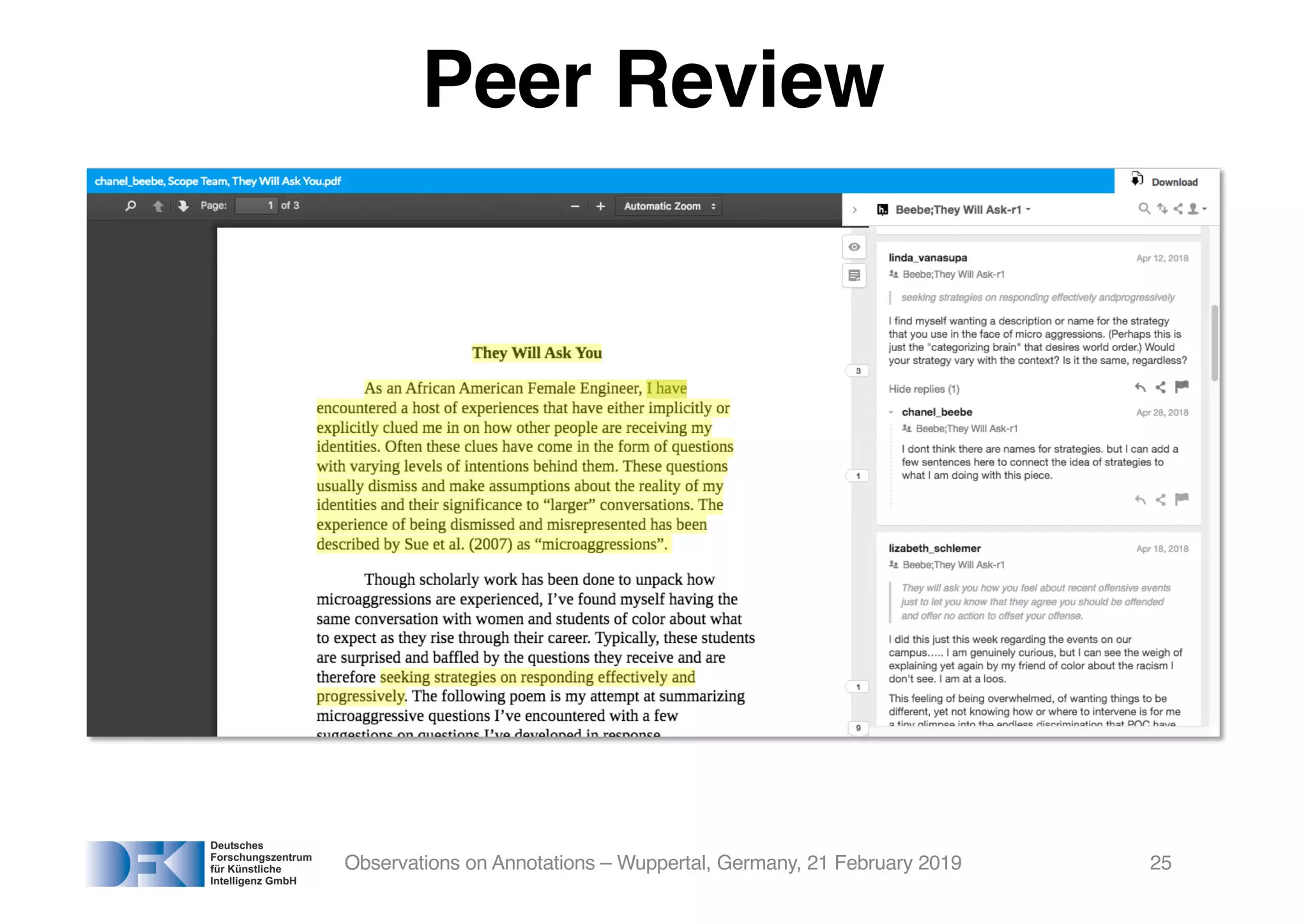

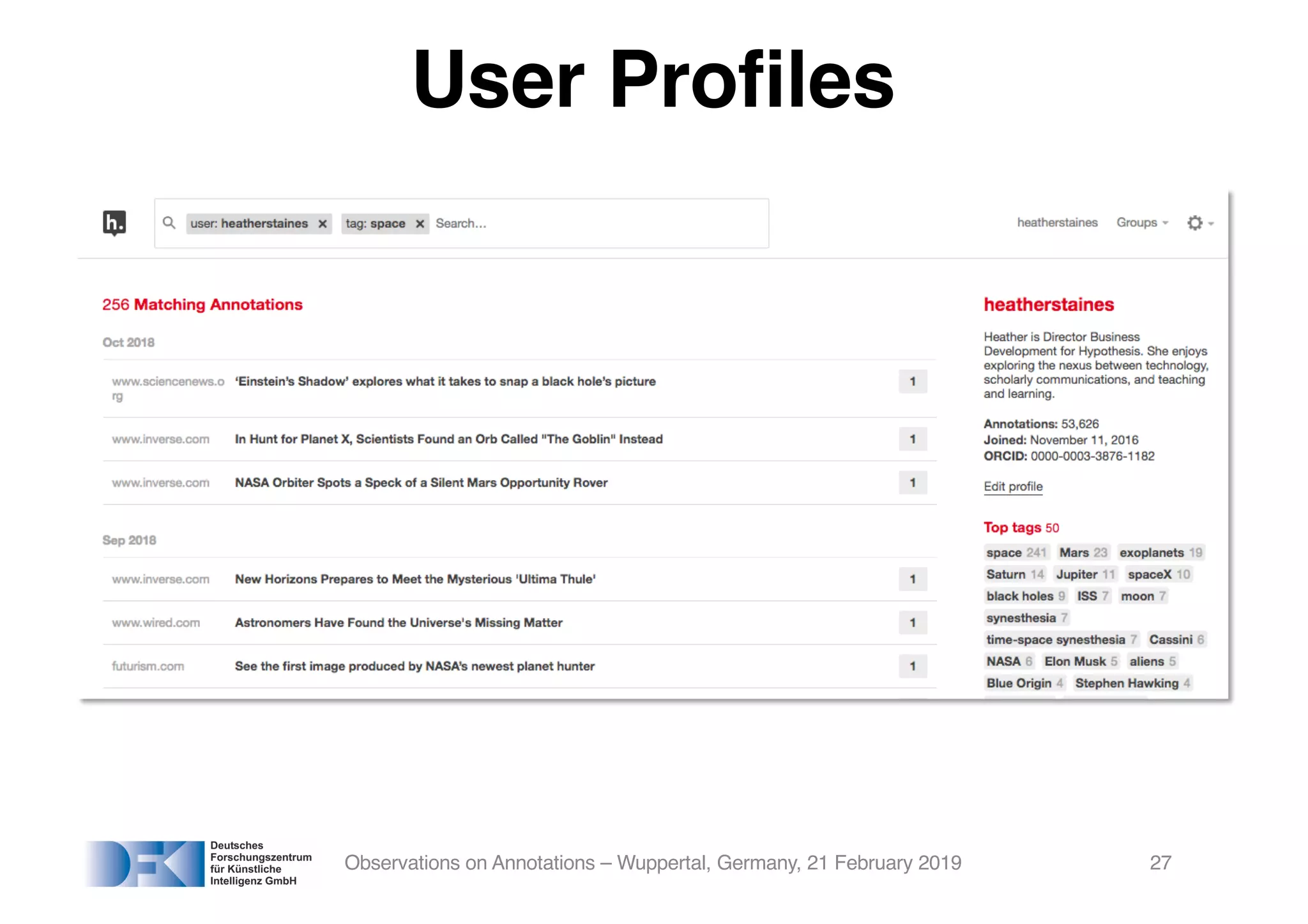


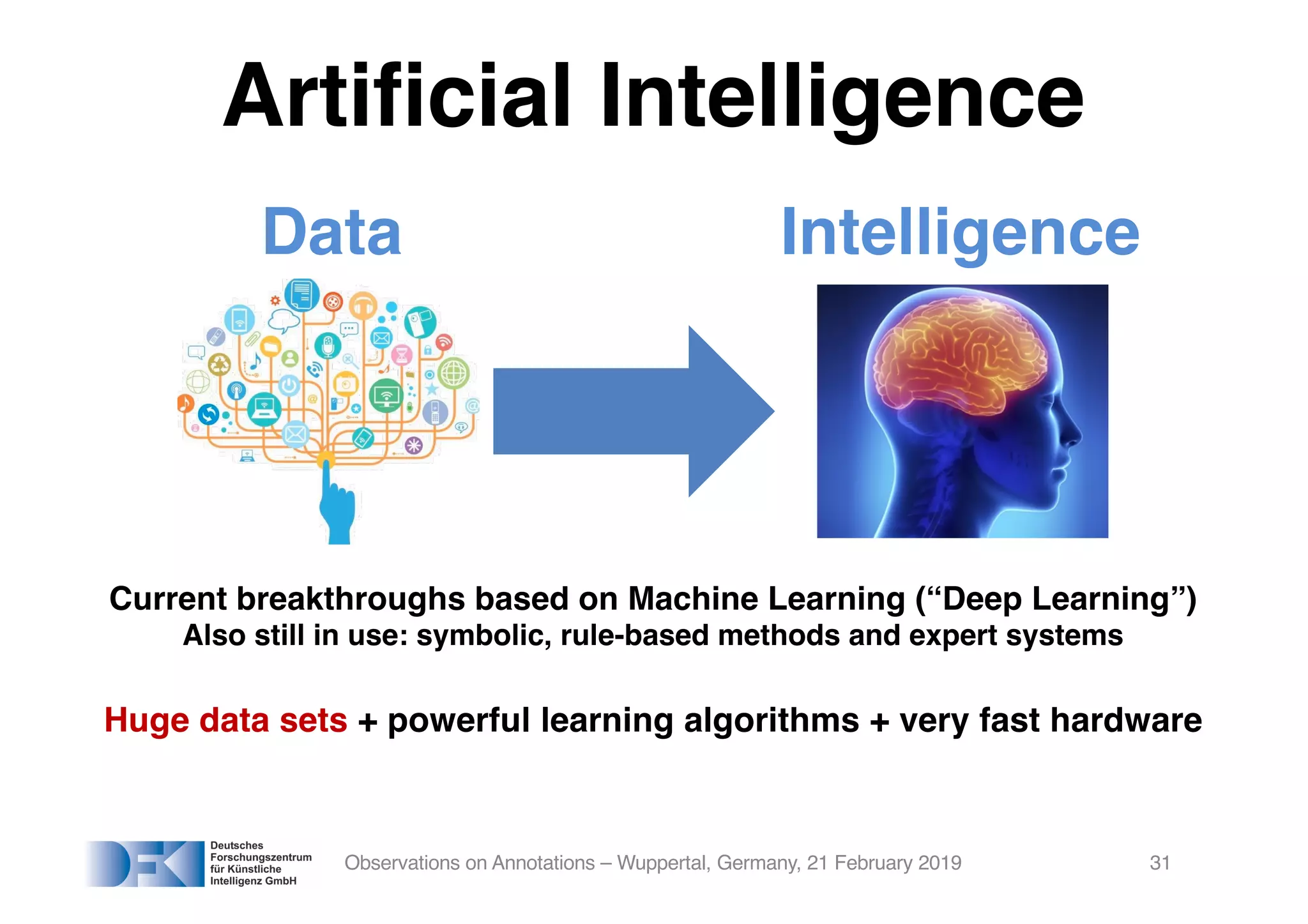




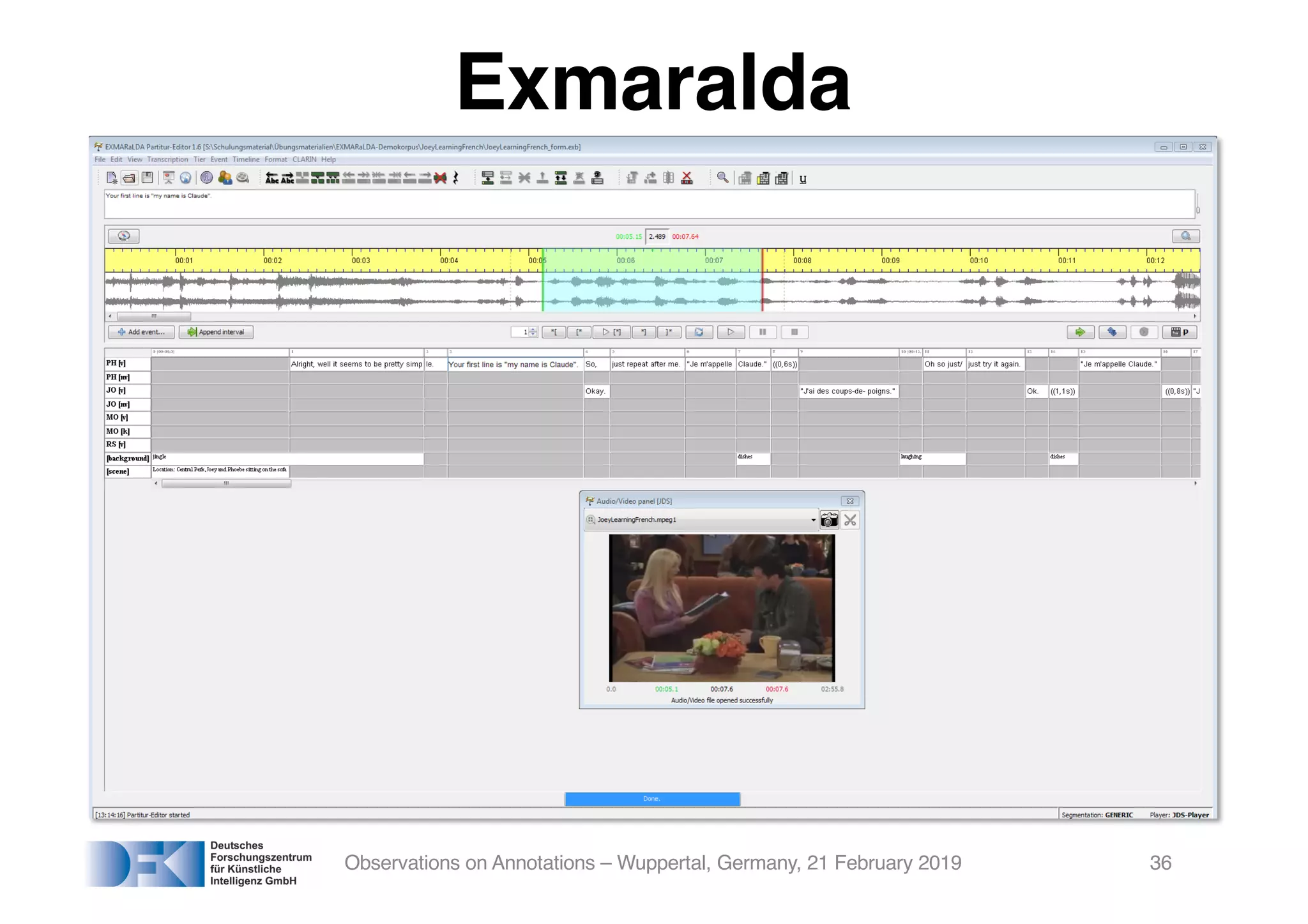
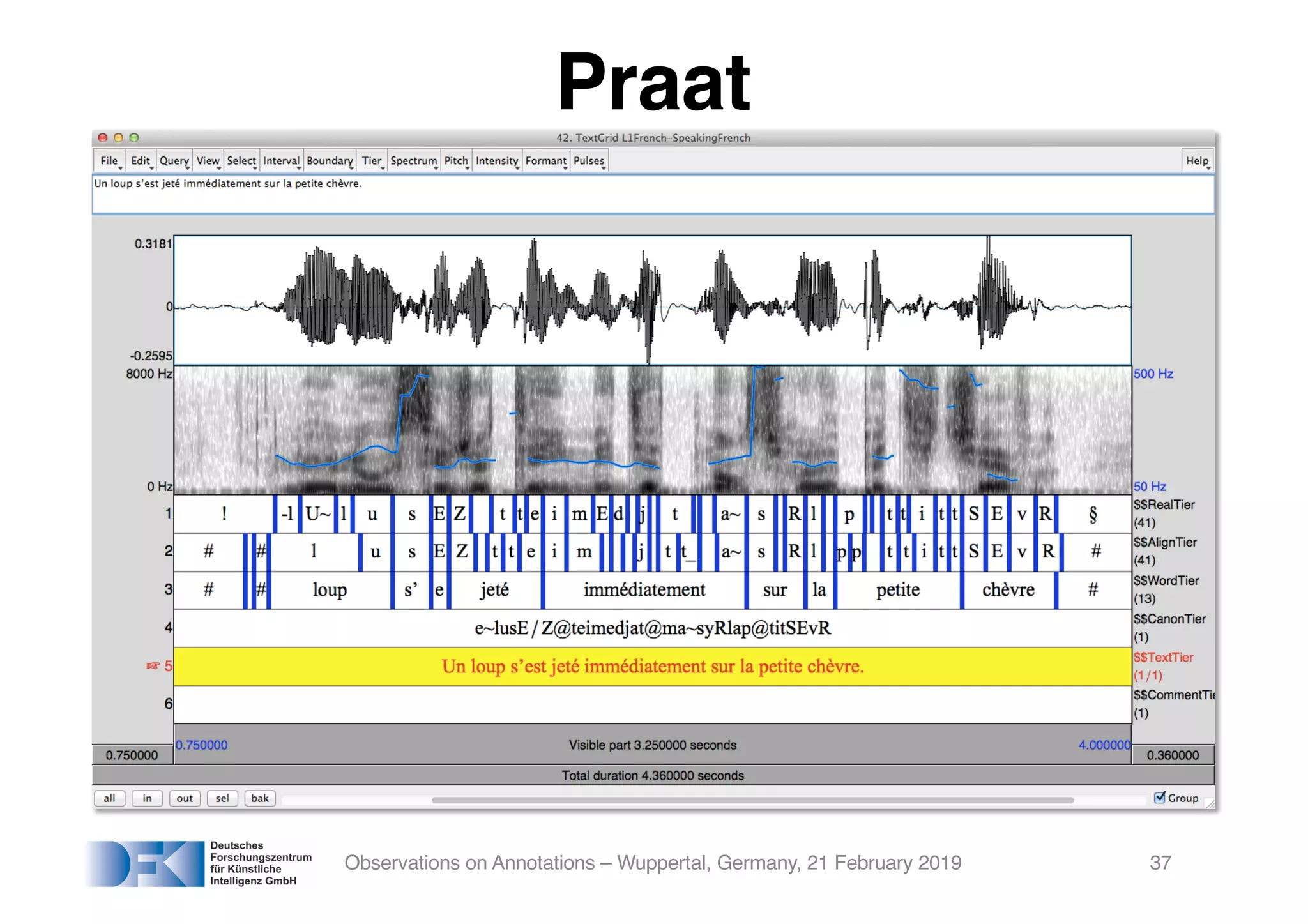
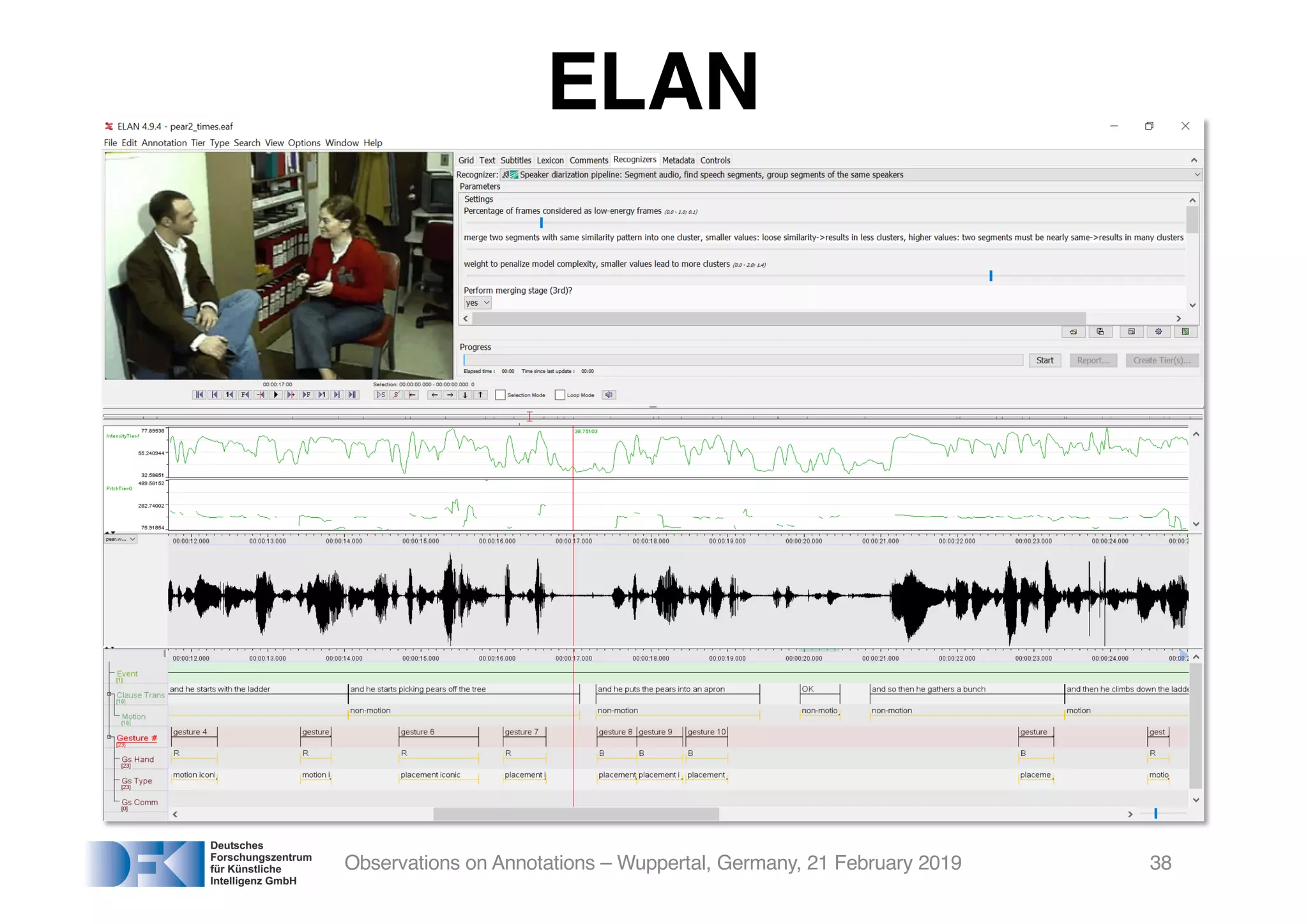
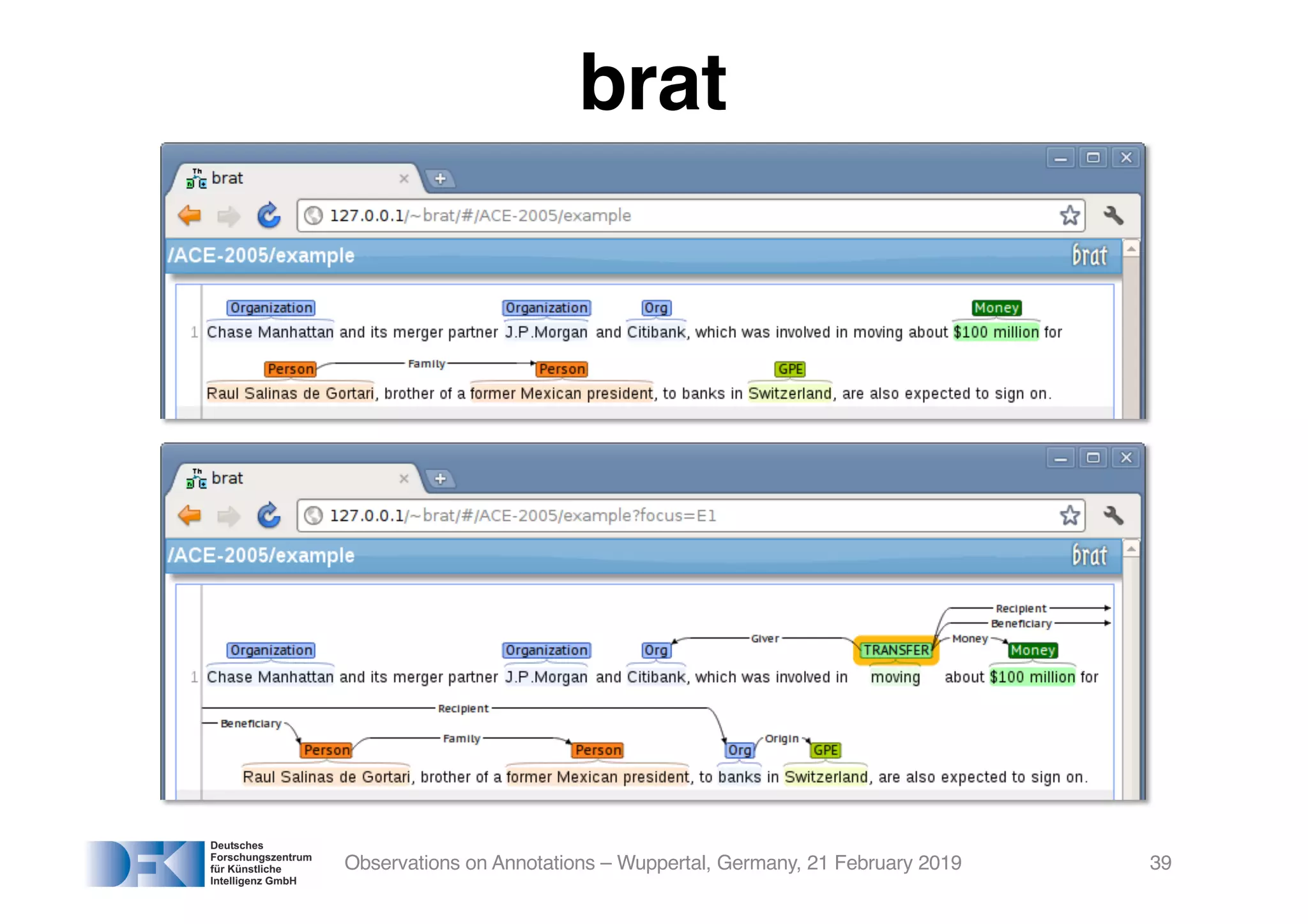

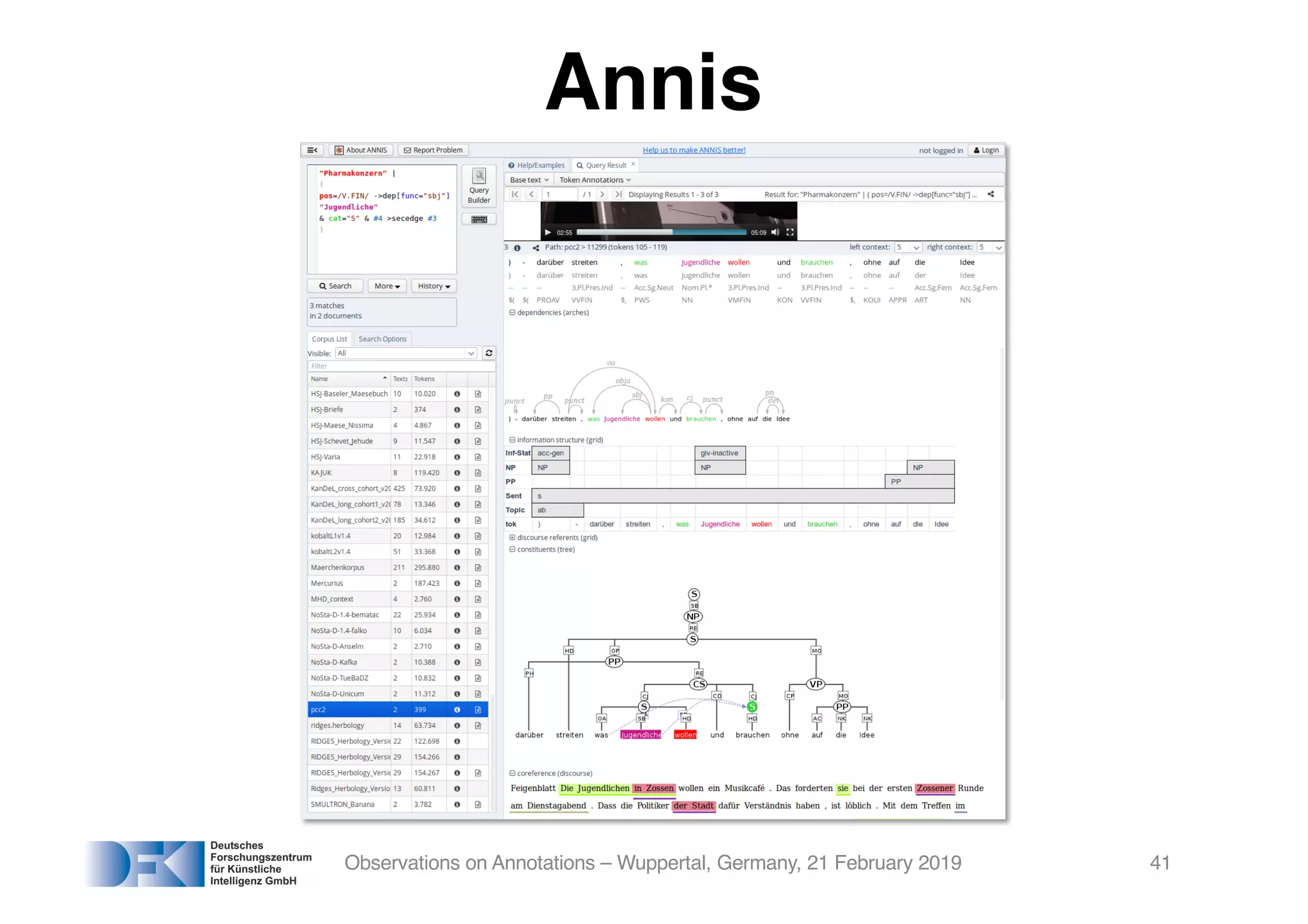


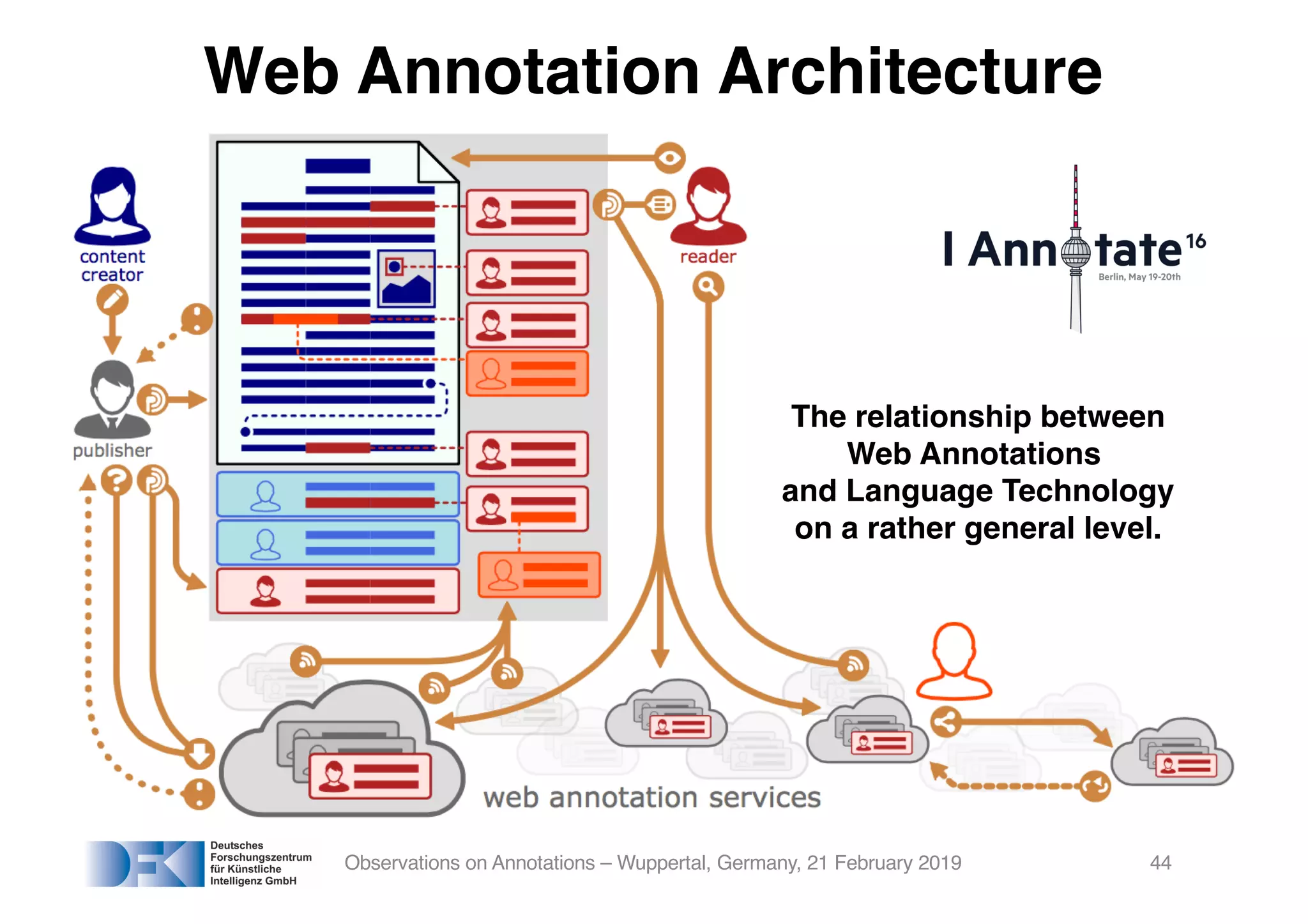
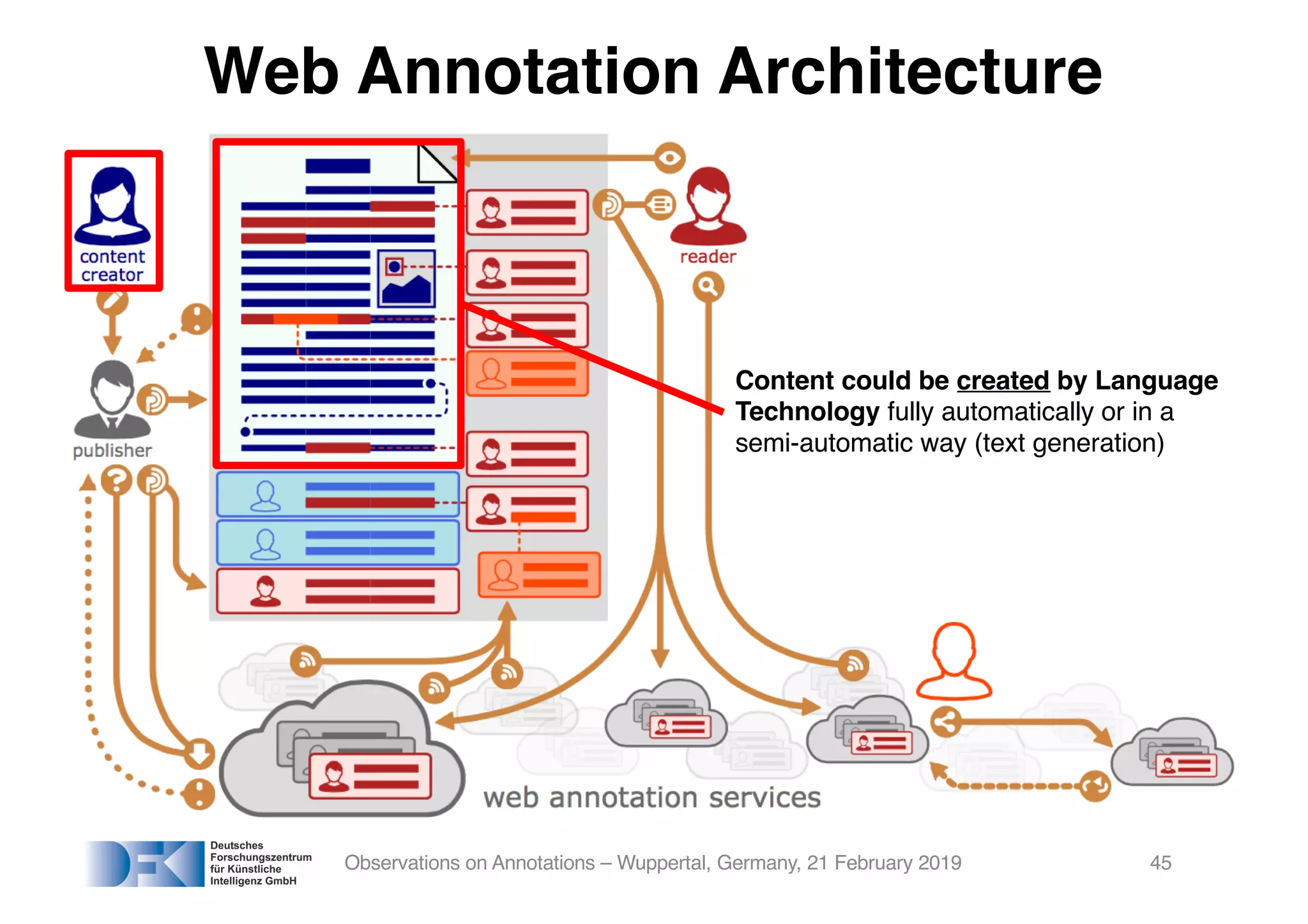
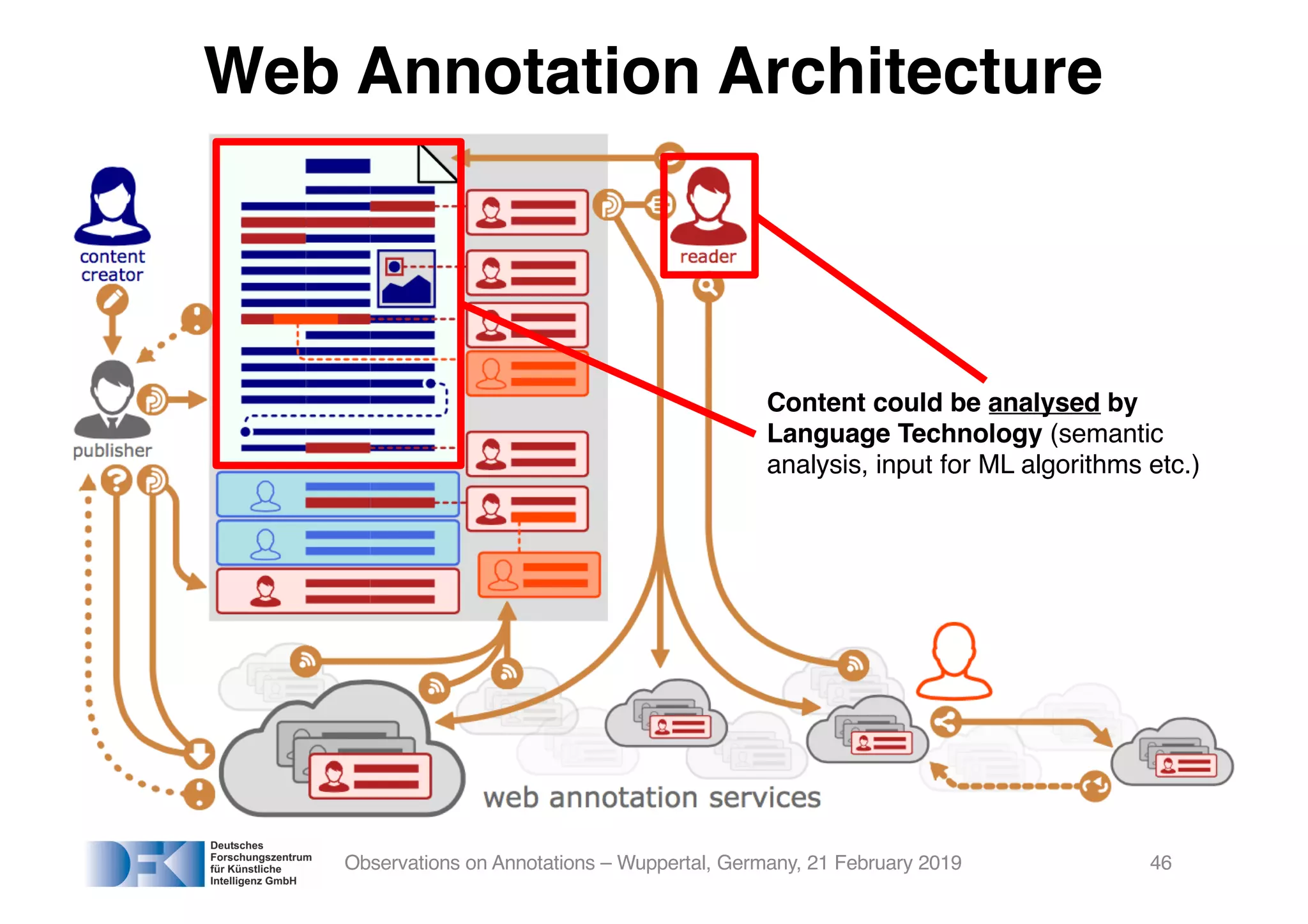
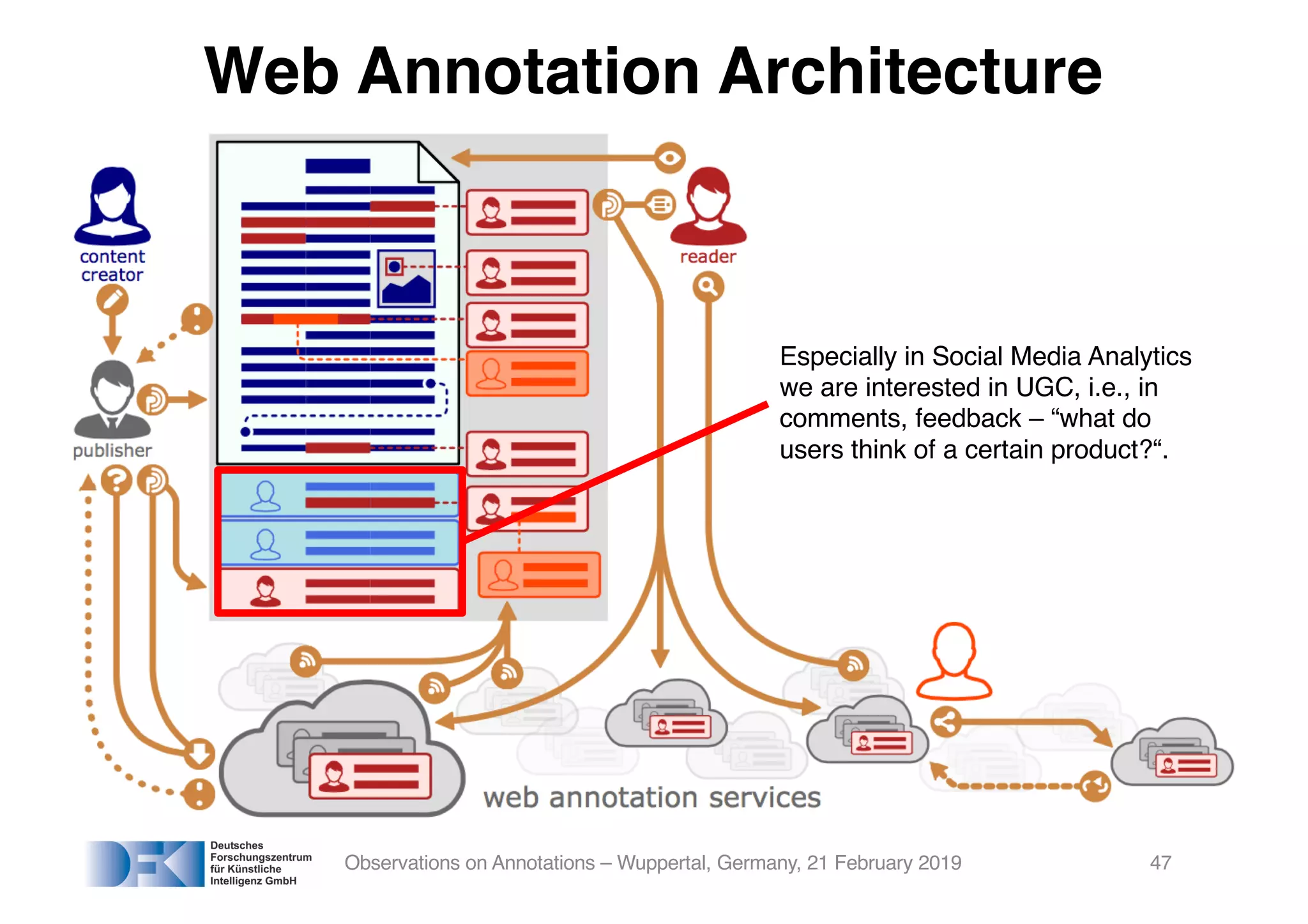
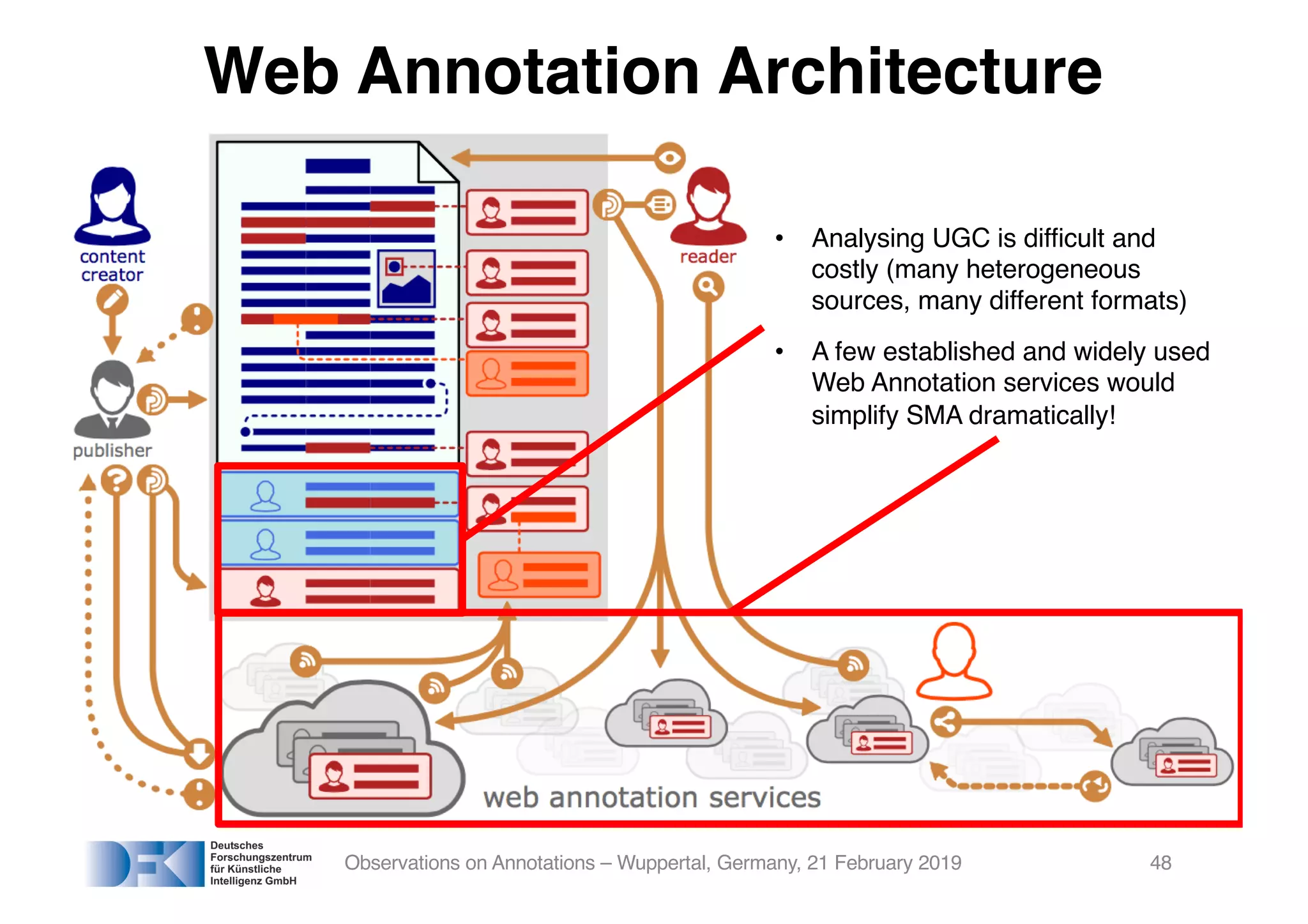
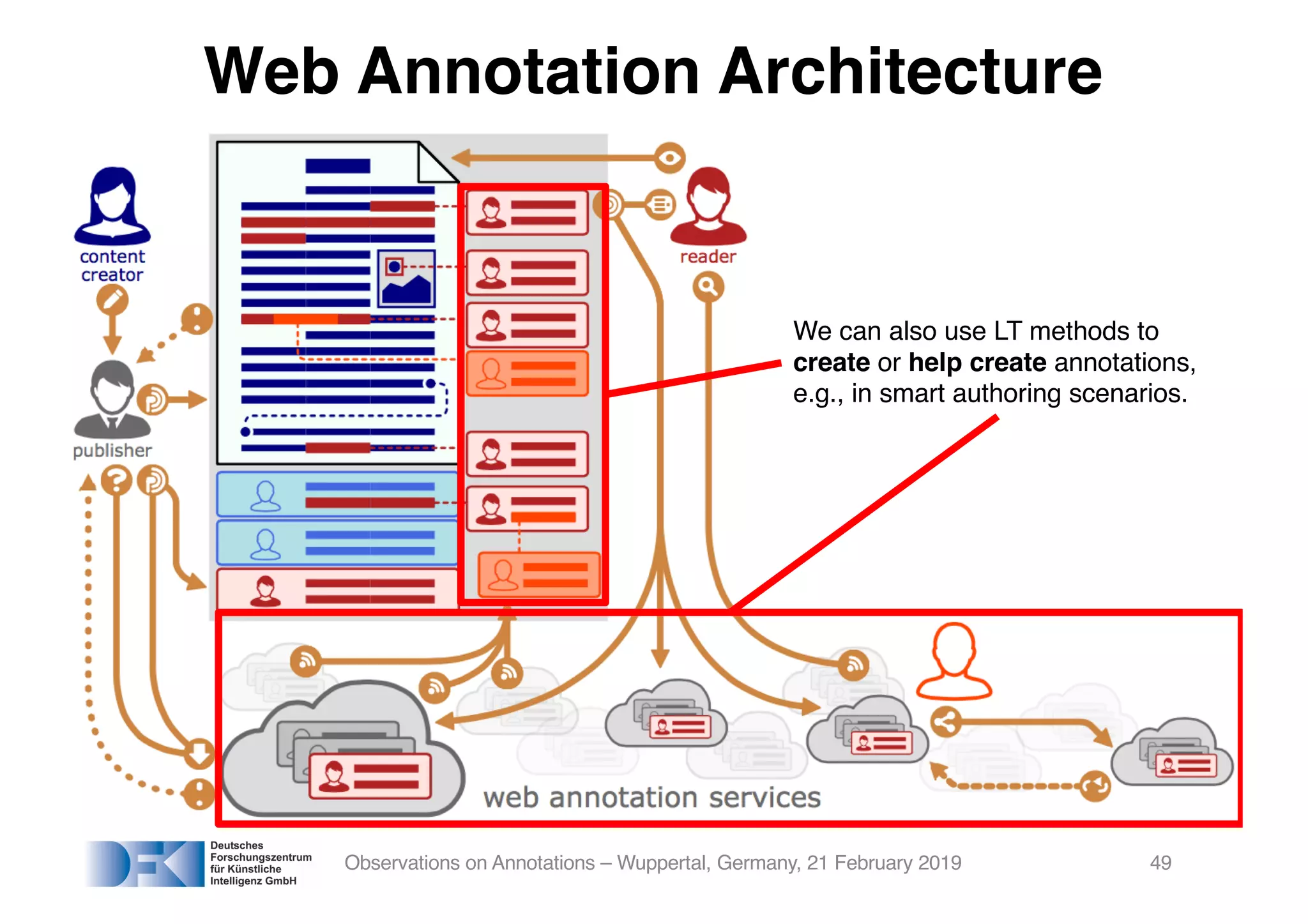

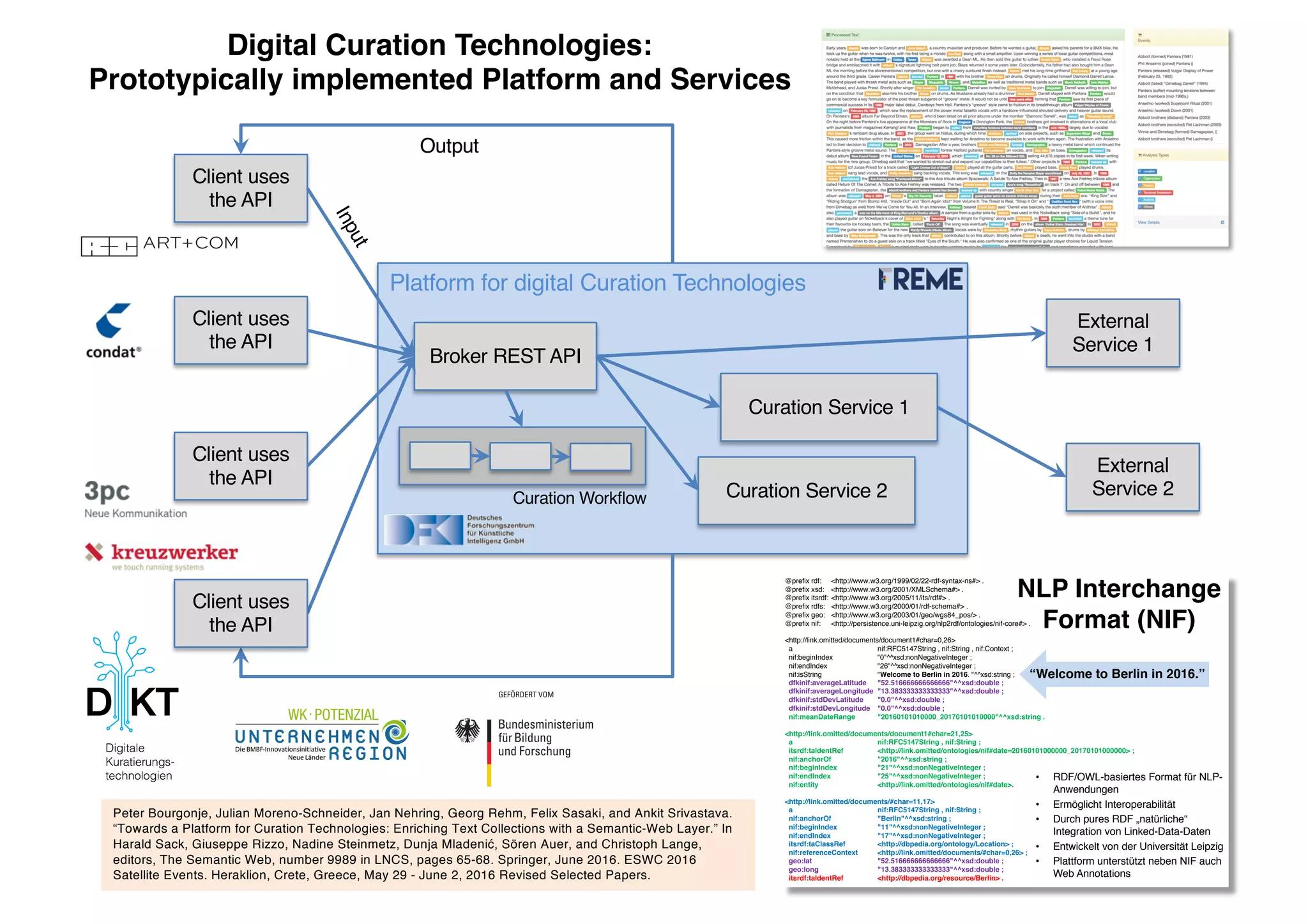

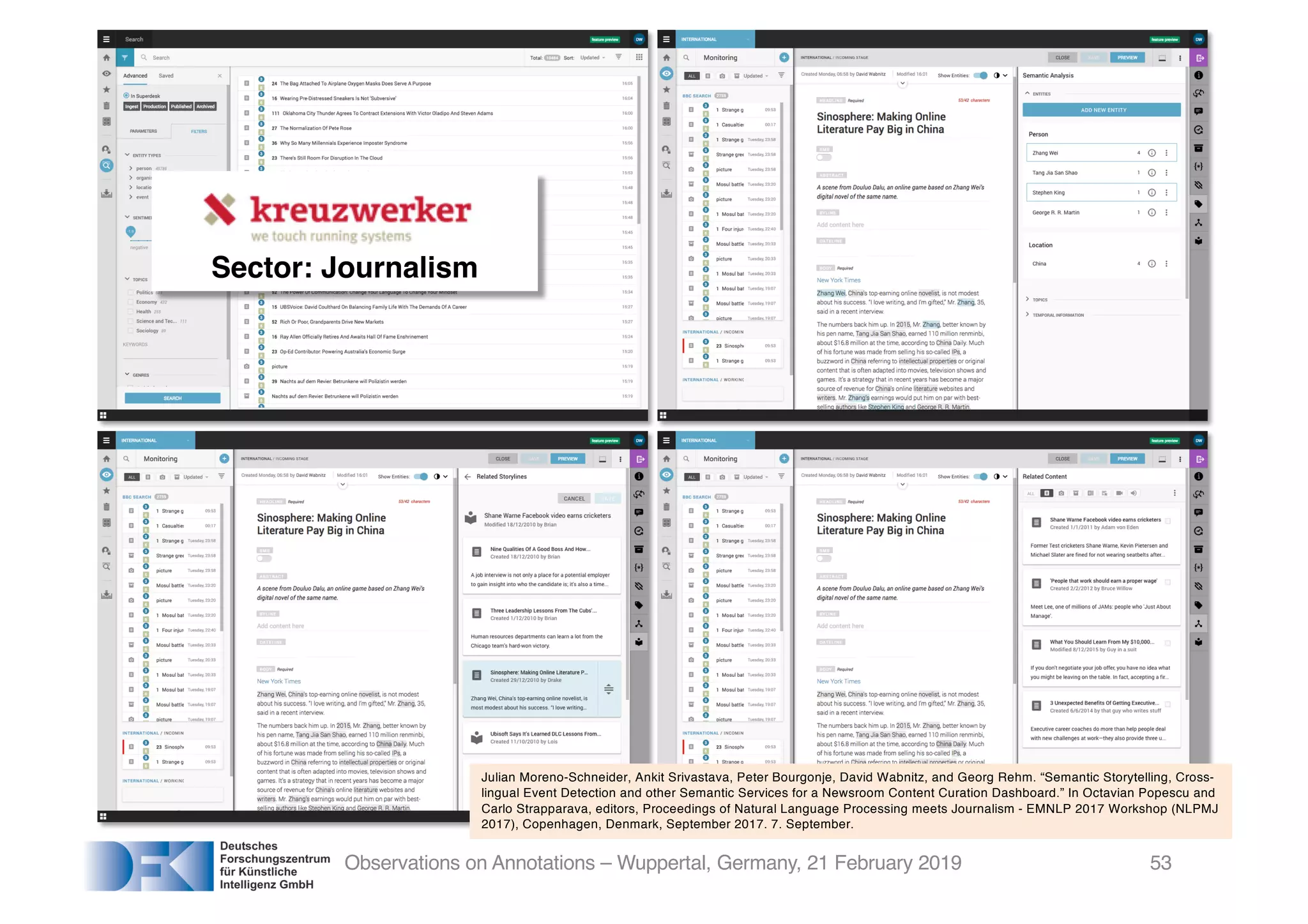



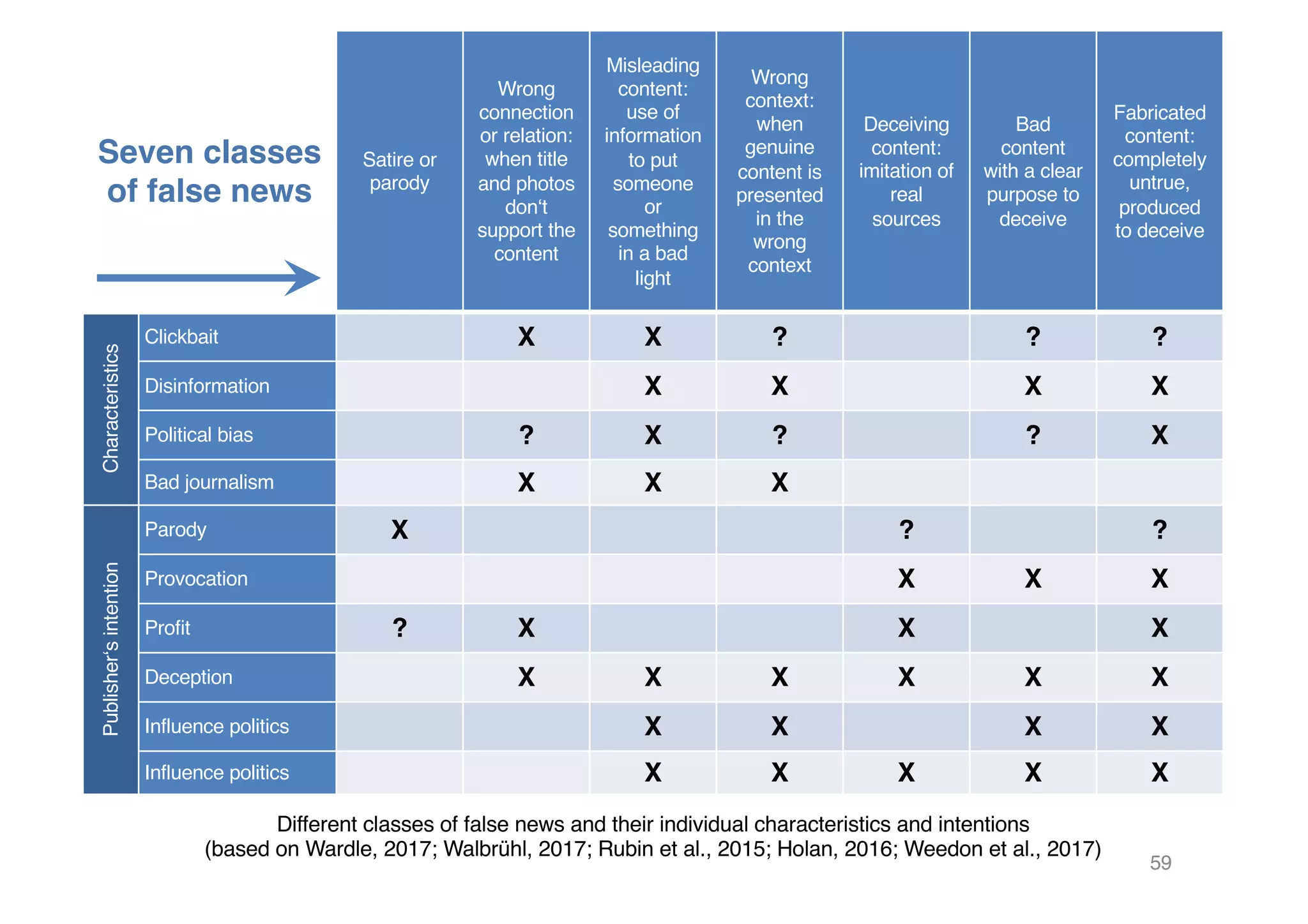
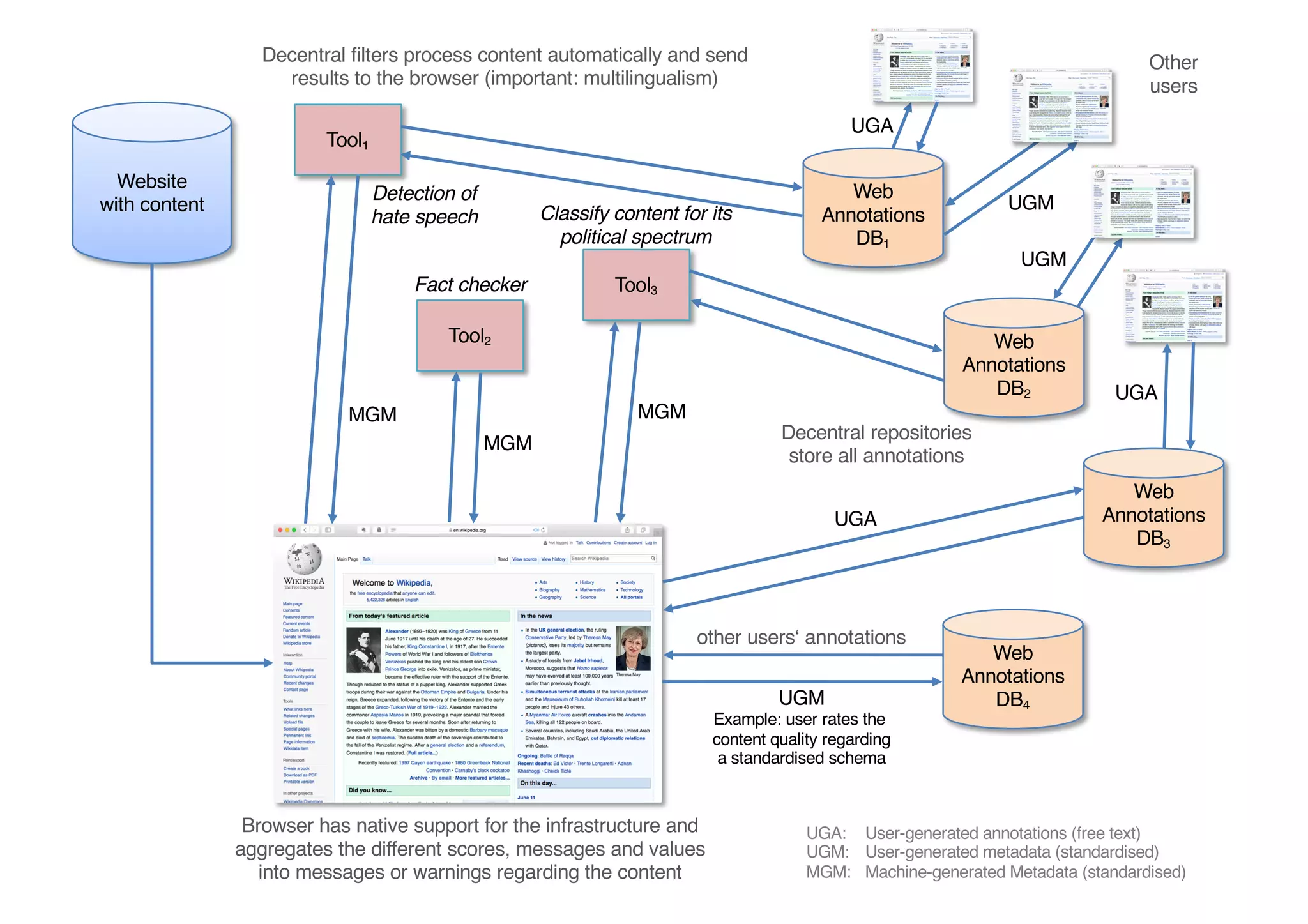
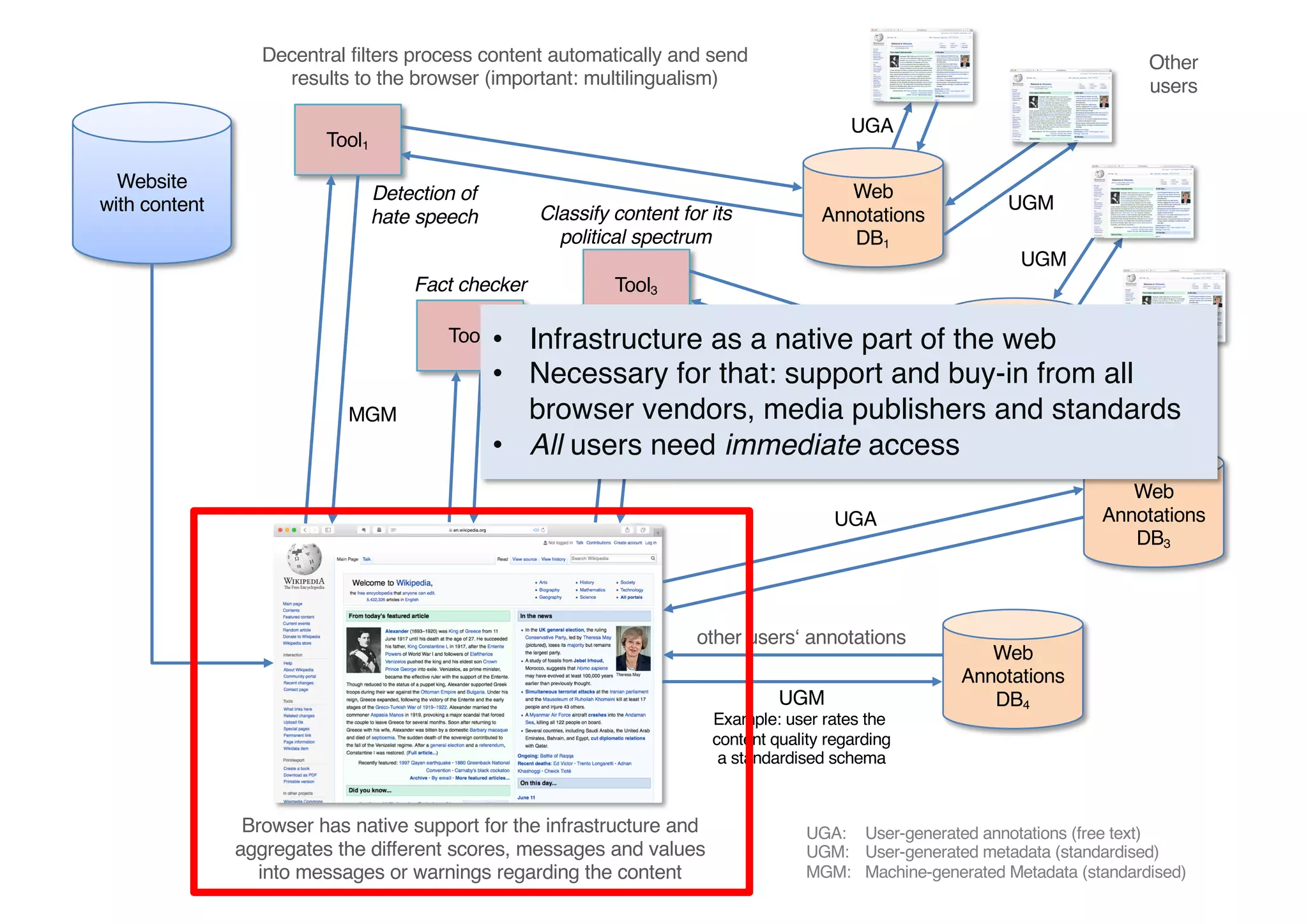
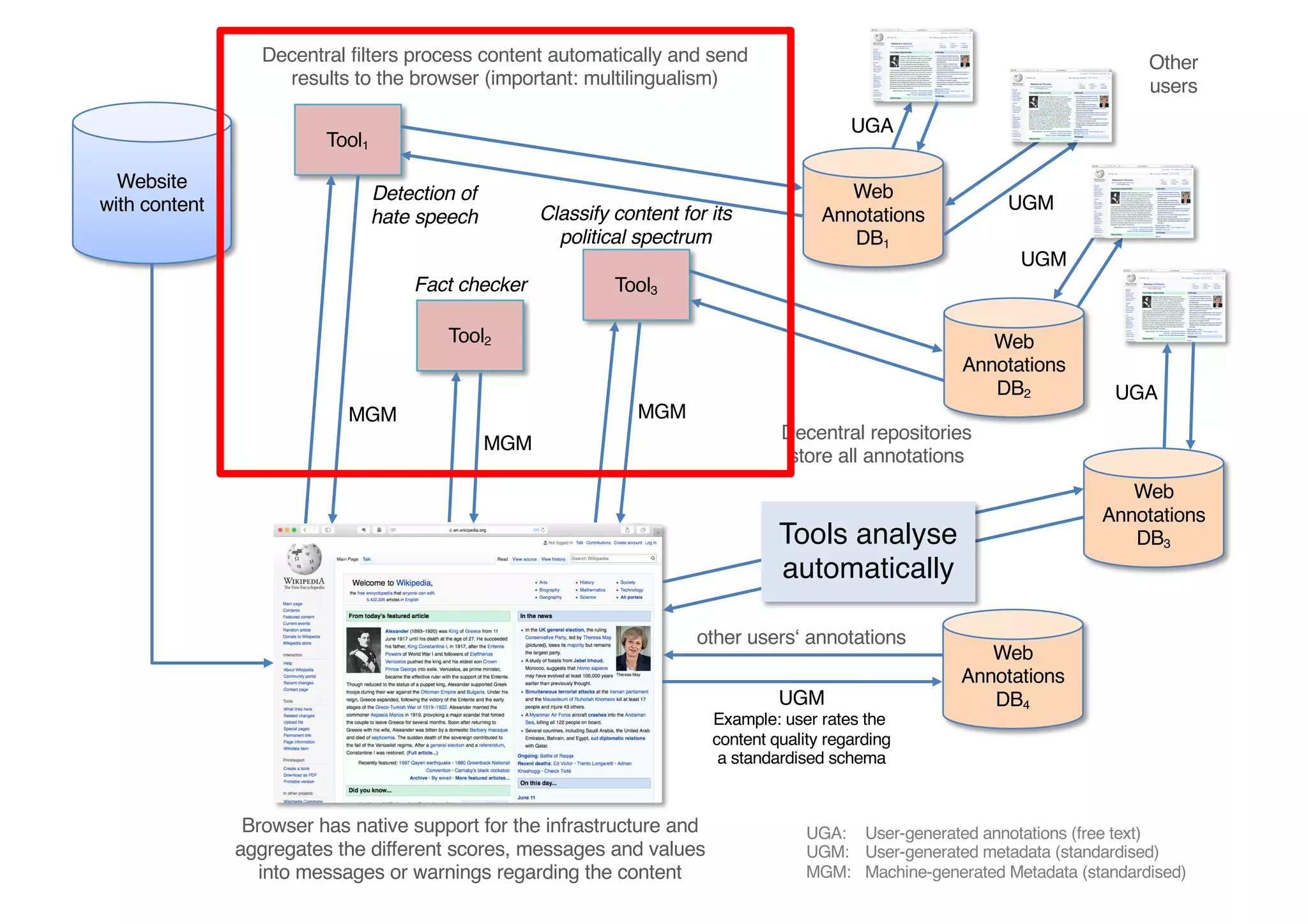
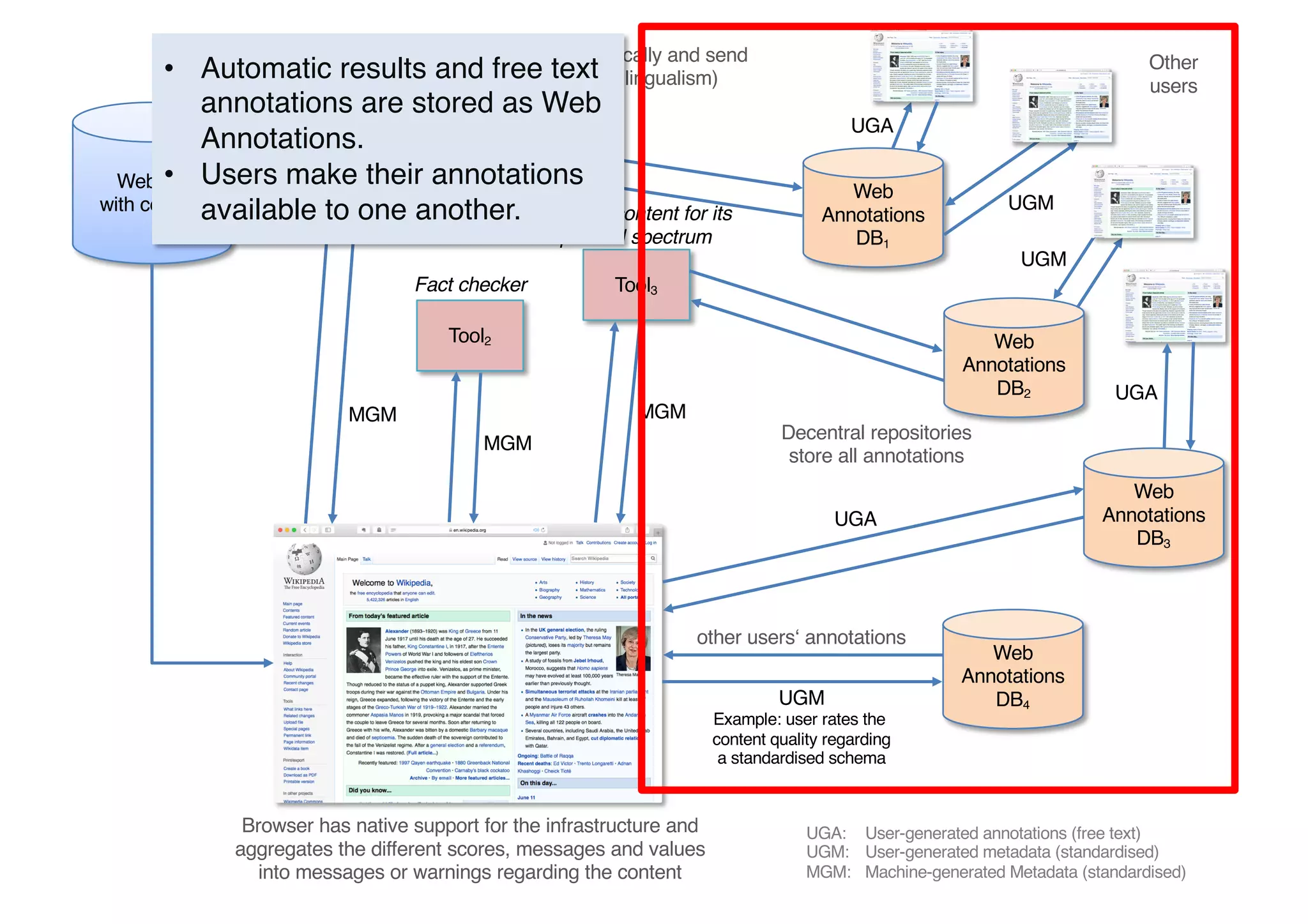
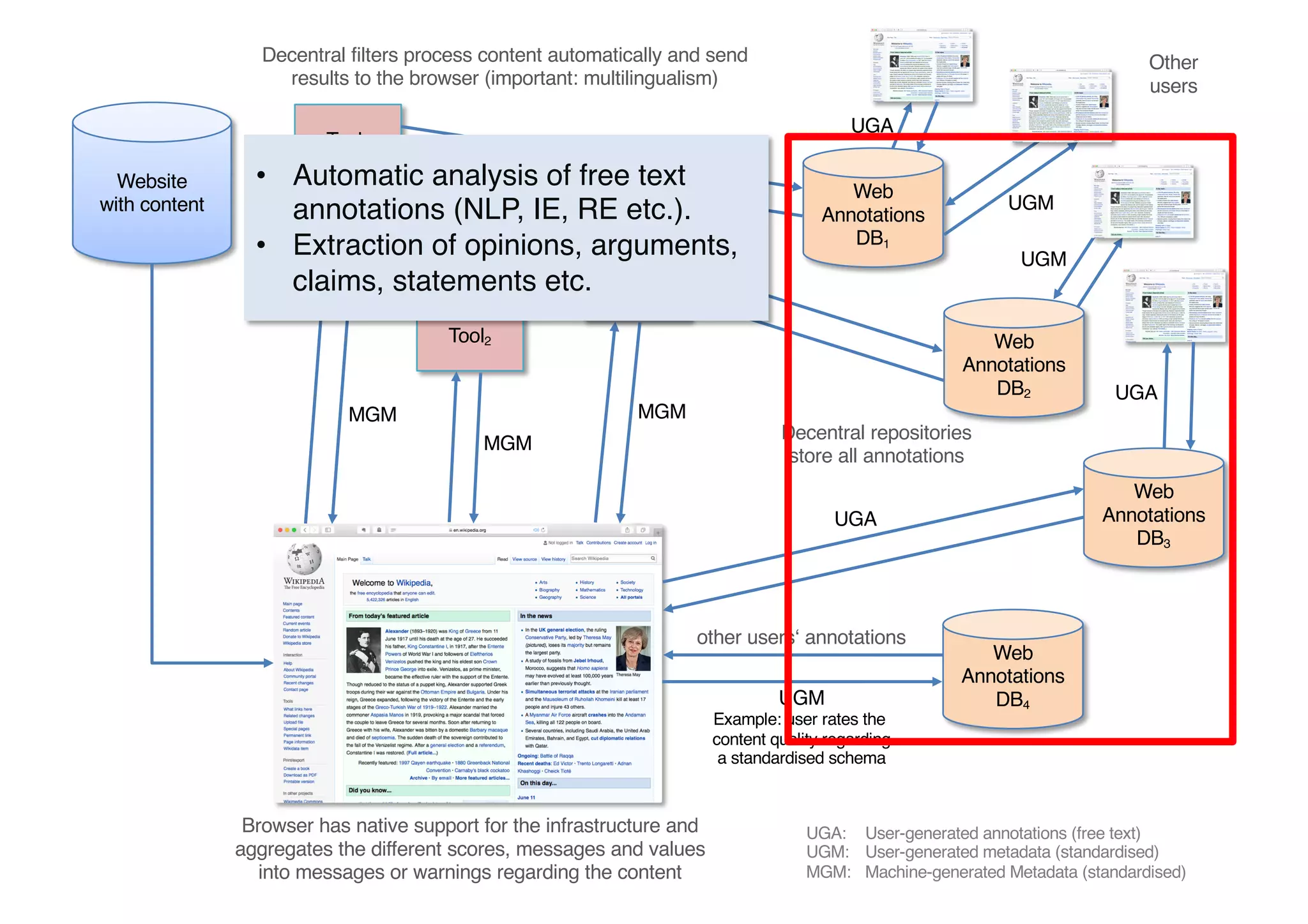
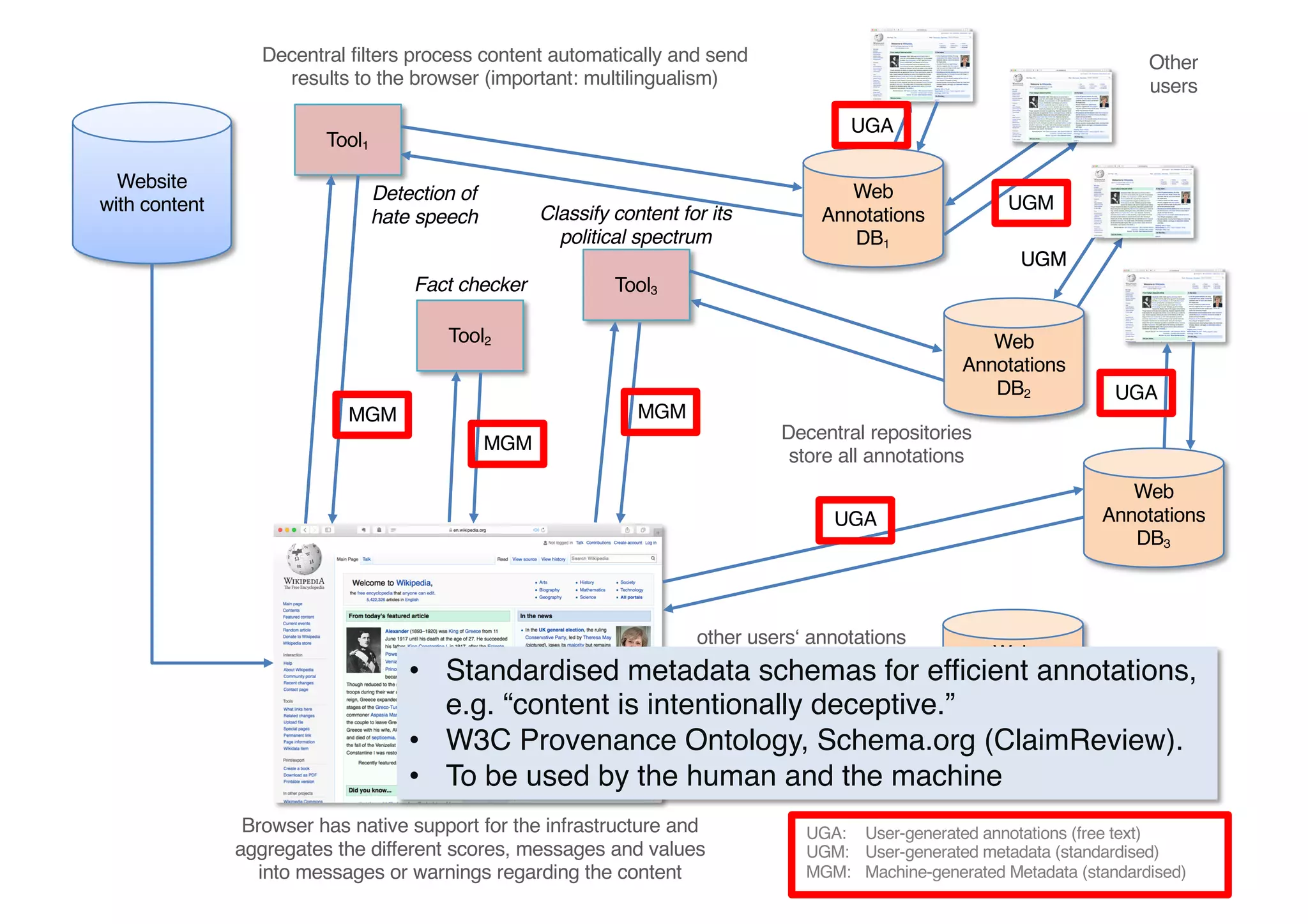
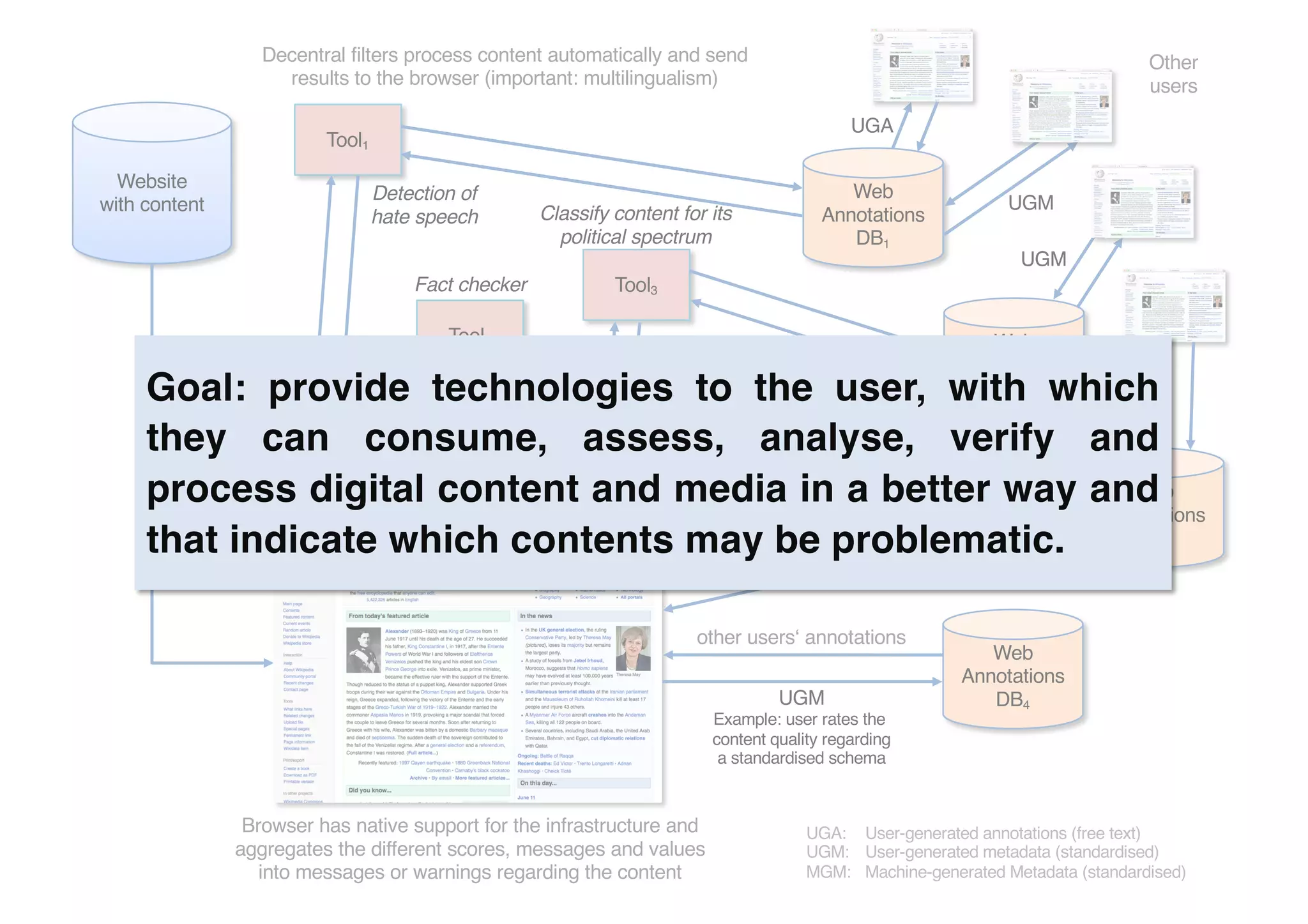























The document presents insights from Georg Rehm's talk at Bergische Universität Wuppertal on annotations in computational linguistics, their significance in AI, and their applications in the context of the web. It discusses various annotation definitions, their historical development, and specific technologies such as the W3C's web annotation standards. Rehm emphasizes the importance of annotations in enhancing research data credibility and the evolving role of AI in leveraging annotated datasets.