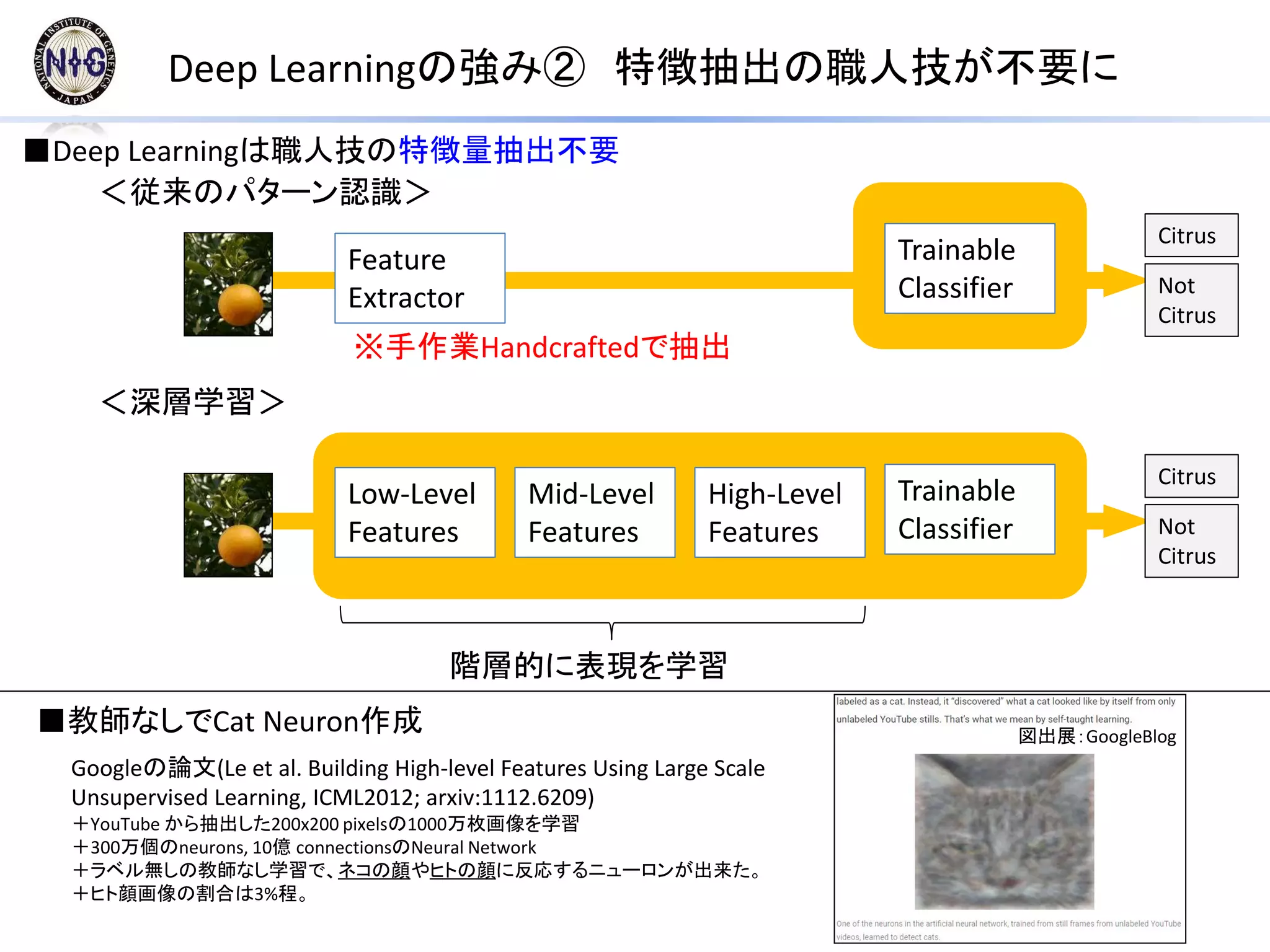
Deep Learningの強み② 特徴抽出の職人技が不要に
<従来のパターン認識>
■DeepLearningは職人技の特徴量抽出不要
<深層学習>
Feature
Extractor
Trainable
Classifier
Citrus
Not
Citrus
Low-Level
Features
Trainable
Classifier
Citrus
Not
Citrus
Mid-Level
Features
High-Level
Features
階層的に表現を学習
※手作業Handcraftedで抽出
Googleの論文(Le et al. Building High-level Features Using Large Scale
Unsupervised Learning, ICML2012; arxiv:1112.6209)
+YouTube から抽出した200x200 pixelsの1000万枚画像を学習
+300万個のneurons, 10億 connectionsのNeural Network
+ラベル無しの教師なし学習で、ネコの顔やヒトの顔に反応するニューロンが出来た。
+ヒト顔画像の割合は3%程。
図出展:GoogleBlog
■教師なしでCat Neuron作成
Image/DNA-based DNN ModelArchitecture
adopted in Latest(~2017) Conventional Studies
IMAGE
DNA
REFERENCE DATE INput, TarGeT DNN Architecture, etc.
PMID:
29086034
2017.10 IN=Endoscopy Images内視鏡画像,
TGT=Classification
CNN(Pre-trained AlexNet) + SVM
(96Convolutional kernels)
PMID:
29083930
2017.10 IN=Histopathological Images,
TGT=Osteosarcoma骨肉腫 Classification
CNN( VGG, AlexNet)
PMID:
29082086
2017.9 IN=OCT images, TGT=Cochlear Endolymphatic
Hydrops蝸牛内リンパ水腫
CNN (VGG16-based)
Scratch
REFERENCE DATE ToolName INput, TarGeT DNN Architecture, etc.
PMID:
29069282
2017.10 DeOpen IN=DNA sequence
TGT=Chromatin accessibility prediction
Composition Model
(CNN_org 4 layers + BP)
PMID:
28158264
2017.2 CNNProm IN=DNA sequence(Hs,Mm,At 251nt,Ec,Bs 81nt),
TGT=Promotor Classification
CNN-org 2-3 layers
arXiv:
1608.03644
2017.1 DeepMotif IN=DNA sequence
TGT=TFBS classification
CNN,RNN(LSTM),CNN+R
NN, org_1-4 layers
PMID:
27587684
2016.9 DeepChrom IN=Peak-based shift window matrix
TGT=Gene expression prediction
CNN-org 2-3 layers
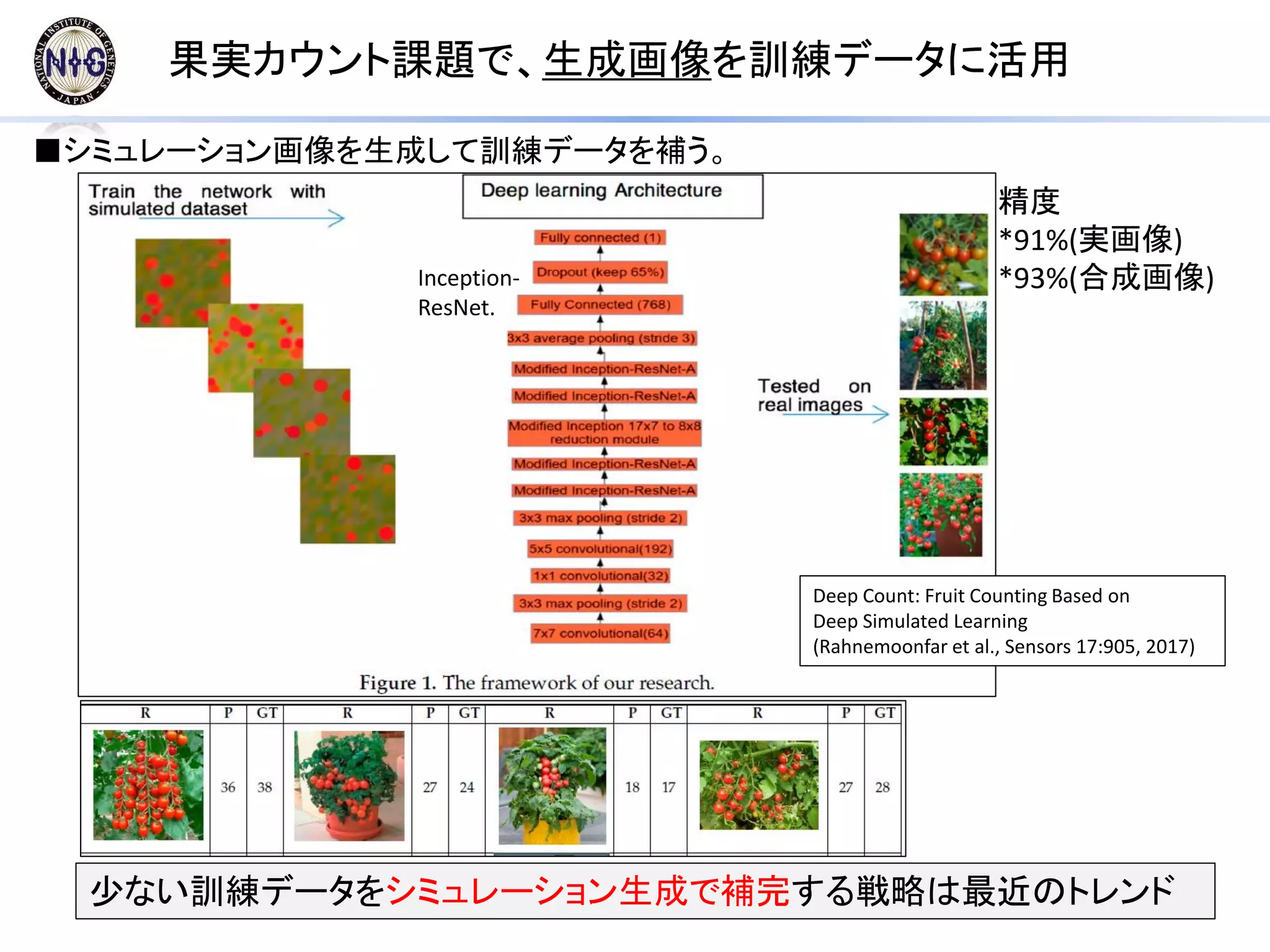
ResNet, Inception, Xception seem to be not adopted yet in life science studies.
CNN models for DNA sequences had few layers.
Survey
39.
CNNProm
(TATA promotor prediction)
PMID:28158264
This encoding matrix is used as the
input to a convolutional, recurrent,
or convolutional-recurrent module
that each outputs a vector of fixed
dimension. The output vector of
each model is linearly fed to a
softmax function as the last layer
which learns the mapping from
the hidden space to the output
class label space C ∈ [+1, −1]. The
final output is a probability
indicating whether an input is a
positive or a negative binding site
(binary classification task)
Each model has the same input (one-
hot encoded matrix of the raw
nucleotide inputs), and the same
output (softmax classifier to make a
binary prediction).
DeepMotif
(TFBS classification)
arXiv:1608.03644, PSB2017
CNN Model Architectures (1)
Survey
40.
DeOpen
(Chromatin accessibility prediction)
PMID:29069282
bipartite model combined with CNN and a typical
three-layer BP neural network.
It consists of 9 convolutional layers, 3 max pooling layers, 3 fully
connected layers. Each convolution layer contains 128 convolution
kernels The parameter k is set to 6 in our model, thus creating a
1024 dimensional feature vector for each DNA sequence. We also
apply dropout technology to the output of MergeLayer with the rate
0.5 in case of overfitting.
DeepChrom
(Gene expression prediction from histone
modifications)
PMID: 27587684
CNN Model Architectures (2)
Survey
41.
K-mer-based DNN ModelArchitecture adopted in
Latest(~2017) Conventional Studies
K-mer
REFERENCE DATE ToolName INput, TarGeT DNN Architecture, etc.
PMID: 28881969 2017.7 ismb2017_lst
m
IN=k-mer frequency
TGT=Chromatin accessibility prediction
RNN(LSTM)
PMID: 27506469 2016.8 IPMiner IN=k-mer frequency
TGT=ncRNA-protein interactions prediction
Multiple CNNs + Logistic
Regression
DNN models for K-mer
frequency should be
compared CNN to
RNN(LSTM).
PMID: 28881969 AUC:0.881(K562) PMID: 27506469 ACC:0.891
(Preprint)
K=6
1-layer
Survey









![葉病理診断で
画像色空間は処理無「Color」が精度高
色空間別分類精度
Color > Color Segmented >> Grayscale
[Mohanty et al, 2016]](https://image.slidesharecdn.com/180126dstepdnn-180130062605/75/18-01-26-DSTEP-14-2048.jpg)
![葉病理課題で、
CNNモデルはAlexNetよりGoogLeNetが精度高
CNNモデル別分類精度: GoogLeNet※ > AlexNet
[Mohanty et al, 2016]
AlexNet CNN
+ CNN元祖のHinton博士の有名モデル
+ ILSVRC2012の優勝モデル
+ 8 layers network
GoogLeNet CNN
+ ILSVRC2014の優勝モデル
+ 22 layers network
https://leonardoaraujosantos.gitbooks.io/artificialinteligence/content/image_folder_5/GoogleNet.png
※当時のモデルの為、注意すること](https://image.slidesharecdn.com/180126dstepdnn-180130062605/75/18-01-26-DSTEP-15-2048.jpg)
![葉病理診断で、
訓練済モデルを活用する転移学習が精度高
学習方法別分類精度:
訓練済モデルの転移学習 > Scratchから学習
[Mohanty et al, 2016]
http://www.image-net.org/](https://image.slidesharecdn.com/180126dstepdnn-180130062605/75/18-01-26-DSTEP-16-2048.jpg)
![植物種同定課題で、
ウェブ取得したNoisy Labels画像を追加する方式が精度高
訓練データ追加の精度比較:
精査済+非精査利用 > 精査済のみ利用
[Atito et al, 2017]
→ 精査していない注釈データでも、訓練データに使用可](https://image.slidesharecdn.com/180126dstepdnn-180130062605/75/18-01-26-DSTEP-17-2048.jpg)
![植物種同定課題で、
部位別認識精度は「花>全体>果実>葉」
[Goeau et al, 2017]
PlantCLEF2017
複数の条件をまとめて分類する場合も、検討する](https://image.slidesharecdn.com/180126dstepdnn-180130062605/75/18-01-26-DSTEP-18-2048.jpg)







![⑤ハンズオン
[ディープラーニングによる出芽酵母蛍光画
像の細胞内タンパク質局在の分類]](https://image.slidesharecdn.com/180126dstepdnn-180130062605/75/18-01-26-DSTEP-27-2048.jpg)









![CNNProm
(TATA promotor prediction)
PMID: 28158264
This encoding matrix is used as the
input to a convolutional, recurrent,
or convolutional-recurrent module
that each outputs a vector of fixed
dimension. The output vector of
each model is linearly fed to a
softmax function as the last layer
which learns the mapping from
the hidden space to the output
class label space C ∈ [+1, −1]. The
final output is a probability
indicating whether an input is a
positive or a negative binding site
(binary classification task)
Each model has the same input (one-
hot encoded matrix of the raw
nucleotide inputs), and the same
output (softmax classifier to make a
binary prediction).
DeepMotif
(TFBS classification)
arXiv:1608.03644, PSB2017
CNN Model Architectures (1)
Survey](https://image.slidesharecdn.com/180126dstepdnn-180130062605/75/18-01-26-DSTEP-39-2048.jpg)






























![[2018-03-29]JSPP18 Oxford Flower Image Datasetを用いた深層学習ハンズオン](https://cdn.slidesharecdn.com/ss_thumbnails/ekjspp180329dnn-180331182037-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019-03-14] JSPP19 深層学習による植物注釈タスクとPublic Cloud活用法](https://cdn.slidesharecdn.com/ss_thumbnails/jspp190314-190325061332-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019-09-02] AI・IoT活用情報とGoogle Colab植物画像注釈](https://cdn.slidesharecdn.com/ss_thumbnails/plantinformatics190902-190906044014-thumbnail.jpg?width=640&height=640&fit=bounds)





![[2021-03-14] 植物表現型画像解析のための手作業注釈加速化手法とActive Learning](https://cdn.slidesharecdn.com/ss_thumbnails/ek210314vfin-210804060823-thumbnail.jpg?width=640&height=640&fit=bounds)

![[オープンキャンプin南島原2020]深層学習を使ってキュウリ選別機作ってみた](https://cdn.slidesharecdn.com/ss_thumbnails/opencampminamishimabara-200523041547-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]A closer look at few shot classification](https://cdn.slidesharecdn.com/ss_thumbnails/acloserlookatfew-shotclassification-190304034759-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2020-12-15] 実験研究者のための深層学習入門 [第2回] Google Colab 環境で自動機械学習と深層画像生成(AutoML, GAN編)](https://cdn.slidesharecdn.com/ss_thumbnails/ekcsrsseminar201215mod-210804060106-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2020-09-01] IIBMP2020 Generating annotation texts of HLA sequences with anti...](https://cdn.slidesharecdn.com/ss_thumbnails/ekiibmp2020fin-200901093859-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019-11-22] JSAI合同研究会 糖尿病電子カルテを事例としたMeSH Term注釈に基づくアクセス制限研究のオープンデータ類似検索](https://cdn.slidesharecdn.com/ss_thumbnails/ekjsai-aimed191122-191125030601-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2017-05-29] DNASmartTagger](https://cdn.slidesharecdn.com/ss_thumbnails/ek170529-170728084217-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2016-12-01] DDBJデータ解析チャレンジ報告:機械学習コンペティションのタスク設計とルール設定](https://cdn.slidesharecdn.com/ss_thumbnails/bmbposter161201-161202134900-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2016-07-06] DDBJデータ解析チャレンジ概要](https://cdn.slidesharecdn.com/ss_thumbnails/ek160706fin-160707064815-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2016-06-06] CrowdR&D:クラウド協働評価のための参加型R&Dプロジェクト情報統合基盤](https://cdn.slidesharecdn.com/ss_thumbnails/ekjsai160606fin-160707063045-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2013-12-05] NGS由来ゲノムワイド多型マーカ構築とそのRDF注釈情報統合化](https://cdn.slidesharecdn.com/ss_thumbnails/mbsj131205v2-151105081233-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2015-06-10] オンライン・クラウドサイエンス(市民科学)の潮流](https://cdn.slidesharecdn.com/ss_thumbnails/150610-151105065247-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2015-11-11][DDBJing33] DDBJとNIG Supercomputerの紹介、大量配列情報解析 (第33回 DDBJing 講習会 ...](https://cdn.slidesharecdn.com/ss_thumbnails/ddbjing33ek-151105061151-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)