Downloaded 19 times
























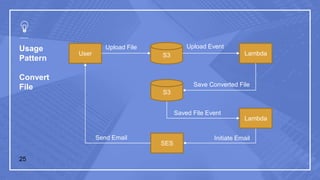
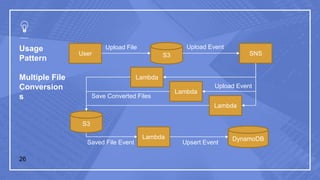
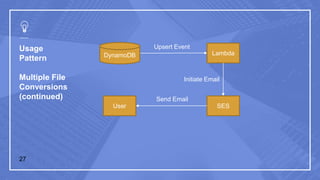
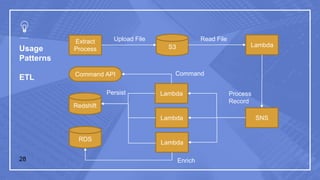
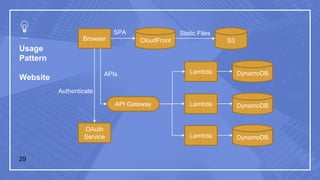




The document discusses serverless computing and its implications. It defines serverless computing as deploying small amounts of functionality without concern for server maintenance or scalability. This relies on third parties to manage servers and services. Serverless computing leads to lower costs but more complicated operations, release management, and moving between platforms. Common triggers for serverless functions include program invocation, messages, file creation, APIs, and database events. The document also provides examples of serverless usage patterns and best practices for serverless applications.
































































