コスト削減
ハード、ソフトの資産保有 →
必要な時に必要な分だけ費用計上
スピード
システムの開発ライフサイクル短縮
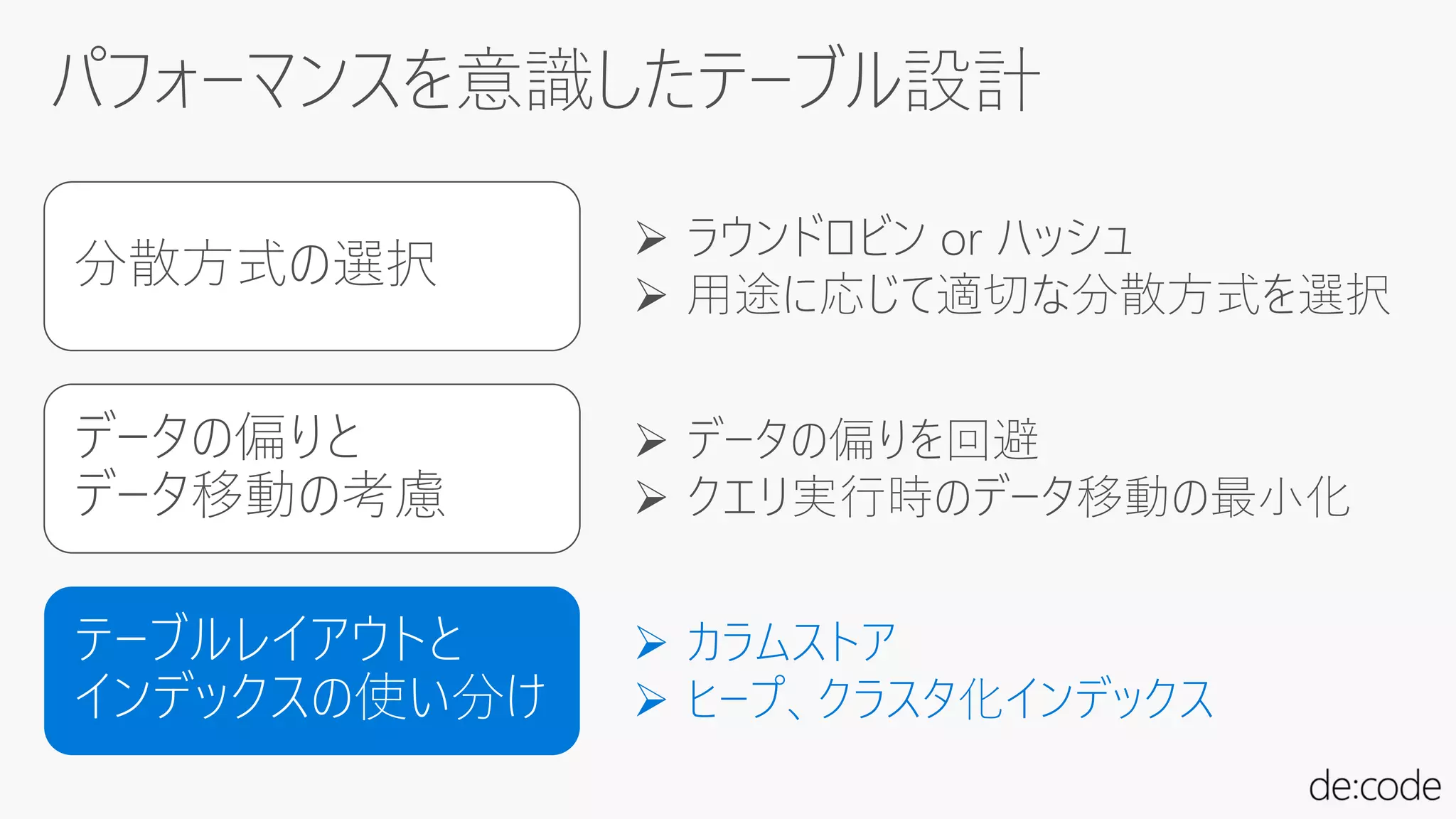
拡張性
仮想化技術をベースに柔軟にシステム
リソースを迅速に追加/縮小
デバイス: 『InfoWorkers Will Erase Boundary Between enterprise And Consumer Technologies』(Forrester Research、2012 年 8 月 30 日)
モノ: 『The Internet of Things is Poised to Change Everything, Says IDC』 (IDC 2013)、『Big data: The next frontier for innovation,
competition, and productivity』 (McKinsey & Company、2011 年)
ビッグ データ: IDC のデジタル ユニバースに関する予測を基に構成
クラウド: 『Prepare For 2020: Transform Your IT Infrastructure And Operations Practice』(Forrester Research、2012 年 10 月 24 日)
2020 年末までに接続対象となる “モノ”
(端末、装置等)の数の予測
2,120 億
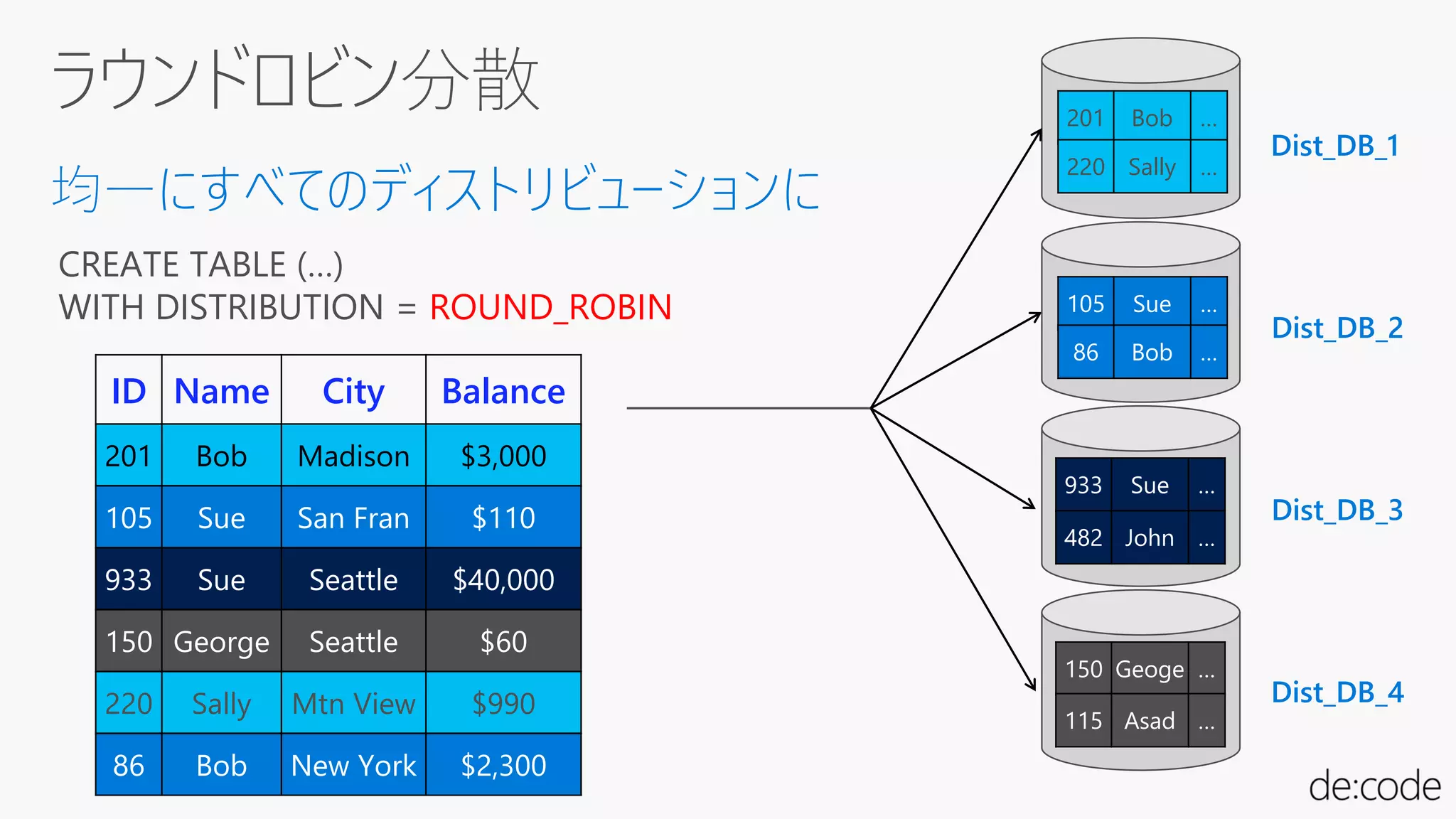
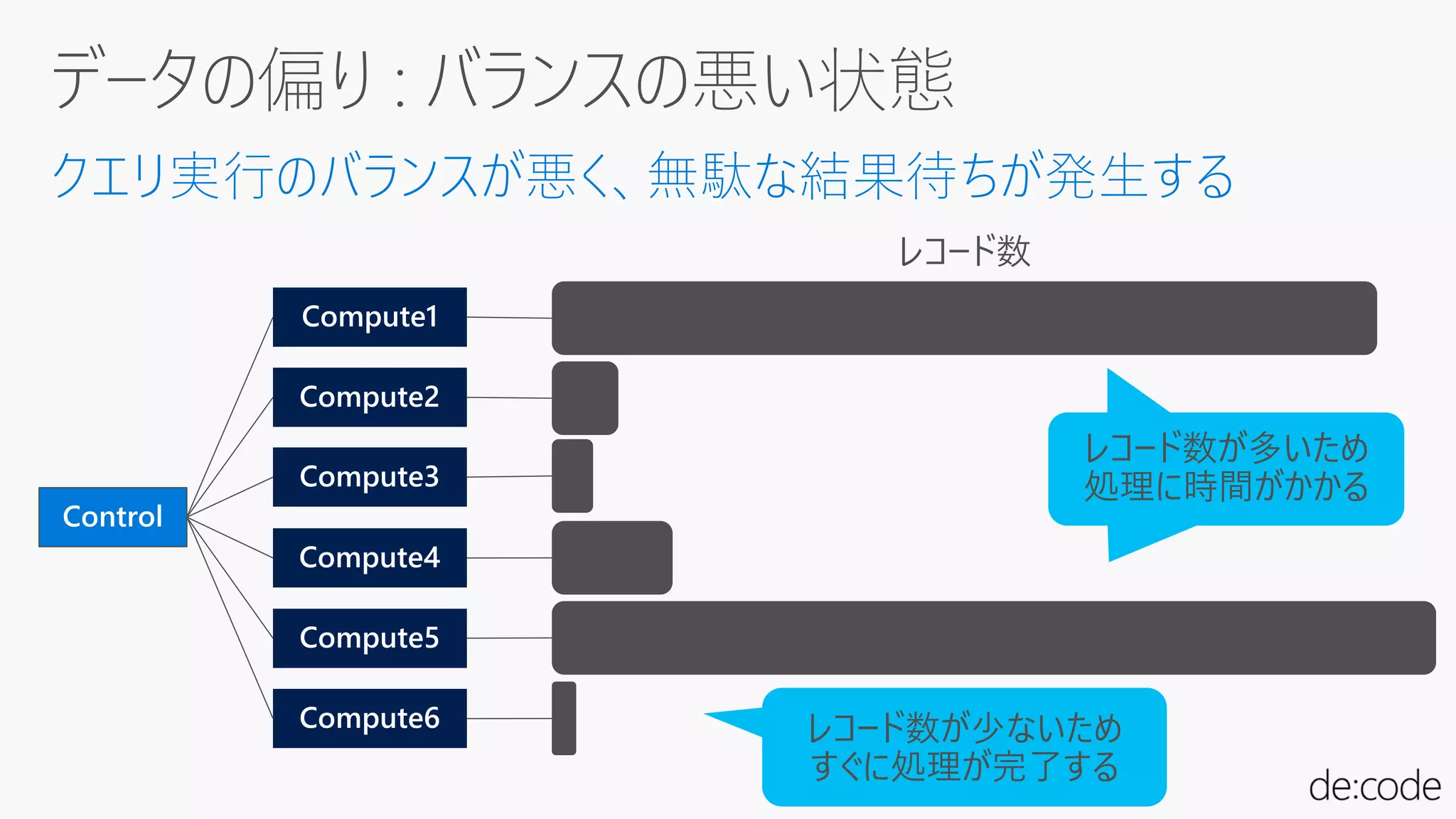
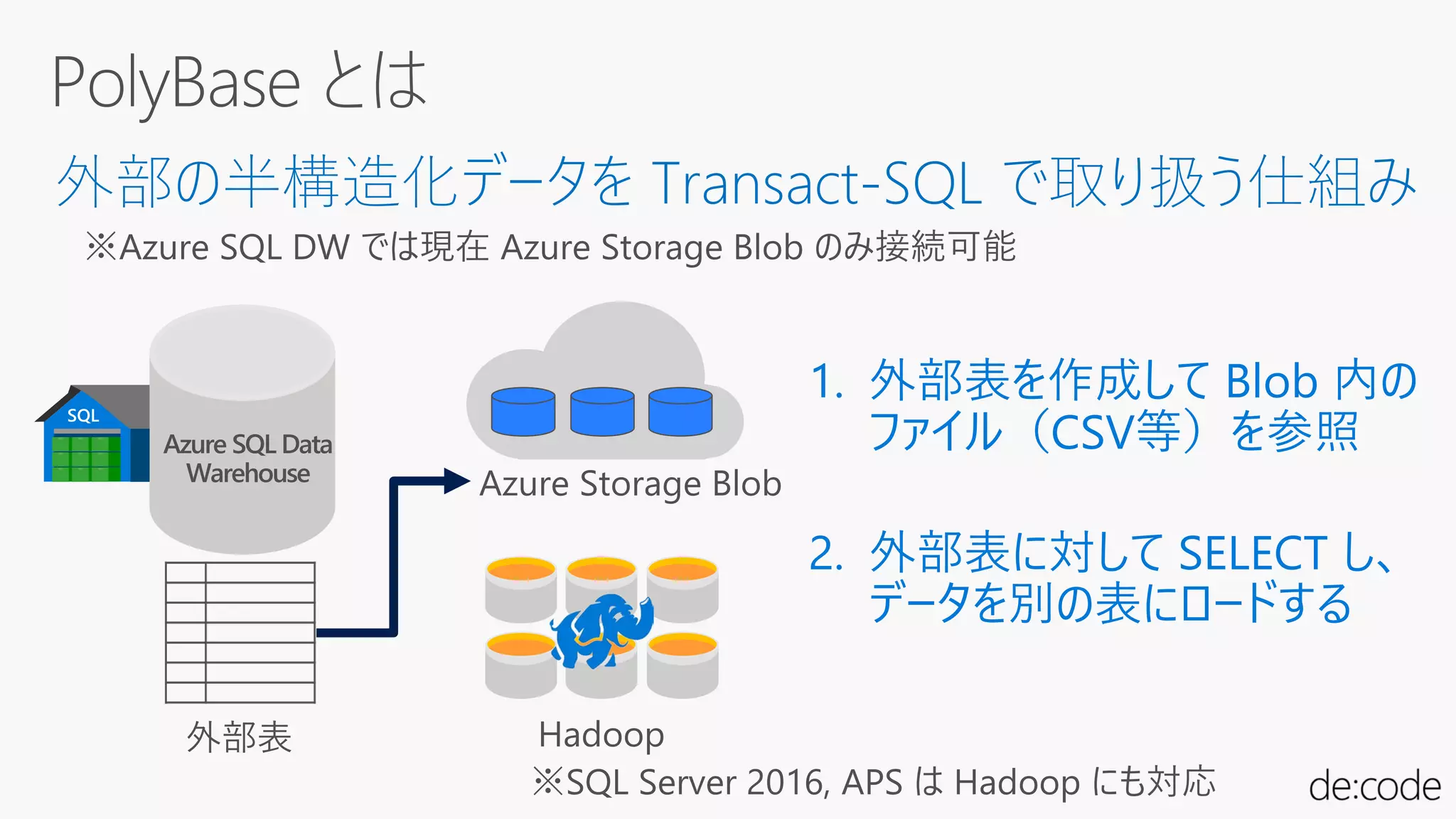
均一にすべてのディストリビューションに
CREATE TABLE (…)
WITHDISTRIBUTION = ROUND_ROBIN
Dist_DB_1
Dist_DB_2
Dist_DB_3
Dist_DB_4
ID Name City Balance
201 Bob Madison $3,000
105 Sue San Fran $110
933 Sue Seattle $40,000
150 George Seattle $60
220 Sally Mtn View $990
86 Bob New York $2,300
201 Bob …
105 Sue …
150 Geoge …
220 Sally …
86 Bob …
933 Sue …
482 John …
115 Asad …
201 Bob Madison $3,000
105 Sue San Fran $110
933 Sue Seattle $40,000
150 George Seattle $60
220 Sally Mtn View $990
86 Bob New York $2,300
21.
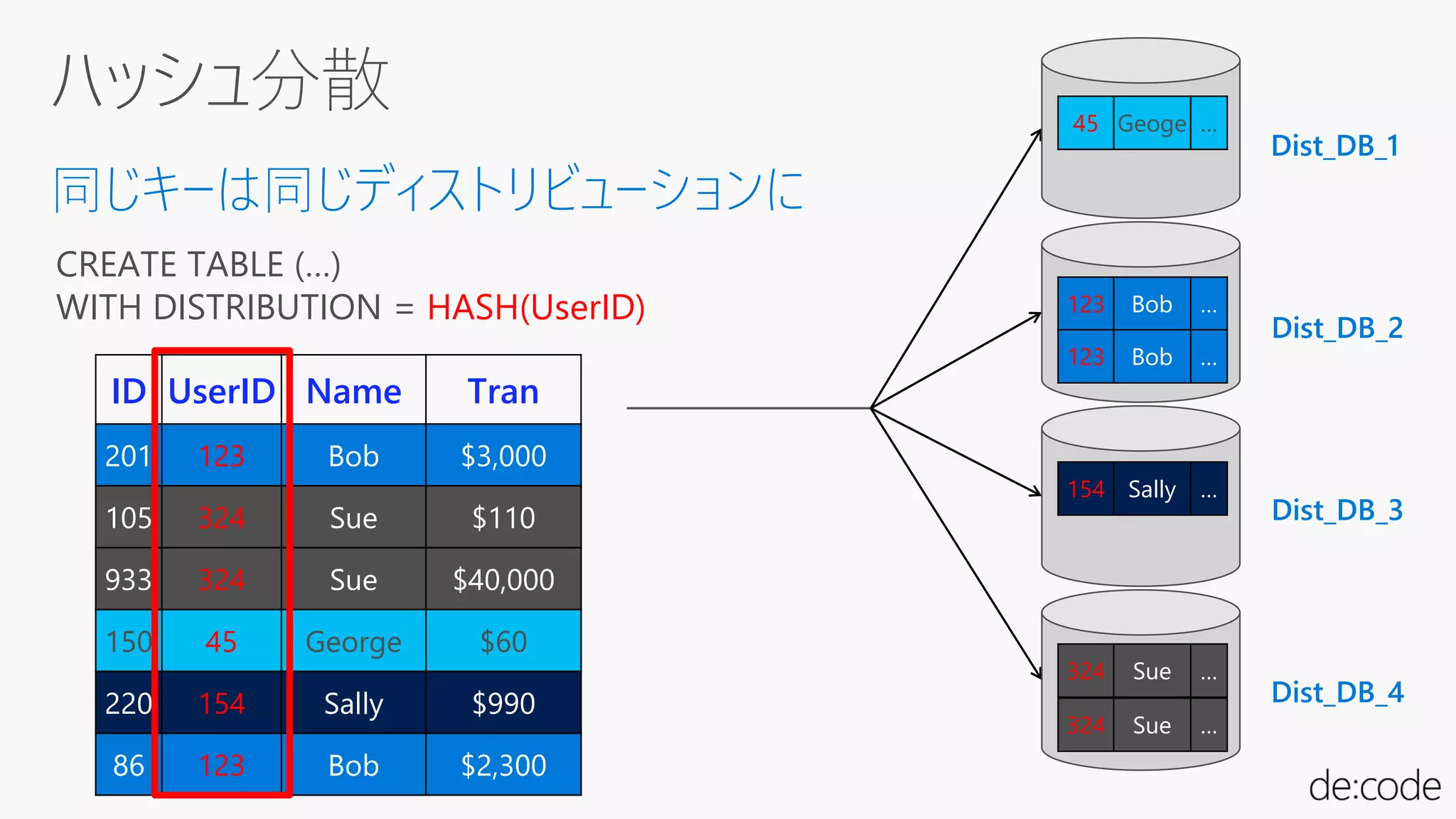
ID UserID NameTran
201 123 Bob $3,000
105 324 Sue $110
933 324 Sue $40,000
150 45 George $60
220 154 Sally $990
86 123 Bob $2,300
201 123 Bob $3,000
105 324 Sue $110
933 324 Sue $40,000
150 45 George $60
220 154 Sally $990
86 123 Bob $2,300
Dist_DB_1
Dist_DB_2
Dist_DB_3
Dist_DB_4
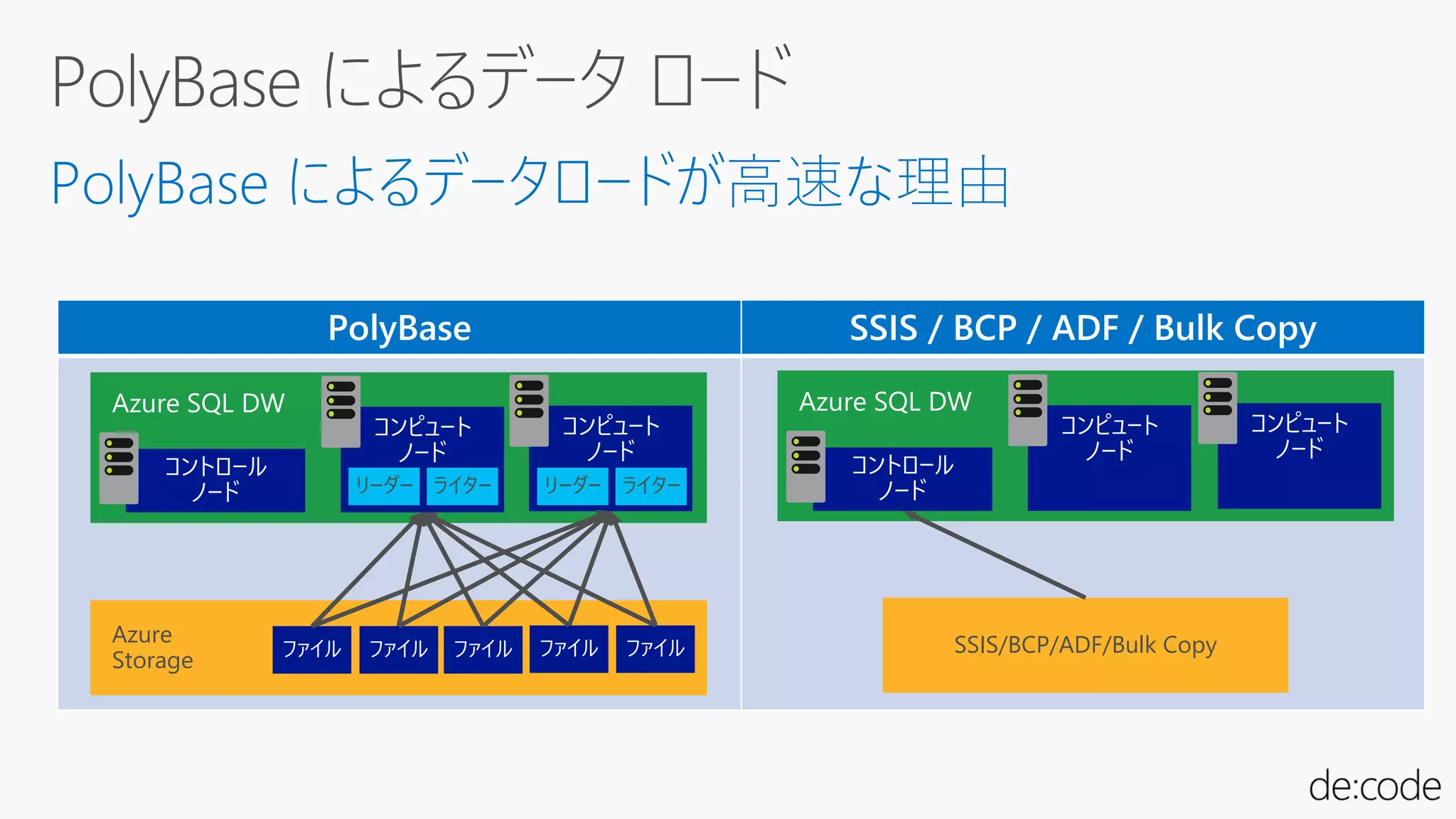
同じキーは同じディストリビューションに
123 Bob …
324 Sue …
45 Geoge …
154 Sally …
123 Bob …
324 Sue …
CREATE TABLE (…)
WITH DISTRIBUTION = HASH(UserID)
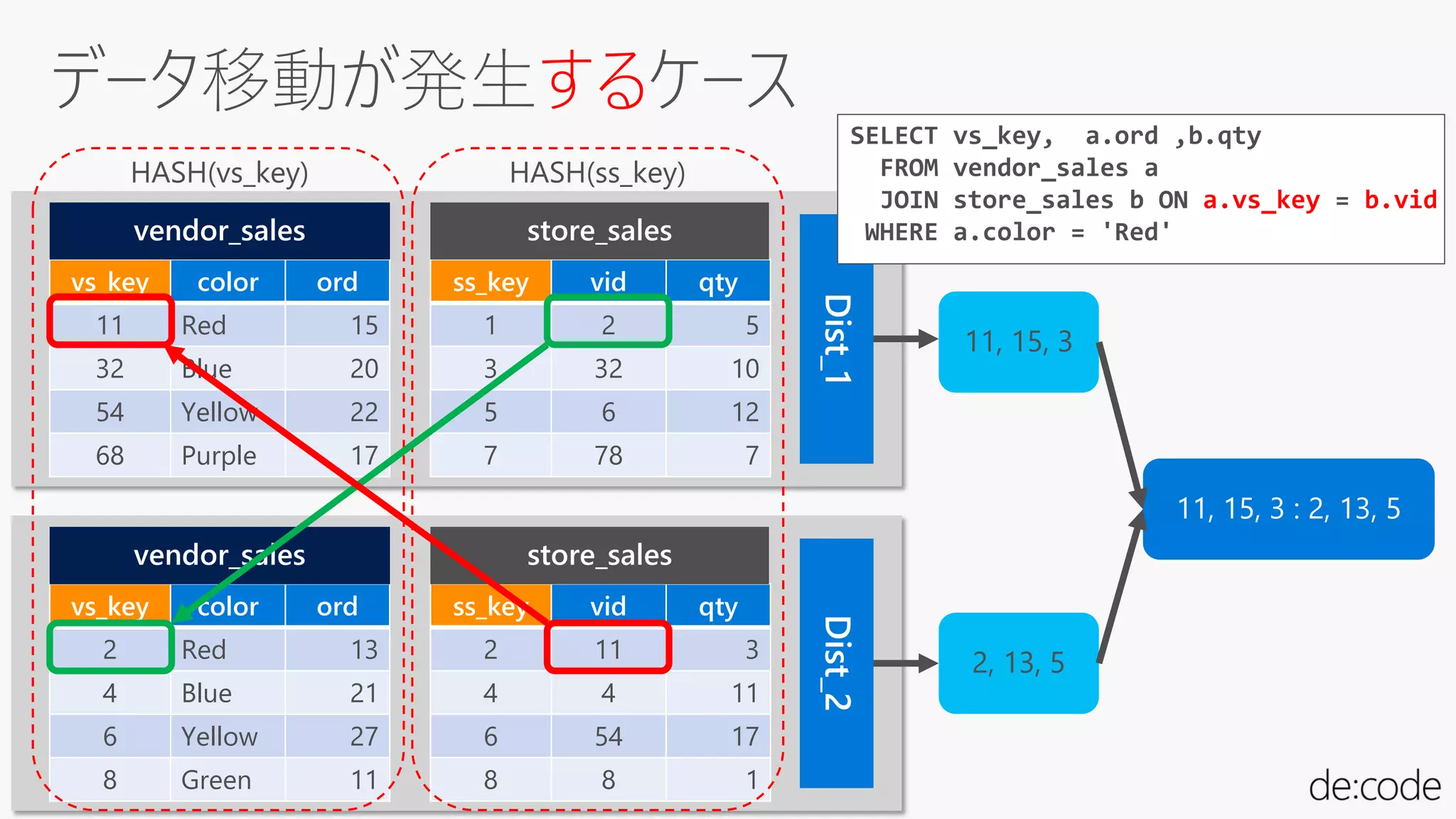
する
vs_key color ord
11Red 15
32 Blue 20
54 Yellow 22
68 Purple 17
ss_key vid qty
1 2 5
3 32 10
5 6 12
7 78 7
vs_key color ord
2 Red 13
4 Blue 21
6 Yellow 27
8 Green 11
ss_key vid qty
2 11 3
4 4 11
6 54 17
8 8 1
HASH(vs_key) HASH(ss_key)
11, 15, 3
2, 13, 5
11, 15, 3 : 2, 13, 5
SELECT vs_key, a.ord ,b.qty
FROM vendor_sales a
JOIN store_sales b ON a.vs_key = b.vid
WHERE a.color = 'Red'
29.
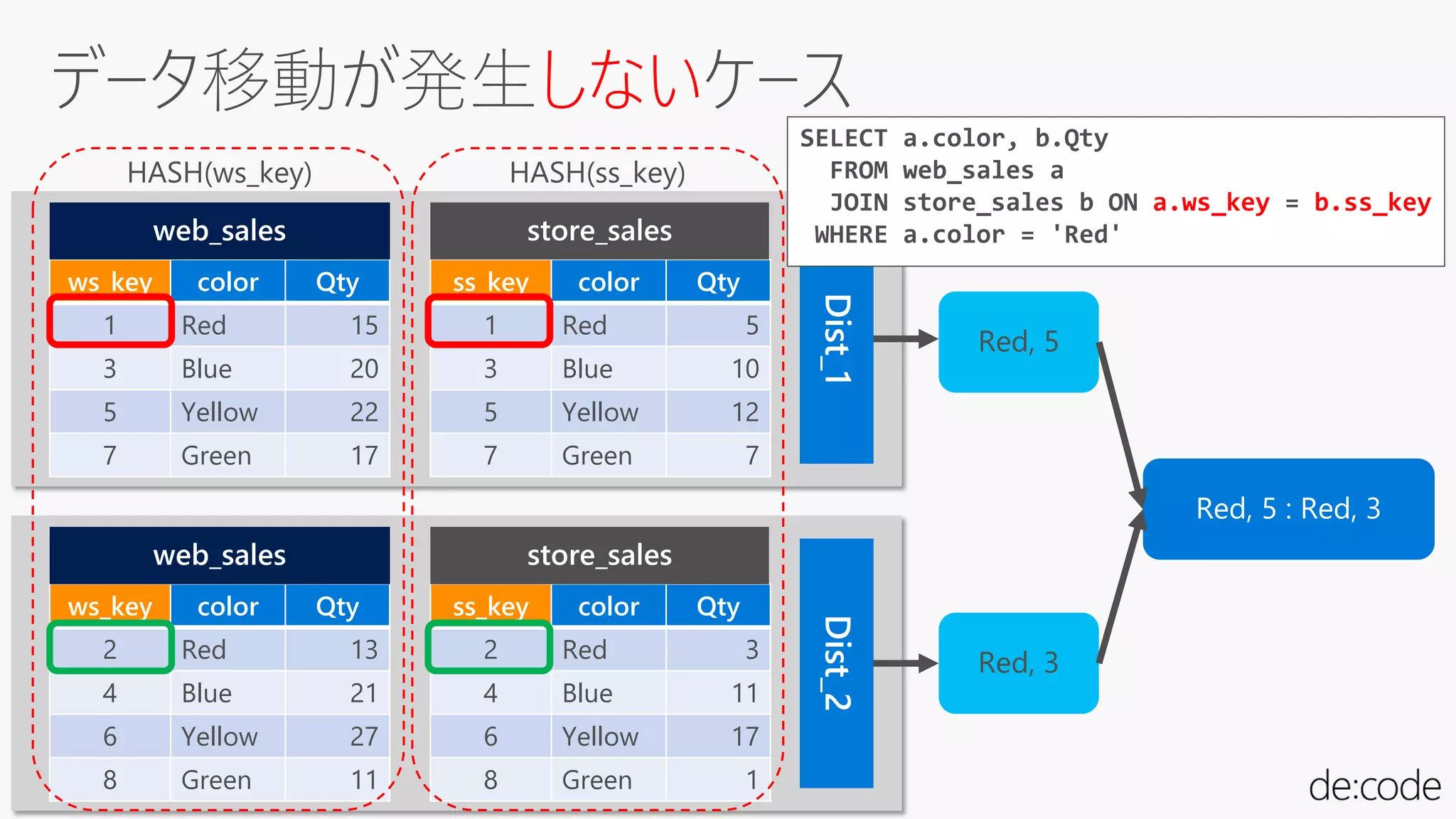
しない
ws_key color Qty
1Red 15
3 Blue 20
5 Yellow 22
7 Green 17
ss_key color Qty
1 Red 5
3 Blue 10
5 Yellow 12
7 Green 7
ws_key color Qty
2 Red 13
4 Blue 21
6 Yellow 27
8 Green 11
ss_key color Qty
2 Red 3
4 Blue 11
6 Yellow 17
8 Green 1
HASH(ws_key) HASH(ss_key)
Red, 5
Red, 3
Red, 5 : Red, 3
SELECT a.color, b.Qty
FROM web_sales a
JOIN store_sales b ON a.ws_key = b.ss_key
WHERE a.color = 'Red'











































![[db tech showcase Tokyo 2014] L32: Apache Cassandraに注目!!(IoT, Bigdata、NoSQLのバ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014l32datastaxapachecassandraiotbigdatanosql-141120022255-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)


















![【ウェブ セミナー】AI 時代のクラウド データ ウェアハウス Azure SQL Data Warehouse [実践編]](https://cdn.slidesharecdn.com/ss_thumbnails/webinarsqldw20170726-180220004900-thumbnail.jpg?width=640&height=640&fit=bounds)






![[db tech showcase Tokyo 2014] B33: 超高速データベースエンジンでのビッグデータ分析活用事例 by 株式会社日立製作所 ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014b33-141127184852-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] A32:Amazon Redshift Deep Dive by アマゾン データ サービス ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a32amazon-redshiftamazondataservicejapan-150623010123-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)



![[db tech showcase Tokyo 2015] A14:Amazon Redshiftの元となったスケールアウト型カラムナーDB徹底解説 その...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a14actian-matrix-insight-technology-150618094408-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[ウェビナー] Build 2018 アップデート ~ データ プラットフォーム/IoT編 ~](https://cdn.slidesharecdn.com/ss_thumbnails/20180614azuredataiotwebinar-180614083401-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D24] あなたのビジネスを変えるInfiniDBケーススタディ by Toshihide Hanatani](https://cdn.slidesharecdn.com/ss_thumbnails/d24-140630203914-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





























