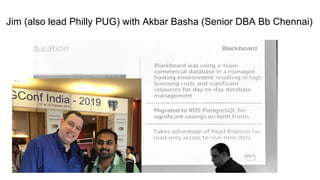
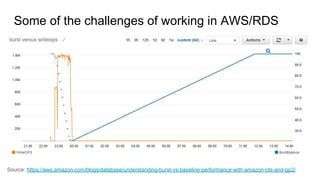
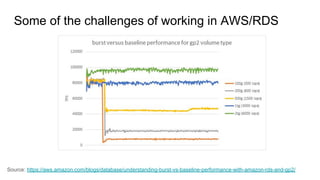
The document discusses the author's experience transitioning from Oracle to PostgreSQL as a DBA, highlighting the challenges in hiring experienced PostgreSQL DBAs and the importance of hands-on training. It covers various technical aspects related to AWS RDS, performance monitoring, and the benefits of using Vagrant for setting up virtual environments for PostgreSQL projects. Additionally, it includes practical examples and challenges faced in query optimization between PostgreSQL and Oracle databases.










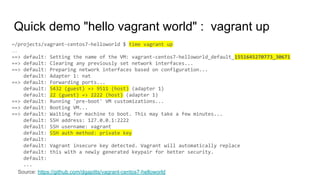
![Quick demo "hello vagrant world" : cat Vagrantfile
~/projects/vagrant-centos7-helloworld $ cat Vagrantfile
# -*- mode: ruby -*-
# vi: set ft=ruby :
Vagrant.configure("2") do |config|
config.vm.provider :virtualbox do |vb|
vb.customize ["modifyvm", :id, "--memory", "128"]
vb.customize ["modifyvm", :id, "--cpus", 1]
end
#config.vm.box = "centos/7"
config.vm.box = "https://cloud.centos.org/centos/7/vagrant/x86_64/images/CentOS-7-x86_64-Vagrant-1804_02.VirtualBox.box"
config.vm.hostname = "centos7demo"
config.vm.network :forwarded_port, guest: 5432, host: 9511
config.vm.provision :shell, :path => "provision.sh"
end
Source: https://github.com/dgapitts/vagrant-centos7-helloworld](https://image.slidesharecdn.com/postgresthehardway-190407173835/85/Postgres-the-hardway-14-320.jpg)
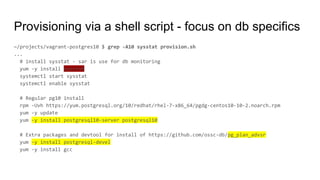
![Quick demo "hello vagrant world" : cat provision.sh
~/projects/vagrant-centos7-helloworld# cat provision.sh
#! /bin/bash
if [ ! -f /home/vagrant/already-installed-flag ]
then
echo "Add extra alias to .bash_profile for vagrant and root users"
cat /vagrant/bashprofile.append.txt >> /home/vagrant/.bash_profile
cat /vagrant/bashprofile.append.txt >> /root/.bash_profile
echo 'provision script run at : ' `date` | tee -a /home/vagrant/hello_vagrant_world.txt
else
echo "already installed flag set : /home/vagrant/already-installed-flag"
fi
~/projects/vagrant-centos7-helloworld# head -5 bashprofile.append.txt
PS1='[h:u:w] # '
alias saru30='sar -u | head -3 ; sar -u |tail -30'
alias sarq30='sar -q | head -3 ; sar -q |tail -30'
alias h='history'
alias l40='ls -ltr|tail -40'
Source: https://github.com/dgapitts/vagrant-centos7-helloworld](https://image.slidesharecdn.com/postgresthehardway-190407173835/85/Postgres-the-hardway-15-320.jpg)

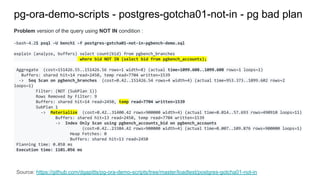
![Quick demo "hello vagrant world" : vagrant ssh
~/projects/vagrant-centos7-helloworld $ vagrant ssh
[centos7demo:vagrant:~] # cat hello_vagrant_world.txt
provision script run at : Sun Mar 3 20:34:55 UTC 2019
[centos7demo:vagrant:~] # ls -ltr /vagrant/
total 56
-rw-r--r--. 1 vagrant vagrant 537 Mar 3 13:09 Vagrantfile.bak
-rw-r--r--. 1 vagrant vagrant 35149 Mar 3 13:09 LICENSE
-rw-r--r--. 1 vagrant vagrant 279 Mar 3 13:09 bashprofile.append.txt
-rw-r--r--. 1 vagrant vagrant 563 Mar 3 19:55 README.md
-rw-r--r--. 1 vagrant vagrant 536 Mar 3 20:26 Vagrantfile
-rw-r--r--. 1 vagrant vagrant 415 Mar 3 20:33 provision.sh
[centos7demo:vagrant:~] # id
uid=1000(vagrant) gid=1000(vagrant) groups=1000(vagrant) ,,,
[centos7demo:vagrant:~] # sudo -i
[centos7demo:root:~] # id
uid=0(root) gid=0(root) groups=0(root) ...
Source: https://github.com/dgapitts/vagrant-centos7-helloworld](https://image.slidesharecdn.com/postgresthehardway-190407173835/85/Postgres-the-hardway-18-320.jpg)
![Vagrantfile - base for my pg10 centos7 VM
~/projects/vagrant-postgres10 $ cat Vagrantfile
# -*- mode: ruby -*-
# vi: set ft=ruby :
Vagrant.configure("2") do |config|
config.vm.provider :virtualbox do |vb|
vb.customize ["modifyvm", :id, "--memory", "512"]
vb.customize ["modifyvm", :id, "--cpus", 2]
end
#config.vm.box = "centos/7"
config.vm.box =
"https://cloud.centos.org/centos/7/vagrant/x86_64/images/CentOS-7-x86_64-Vagrant-1804_02.VirtualBox
.box"
config.vm.hostname = "pg10centos7"
config.vm.network :forwarded_port, guest: 5432, host: 9510
config.vm.provision :shell, :path => "provision.sh"
end
Source: https://github.com/dgapitts/vagrant-postgres10](https://image.slidesharecdn.com/postgresthehardway-190407173835/85/Postgres-the-hardway-19-320.jpg)


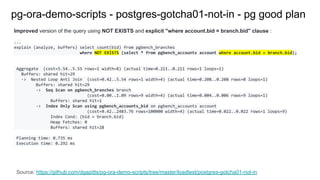




![Background postgres data_directory & pg_class.relfilenode ...
Starting with first table :
postgres=# create table tab1 (pk integer primary key,
col1 varchar(30));
CREATE TABLE
but where is my table physically stored at the OS level?
Well the base directory is data_directory:
postgres=# show data_directory;
data_directory
------------------------
/var/lib/pgsql/10/data
(1 row)
lets snapshot via tree the data_directory:
[pg10centos7:postgres:~/10/data] # tree > /tmp/temp1
and now create a 2nd table:
postgres=# create table tab2 (pk integer primary key,
col1 varchar(30));
CREATE TABLE
and now compare before & after 'snapshot of the
filesystem':
[pg10centos7:postgres:~/10/data] # tree > /tmp/temp2
[pg10centos7:postgres:~/10/data] # diff /tmp/temp1
/tmp/temp2
648a649,650
> │ ├── 16402
993c995
< 26 directories, 964 files
---
> 26 directories, 966 files
Source: https://github.com/dgapitts/pg-ora-demo-scripts/tree/master/memtest/setup](https://image.slidesharecdn.com/postgresthehardway-190407173835/85/Postgres-the-hardway-29-320.jpg)

![10,000 table test … don't do this in production!
I started with the extremely simple python script
~/projects/pg-ora-demo-scripts/memtest $ cat gen_sql.py
for i in range(10001):
print "create table tab"+str(i)+" (pk integer primary key,
col1 varchar(30)); "
and then generate you CREATE SQL statements via
~/projects/pg-ora-demo-scripts/memtest $ python gen_sql.py >
create_table.sql
~/projects/pg-ora-demo-scripts/memtest $ head -3
create_table.sql
create table tab0 (pk integer primary key, col1 varchar(30));
create table tab1 (pk integer primary key, col1 varchar(30));
create table tab2 (pk integer primary key, col1 varchar(30));
custom pgbench script (generated via simple .py script)
[pg10centos7:postgres:~/pg-ora-demo-scripts/memtest/test
2_no_sleep] # cat custom_bench_nowait.sql
select * from tab0;
select * from tab1;
..
select * from tab10000;
using custom pgbench script with -f option
# pgbench -c 10 -j 10 -T 600 -f custom_bench_nowait.sql
&
Source: https://github.com/dgapitts/pg-ora-demo-scripts/tree/master/memtest/setup](https://image.slidesharecdn.com/postgresthehardway-190407173835/85/Postgres-the-hardway-31-320.jpg)
![10,000 table test … don't do this in production!
now running some OS monitoring via simple uptime and lsof
[root@pg10centos7 ~]# for i in {1..1000};do uptime;lsof | grep postgres | wc -l;sleep 60;done
22:57:39 up 1:26, 3 users, load average: 0.05, 0.03, 0.06
14
22:58:39 up 1:27, 3 users, load average: 0.65, 0.17, 0.10
11505
...
23:02:48 up 1:31, 3 users, load average: 15.78, 7.47, 3.03
22496
23:03:53 up 1:33, 3 users, load average: 24.25, 11.45, 4.70
33499
23:05:00 up 1:34, 3 users, load average: 33.60, 16.57, 6.92
44470
...
NB I do have another nice demo rerunning the same pgbench scripts and showing the gains via pgbouncer (with 20 & 10
connection pool) : https://github.com/dgapitts/pg-ora-demo-scripts/tree/master/memtest/test3_pgbouncer_poolsize_10_vs_20](https://image.slidesharecdn.com/postgresthehardway-190407173835/85/Postgres-the-hardway-32-320.jpg)

![SE-Radio 328: Bruce Momjian - Postgres Query Planner
● I was not disappointed … this was an exceptionally good discussion & interesting broadcast, going
from the base principles of Relational DBs, how SQL has become one of the most popular languages
and onto how the Query Planner works
● One comment (47 min) caught my attention:
"An entire team whose sole job was to study query plans … I'm not sure your going to need to do that ..
and when they did switch [to postgres] those people did not have a useful role in the organization"
● I know exactly what Bruce means and if Postgres could reduce/eliminate this operational overhead,
that is seriously impressively.
Ref:: http://www.se-radio.net/2018/06/se-radio-episode-328-bruce-momjian-on-the-postgres-query-planner](https://image.slidesharecdn.com/postgresthehardway-190407173835/85/Postgres-the-hardway-34-320.jpg)

![Setting up pg_plan_advsr - need devtools?
Tattsu … the next problem is harder:
[pg10centos7:postgres:~/test_install/pg_hint_plan-REL10_1_3_2] # make && make install
gcc -O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector-strong
--param=ssp-buffer-size=4 -grecord-gcc-switches -m64 -mtune=generic -DLINUX_OOM_SCORE_ADJ=0 -Wall
-Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Wendif-labels
-Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv
-fexcess-precision=standard -fPIC -I. -I. -I/usr/include/pgsql/server -I/usr/include/pgsql/internal
-D_GNU_SOURCE -I/usr/include/libxml2 -c -o pg_hint_plan.o pg_hint_plan.c
pg_hint_plan.c:54:33: fatal error: access/htup_details.h: No such file or directory
#include "access/htup_details.h"
^
compilation terminated.
make: *** [pg_hint_plan.o] Error 1
the .h doesn't appear to exist on my VM:
[pg10centos7:root:/var/log/pgbouncer] # find / -name 'htup_details.h'
[pg10centos7:root:/var/log/pgbouncer] #](https://image.slidesharecdn.com/postgresthehardway-190407173835/85/Postgres-the-hardway-36-320.jpg)
![Why do I have pg10 server & pg9.2 client tooling?
after checking pg_config it is not quite to clear
[pg10centos7:postgres:~] # pg_config
..
PKGINCLUDEDIR = /usr/include/pgsql
INCLUDEDIR-SERVER = /usr/include/pgsql/server
..
VERSION = PostgreSQL 9.2.24
So while I think the access issue might relate that my psql client/access version is pg9.2 and not pg10
[pg10centos7:postgres:~] # psql
psql (9.2.24, server 10.6)
postgres=# select version();
version
----------------------------------------------------------------------------------------------
PostgreSQL 10.6 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-28),
64-bit
(1 row)](https://image.slidesharecdn.com/postgresthehardway-190407173835/85/Postgres-the-hardway-37-320.jpg)
![Why do I have pg10 server & pg9.2 client tooling?
(continued)
and checking (client?) access library instead of htup_details.h I appear to have htup.h:
[pg10centos7:postgres:~] # ls -ltr /usr/include/pgsql/server/access/h*.h
-rw-r--r--. 1 root root 32901 Aug 23 2018 /usr/include/pgsql/server/access/htup.h
-rw-r--r--. 1 root root 1280 Aug 23 2018 /usr/include/pgsql/server/access/hio.h
-rw-r--r--. 1 root root 6397 Aug 23 2018 /usr/include/pgsql/server/access/heapam.h
-rw-r--r--. 1 root root 13178 Aug 23 2018 /usr/include/pgsql/server/access/hash.h
[pg10centos7:postgres:~] #](https://image.slidesharecdn.com/postgresthehardway-190407173835/85/Postgres-the-hardway-38-320.jpg)





































































