Download to read offline





![How do we do it? Lecture Transcription Spoken Lecture: research project Speech recognition & automated transcription of lectures Why lectures ? Conversational, spontaneous, starts/stops Different from broadcast news, other types of speech recognition Specialized vocabularies James Glass [email_address]](https://image.slidesharecdn.com/iihsopenframework-spokenmedia-100123093513-phpapp01/85/IIHS-Open-Framework-SpokenMedia-9-320.jpg)
![Spoken Lecture Project Processor , browser , workflow Prototyped with lecture & seminar video MIT OCW (~300 hours, lectures) MIT World (~80 hours, seminar speakers) Supported with iCampus MIT/Microsoft Alliance funding James Glass [email_address]](https://image.slidesharecdn.com/iihsopenframework-spokenmedia-100123093513-phpapp01/85/IIHS-Open-Framework-SpokenMedia-10-320.jpg)
![Thank You! Brandon Muramatsu, [email_address] Andrew McKinney, [email_address] ° Unless otherwise specified this work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States License ( creativecommons.org/licenses/by-nc-sa/3.0/us/ )](https://image.slidesharecdn.com/iihsopenframework-spokenmedia-100123093513-phpapp01/85/IIHS-Open-Framework-SpokenMedia-19-320.jpg)

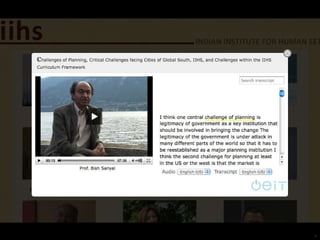
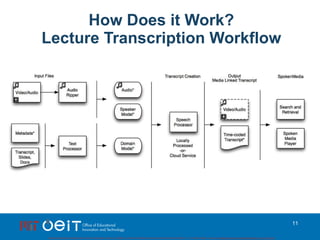
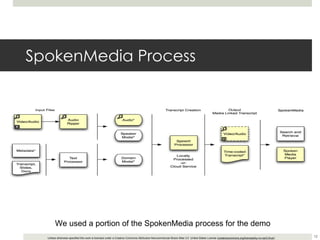
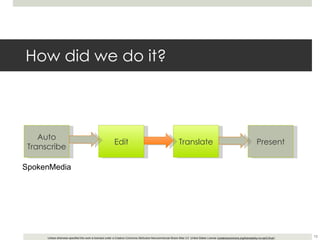
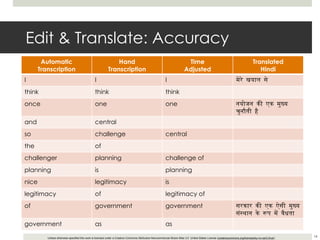
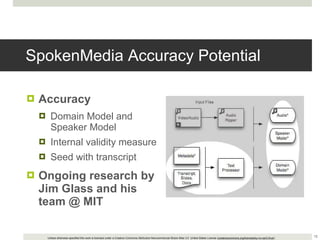
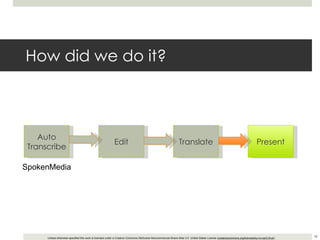
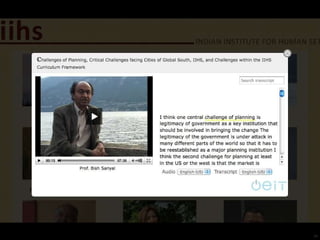
This document outlines a demonstration of automatic transcription and translation of lectures from the IIHS website to increase accessibility to high-quality learning materials. It describes the workflow of transcribing, editing, and translating video content, highlighting the importance of open access to education. The authors emphasize the need for language inclusivity to enhance institutional reach and effectiveness.

































































