Download as PDF, PPTX


![Motivation
Motivation
Super Sense Tagging as sequence labelling problem [1]
Supervised approach
lexical/linguistic features
distributional features
Main motivation: tackle the data sparseness problem using word
similarity in a WordSpace
Pierpaolo Basile (basilepp@di.uniba.it) SST Uniba 24/01/2012 2 / 12](https://image.slidesharecdn.com/sstevalita2011basilepierpaolo-120730083923-phpapp02/85/Sst-evalita2011-basile_pierpaolo-2-320.jpg)
![WordSpace
WordSpace
You shall know a word
by the company it
keeps! [5]
Words are represented as
points in a geometric
space
Words are related if they
are close in that space
Pierpaolo Basile (basilepp@di.uniba.it) SST Uniba 24/01/2012 3 / 12](https://image.slidesharecdn.com/sstevalita2011basilepierpaolo-120730083923-phpapp02/85/Sst-evalita2011-basile_pierpaolo-3-320.jpg)
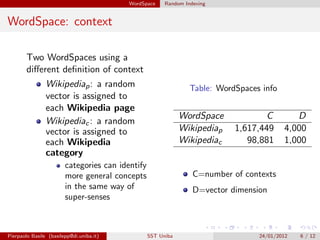
![WordSpace Random Indexing
WordSpace: Random Indexing
Random Indexing [4]
builds WordSpace using document as context
no matrix factorization required
word-vectors are inferred using an incremental strategy
1 a random vector is assigned to each context
sparse, high-dimensional and ternary ({-1, 0, 1})
a small number of randomly distributed non-zero elements
2 random vectors are accumulated incrementally by analyzing contexts in
which terms occur
word-vector assigned to each word is the sum of the random vectors of
the contexts in which the term occur
Pierpaolo Basile (basilepp@di.uniba.it) SST Uniba 24/01/2012 4 / 12](https://image.slidesharecdn.com/sstevalita2011basilepierpaolo-120730083923-phpapp02/85/Sst-evalita2011-basile_pierpaolo-4-320.jpg)
![WordSpace Random Indexing
WordSpace: Random Indexing
Formally Random Indexing is based on Random Projection [2]
An,m · R m,k = B n,k k<m (1)
where An,m is, for example, a term-doc matrix
After projection the distance between points is preserved: d = c· dr
Pierpaolo Basile (basilepp@di.uniba.it) SST Uniba 24/01/2012 5 / 12](https://image.slidesharecdn.com/sstevalita2011basilepierpaolo-120730083923-phpapp02/85/Sst-evalita2011-basile_pierpaolo-5-320.jpg)
![Methodology
Methodology
Learning method: LIBLINEAR (SVM) [3]
Features
1 word, lemma, PoS-tag, the first letter of the PoS-tag
2 the super-sense assigned to the most frequent sense of the word
computed according to sense frequency in MultiSemCor
3 word starts with an upper-case character
4 grammatical conjugation (e.g. -are, -ere and -ire for Italian verbs)
5 distributional features: word-vector in the WordSpace
Pierpaolo Basile (basilepp@di.uniba.it) SST Uniba 24/01/2012 7 / 12](https://image.slidesharecdn.com/sstevalita2011basilepierpaolo-120730083923-phpapp02/85/Sst-evalita2011-basile_pierpaolo-7-320.jpg)
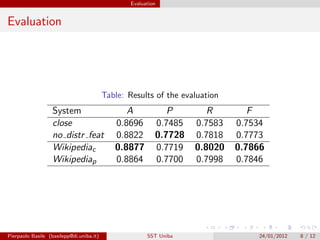





1) The document discusses super sense tagging using distributional features from a WordSpace, which represents words as vectors in a geometric space based on their contexts. 2) Two WordSpaces were created using different contexts - Wikipedia pages and categories. 3) The method used SVM classification with lexical, part-of-speech, and distributional features from the WordSpaces. 4) Evaluation showed the distributional features improved recall over the baseline, demonstrating they help address data sparseness in super sense tagging.













![[Emnlp] what is glo ve part iii - towards data science](https://cdn.slidesharecdn.com/ss_thumbnails/emnlpwhatisglovepartiii-towardsdatascience-200228052047-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Emnlp] what is glo ve part ii - towards data science](https://cdn.slidesharecdn.com/ss_thumbnails/emnlpwhatisglovepartii-towardsdatascience-200228052050-thumbnail.jpg?width=640&height=640&fit=bounds)













































