Download as PDF, PPTX


















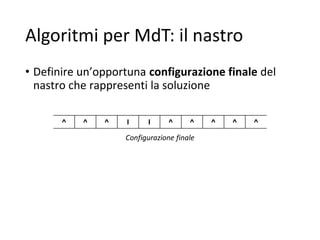










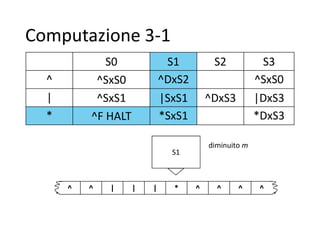



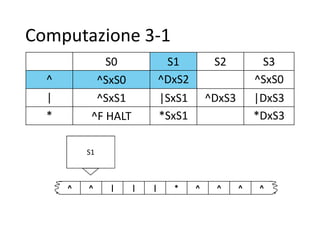


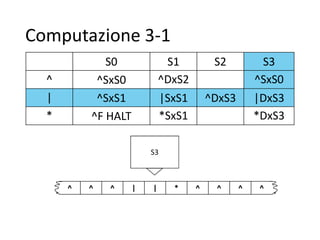























Il documento descrive la macchina di Turing, un modello astratto di calcolo introdotto da Alan Turing nel 1936, utilizzato per fornire una definizione formale di algoritmo e affrontare problemi di decisione. Viene illustrata la struttura e il funzionamento della macchina, compresi il nastro, la testina di lettura/scrittura e l'unità di controllo, con esempi pratici di algoritmi per operazioni aritmetiche come la sottrazione. Inoltre, si discute la tesi di Church-Turing, evidenziando che le funzioni calcolabili da una macchina di Turing coincidono con quelle calcolabili da altri formalismi, come i linguaggi di programmazione moderni.















































