Downloaded 296 times




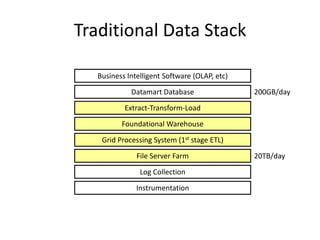

The document discusses the differences between schema-on-read and schema-on-write data systems. Schema-on-read, exemplified by Hadoop, allows data to enter the system in its original format, enabling real-time adaptability and flexibility, while schema-on-write requires a predefined structure, limiting agility. The presentation highlights the benefits of schema-on-read for handling complex and evolving data structures, as well as its application in modern data processing.





















































