This document discusses effective usage of Django's Object-Relational Mapping (ORM), highlighting common mistakes and performance issues. It emphasizes the importance of using methods like filter(), exists(), and select_related to optimize database queries, reduce unnecessary data fetching, and handle database concurrency correctly. Additionally, it covers advanced techniques such as annotations, subqueries, and transaction management to improve application performance and prevent race conditions.







![Tools
• django.db.connection (Make sure your Django
DEBUG setting is set to True)
>>> from django.db import connection
>>> Author.objects.all()
<QuerySet [<Author: Michael Armstrong>, ..., <Author: GEORGE PACKER>]>
>>> connection.queries
[{'sql': 'SELECT "books_author"."id", "books_author"."first_name",
"books_author"."last_name", "books_author"."email" FROM "books_author" LIMIT 21',
'time': '0.007'}]](https://image.slidesharecdn.com/djangoorm-180223162130/85/The-effective-use-of-Django-ORM-7-320.jpg)
![Tools
• django.db.connection (Make sure your Django
DEBUG setting is set to True)
>>> from django.db import connection
>>> Author.objects.all()
<QuerySet [<Author: Michael Armstrong>, ..., <Author: GEORGE PACKER>]>
>>> connection.queries
[{'sql': 'SELECT "books_author"."id", "books_author"."first_name",
"books_author"."last_name", "books_author"."email" FROM "books_author" LIMIT 21',
'time': '0.007'}]
• sql -- The raw SQL statement
• time -- How long the statement took to execute, in seconds.](https://image.slidesharecdn.com/djangoorm-180223162130/85/The-effective-use-of-Django-ORM-8-320.jpg)

![Tools
• shell_plus command with option --print-sql
from django-extensions project
>>> Author.objects.all()
SELECT "books_author"."id", "books_author"."first_name",
"book_author"."last_name","books_author"."email" FROM "books_author" LIMIT
21
Execution time: 0.001993s [Database: default]](https://image.slidesharecdn.com/djangoorm-180223162130/85/The-effective-use-of-Django-ORM-10-320.jpg)

![Mistake #1
>>> queryset = Author.objects.all()
>>> [author for author in queryset if author.email.endswith('@gmail.com')]](https://image.slidesharecdn.com/djangoorm-180223162130/85/The-effective-use-of-Django-ORM-13-320.jpg)
![Mistake #1
Use filter() and exclude() method to do
filtering in the database.
>>> Author.objects.filter(email__icontains='@gmail.com')
>>> queryset = Author.objects.all()
>>> [author for author in queryset if author.email.endswith('@gmail.com')]](https://image.slidesharecdn.com/djangoorm-180223162130/85/The-effective-use-of-Django-ORM-14-320.jpg)






![Mistake #5
Don’t fetch data you don’t need
# Retrieve values as a dictionary
Book.objects.all().values('name', 'price')
< QuerySet[{'name': 'Rat Of The Stockades', 'price': Decimal('4.28')}, ...] >
# Retrieve values as a tuple
Book.objects.all().values_list('name', 'price')
< QuerySet[('Rat Of The Stockades', Decimal('4.28')), ...] >
# Use QuerySet.defer() and only()
Book.objects.only('name', 'price').all()
Book.objects.defer('price').all()](https://image.slidesharecdn.com/djangoorm-180223162130/85/The-effective-use-of-Django-ORM-21-320.jpg)







![prefetch_related
# Queries 2, Execution time: 0.002458s
def authors():
queryset = Author.objects.prefetch_related('books')
authors = []
for author in queryset:
books = [book.name for book in author.books.all()]
authors.append({
'name': author.get_full_name(),
'books': books
})
return authors
Use the prefetch_related for joining many-to-
many and many-to-one objects](https://image.slidesharecdn.com/djangoorm-180223162130/85/The-effective-use-of-Django-ORM-29-320.jpg)
![Be careful with prefetch_related
# Queries 18, Execution time: 0.032458s
def top_authors():
queryset = Author.objects.prefetch_related('books')
authors = []
for author in queryset:
books = [book.name for book in author.books.filter(average_rating__gt=3)]
authors.append({
'name': author.get_full_name(),
'books': books
})
return authors](https://image.slidesharecdn.com/djangoorm-180223162130/85/The-effective-use-of-Django-ORM-30-320.jpg)
![Using Prefetch with to_attr
from django.db.modelsimport Prefetch
# Queries 2, Execution time: 0.008458s
def top_authors():
queryset = Author.objects.prefetch_related(
Prefetch('books',
queryset=Book.objects.filter(average_rating__gt=3),
to_attr='top_books')
)
authors = []
for author in queryset:
books = [book.name for book in author.top_books]
authors.append({'name': author.get_full_name(), 'books': books})
return authors](https://image.slidesharecdn.com/djangoorm-180223162130/85/The-effective-use-of-Django-ORM-31-320.jpg)








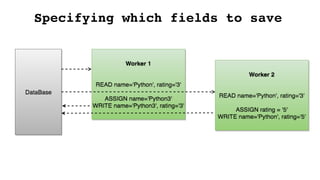
![Specifying which fields to save
def set_name(id, value):
instance = Book.objects.get(id=id)
instance.name = value
instance.save(update_fields=['name'])
def set_rating(id, value):
instance = Book.objects.get(id=id)
instance.average_rating = value
instance.save(update_fields=['average_rating'])
One possible solution is to identify the
updated fields](https://image.slidesharecdn.com/djangoorm-180223162130/85/The-effective-use-of-Django-ORM-41-320.jpg)
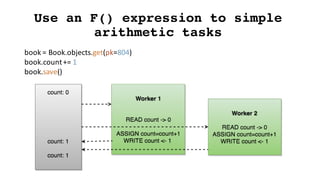


![The code
def create_payment(collection_id):
with transaction.atomic():
book_collection = BookCollection.objects.select_releted('user').get(id=collection_id)
amount = book_collection.book_set.all().aggregate(total=Sum('price'))['total']
if book_collection.user.balance>= amount:
user.reduce_balance(amount)
Payment.objects.create(amount=amount, book_collection=book_collection)
else:
raise Exception('Insufficient funds')](https://image.slidesharecdn.com/djangoorm-180223162130/85/The-effective-use-of-Django-ORM-45-320.jpg)
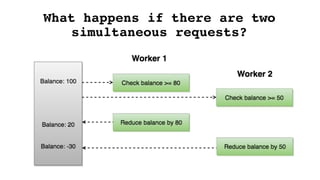
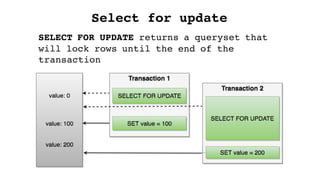
![def create_payment(collection_id):
# Wrap in a database transaction
with transaction.atomic():
book_collection = BookCollection.objects.get(id=collection_id)
amount = book_collection.book_set.all().aggregate(total=Sum('price'))['total']
# Wait for a lock
user = User.objects.select_for_update().get(id=book_collection.user_id)
if user.balance >= amount:
user.reduce_balance(amount)
Payment.objects.create(amount=amount, book_collection=book_collection)
else:
raise Exception('Insufficient funds')
Select for update](https://image.slidesharecdn.com/djangoorm-180223162130/85/The-effective-use-of-Django-ORM-49-320.jpg)
![with transaction.atomic():
User.objects.select_for_update().filter(id__in=[804, 806])
...
Select for update – Querysets are
lazy!
In this case, the select_for_update will never
be run. Wrap the select_for_update in a bool if
you don't evaluate them straight away.
bool(User.objects.select_for_update().filter(id__in=[804, 806]))](https://image.slidesharecdn.com/djangoorm-180223162130/85/The-effective-use-of-Django-ORM-50-320.jpg)
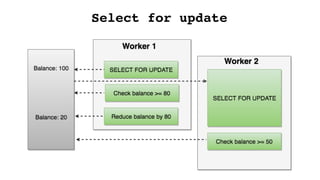
![Select for update – Preventing
deadlocks
# Worker 1
with transaction.atomic():
ids = [804, 805]
bool(User.objects.select_for_update().filter(id__in=ids))
...
# Worker 2
with transaction.atomic():
ids = [805, 804]
bool(User.objects.select_for_update().filter(id__in=ids))
...
Waiting for each other](https://image.slidesharecdn.com/djangoorm-180223162130/85/The-effective-use-of-Django-ORM-51-320.jpg)
![Select for update – Preventing
deadlocks
When using select_for_updates on multiple
records, make sure you acquire the locks in a
consistent order.
# Worker 1
with transaction.atomic():
ids = [804, 805]
bool(User.objects.select_for_update().filter(id__in=ids).order_by('id'))
...](https://image.slidesharecdn.com/djangoorm-180223162130/85/The-effective-use-of-Django-ORM-52-320.jpg)




![Naver속도의, 속도에 의한, 속도를 위한 몽고DB (네이버 컨텐츠검색과 몽고DB) [Naver]](https://cdn.slidesharecdn.com/ss_thumbnails/naver-190916181334-thumbnail.jpg?width=640&height=640&fit=bounds)








![[PRML勉強会資料] パターン認識と機械学習 第3章 線形回帰モデル (章頭-3.1.5)(p.135-145)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlp-150228215621-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[143] Modern C++ 무조건 써야 해?](https://cdn.slidesharecdn.com/ss_thumbnails/143deview2018modernc9-181011024146-thumbnail.jpg?width=640&height=640&fit=bounds)




![2017 12 09_데브루키_리얼타임 렌더링_입문편(3차원 그래픽스[저자 : 한정현] 참조)](https://cdn.slidesharecdn.com/ss_thumbnails/20171209-171227014347-thumbnail.jpg?width=640&height=640&fit=bounds)








![[NDC2017] 딥러닝으로 게임 콘텐츠 제작하기 - VAE를 이용한 콘텐츠 생성 기법 연구 사례](https://cdn.slidesharecdn.com/ss_thumbnails/v072-170426075401-thumbnail.jpg?width=640&height=640&fit=bounds)







































