Downloaded 550 times

















![Monitoring Logstash metrics
filter {
metrics {
meter => "events"
add_tag => "metric"
}
}
output {
if “metric” in [tags] [
stdout {
codec => line {
format => “Rate: %{events.rate_1m}”
}
}
}](https://image.slidesharecdn.com/elk-at-linkedin-150502201620-conversion-gate01/85/ELK-at-LinkedIn-Kafka-scaling-lessons-learned-20-320.jpg)

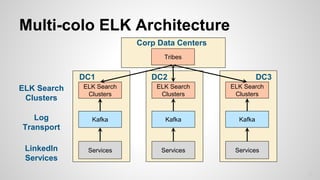
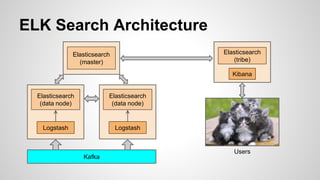
The document discusses the implementation and scaling of the ELK stack (Elasticsearch, Logstash, Kibana) at LinkedIn, focusing on its integration with Kafka for log processing. It highlights challenges such as data transport, security, and resource management, while showcasing the scale of operations with 100+ clusters handling billions of documents. The future plans include expanding cluster usage and further increasing data indexing capabilities.
















































![How Big Brands are Taking Your Traffic in Alberta [Data Inside].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/howbigbrandsaretakingyourtrafficinalbertadatainside-260123180142-42d276f3-thumbnail.jpg?width=640&height=640&fit=bounds)









