Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
智片
Uploaded by
智志 片桐
PDF, PPTX
932 views
再考: お買い得物件を機械学習で見つける方法
修正版: https://speakerdeck.com/ktgrstsh/rethink-method-to-find-cheap-rental-houses-by-machine-learning
Data & Analytics
◦
Related topics:
Anomaly Detection
•
Read more
2
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 36
2
/ 36
3
/ 36
4
/ 36
5
/ 36
6
/ 36
7
/ 36
8
/ 36
9
/ 36
10
/ 36
11
/ 36
12
/ 36
13
/ 36
14
/ 36
15
/ 36
16
/ 36
17
/ 36
18
/ 36
19
/ 36
20
/ 36
21
/ 36
22
/ 36
23
/ 36
24
/ 36
25
/ 36
26
/ 36
27
/ 36
28
/ 36
29
/ 36
30
/ 36
31
/ 36
32
/ 36
33
/ 36
34
/ 36
35
/ 36
36
/ 36
More Related Content
PDF
bayesplot を使ったモンテカルロ法の実践ガイド
by
智志 片桐
PPTX
0610 TECH & BRIDGE MEETING
by
健司 亀本
PDF
レコメンドアルゴリズムの基本と周辺知識と実装方法
by
Takeshi Mikami
PDF
Anomaly detection survey
by
ぱんいち すみもと
PDF
Pythonで動かして学ぶ機械学習入門_予測モデルを作ってみよう
by
洋資 堅田
PDF
異常検知 - 何を探すかよく分かっていないものを見つける方法
by
MapR Technologies Japan
PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoWebmining#17
by
Yuya Unno
PDF
【Tech Trend Talk vol.7】社外向け勉強会「スコア予測の実践 -(GIG)」
by
GIG inc.
bayesplot を使ったモンテカルロ法の実践ガイド
by
智志 片桐
0610 TECH & BRIDGE MEETING
by
健司 亀本
レコメンドアルゴリズムの基本と周辺知識と実装方法
by
Takeshi Mikami
Anomaly detection survey
by
ぱんいち すみもと
Pythonで動かして学ぶ機械学習入門_予測モデルを作ってみよう
by
洋資 堅田
異常検知 - 何を探すかよく分かっていないものを見つける方法
by
MapR Technologies Japan
Jubatusのリアルタイム分散レコメンデーション@TokyoWebmining#17
by
Yuya Unno
【Tech Trend Talk vol.7】社外向け勉強会「スコア予測の実践 -(GIG)」
by
GIG inc.
Similar to 再考: お買い得物件を機械学習で見つける方法
PDF
Jubatusにおける大規模分散オンライン機械学習
by
Preferred Networks
PDF
Log解析の超入門
by
菊池 佑太
PDF
実践機械学習 — MahoutとSolrを活用したレコメンデーションにおけるイノベーション - 2014/07/08 Hadoop Conference ...
by
MapR Technologies Japan
PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoNLP#9
by
Yuya Unno
PDF
Hivemall LT @ Machine Learning Casual Talks #3
by
Makoto Yui
PDF
TensorFlow を使った 機械学習ことはじめ (GDG京都 機械学習勉強会)
by
徹 上野山
PPTX
機械学習を用いた異常検知入門
by
michiaki ito
PDF
JAWSDAYS 2014 ACEに聞け! EMR編
by
陽平 山口
PPTX
0517 TECH & BRIDGE MEETING
by
健司 亀本
PDF
Elastic ML Introduction
by
Hiroshi Yoshioka
PDF
MapReduceによる大規模データを利用した機械学習
by
Preferred Networks
PPTX
R超入門機械学習をはじめよう
by
幹雄 小川
PDF
第1回 Jubatusハンズオン
by
JubatusOfficial
PDF
第1回 Jubatusハンズオン
by
Yuya Unno
PDF
Sakusaku svm
by
antibayesian 俺がS式だ
PDF
Machine Learning on Graph Data @ ICML 2019
by
emakryo
PDF
Tokyo r15 異常検知入門
by
Yohei Sato
PDF
bigdata2012ml okanohara
by
Preferred Networks
PDF
Jubatusの特徴変換と線形分類器の仕組み
by
JubatusOfficial
PDF
Pythonによる機械学習入門 ~Deep Learningに挑戦~
by
Yasutomo Kawanishi
Jubatusにおける大規模分散オンライン機械学習
by
Preferred Networks
Log解析の超入門
by
菊池 佑太
実践機械学習 — MahoutとSolrを活用したレコメンデーションにおけるイノベーション - 2014/07/08 Hadoop Conference ...
by
MapR Technologies Japan
Jubatusのリアルタイム分散レコメンデーション@TokyoNLP#9
by
Yuya Unno
Hivemall LT @ Machine Learning Casual Talks #3
by
Makoto Yui
TensorFlow を使った 機械学習ことはじめ (GDG京都 機械学習勉強会)
by
徹 上野山
機械学習を用いた異常検知入門
by
michiaki ito
JAWSDAYS 2014 ACEに聞け! EMR編
by
陽平 山口
0517 TECH & BRIDGE MEETING
by
健司 亀本
Elastic ML Introduction
by
Hiroshi Yoshioka
MapReduceによる大規模データを利用した機械学習
by
Preferred Networks
R超入門機械学習をはじめよう
by
幹雄 小川
第1回 Jubatusハンズオン
by
JubatusOfficial
第1回 Jubatusハンズオン
by
Yuya Unno
Sakusaku svm
by
antibayesian 俺がS式だ
Machine Learning on Graph Data @ ICML 2019
by
emakryo
Tokyo r15 異常検知入門
by
Yohei Sato
bigdata2012ml okanohara
by
Preferred Networks
Jubatusの特徴変換と線形分類器の仕組み
by
JubatusOfficial
Pythonによる機械学習入門 ~Deep Learningに挑戦~
by
Yasutomo Kawanishi
再考: お買い得物件を機械学習で見つける方法
1.
再考: お買い得物件を機械学習で見つける方法 @ill-identified 2019/6/29 1
2.
自己紹介 • Twitter: @ill_identified •
ブログ: http://ill-identified.hatenablog.com/ • LinkedIn: https: //www.linkedin.com/in/satoshi-katagiri/ • Twitter: https://twitter.com/ill_Identified • github: https://github.com/Gedevan-Aleksizde • 現在の勤務先: Web 広告の会社 2
3.
イントロダクション • Morishita (2019)
https://speakerdeck.com/ morishita/rdeomai-ide-wu-jian-wotan-se (Tokyo.R 77 回) • shokosaka (2017) (個人ブログ) http://www. analyze-world.com/entry/2017/11/09/061023 • 本当に機械学習でお買い得物件を求められるのか? 3
4.
「マサカリ」を投げに来たわけではない Figure 1: Decapitation
of Pedro I, public domain; Nicholas of Myla at the Council of Nicaea, public domain • 機械学習が何をしているのか, どうやったら活用できるの かを建設的に議論したい 4
5.
異常検知の教科書 • 今回は異常検知 (anomaly
detection) のなかでも, 特に外れ 値検出 (outlier detection) 分野の話 5
6.
そもそも何がお買い得物件? • 家賃が高いよりも安いほうがいい • ただし留保条件もある •
広さはどれくらい • トイレと風呂は, ガスコンロはあるか, 電気調理器はあるか, • 条件を満たすもののなかで, なるべく安いものが欲しい 6
7.
どうやって求めるか • 冒頭の 2
人は不動産情報を特徴量に, 賃料を目的変数にし て機械学習を適用 • それぞれランダムフォレストと XGBoost • 賃料を目的変数 y, 物件情報による特徴量を x とおいて, 条 件付き確率を仮定 y ∼p(y | x) • x に対する平均的な y を条件付き期待値関数 y = µ(x) :=Ey | x • 機械学習で µ(x) を近似した予測モデル ˆy = ˆµ(x) を作り, 残差の大きいものが外れ値 = お買得物件 ri :=yi − ˆµ(x) 7
8.
本当に? 本当に? 8
9.
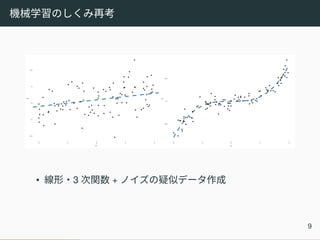
機械学習のしくみ再考 • 線形・3 次関数
+ ノイズの疑似データ作成 9
10.
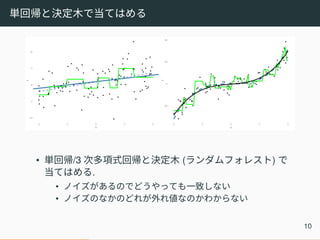
単回帰と決定木で当てはめる • 単回帰/3 次多項式回帰と決定木
(ランダムフォレスト) で 当てはめる. • ノイズがあるのでどうやっても一致しない • ノイズのなかのどれが外れ値なのかわからない 10
11.
モデルが先か外れ値が先か • 外れ値検出は正常状態を数式で正確に表せるのが前提 • 数式は機械学習でデータに当てはめて求める •
データの外れ値は機械学習の数式から判定する • 数式は機械学習でデータに当てはめて求める • データの外れ値は機械学習の数式から ・数式は機械学習でデータに当ては ・データの外れ値は機械学習の ・数式は機械学習でデータ ・データの外れ値は機械学 ・数式は機械学習でデ ・データの外れ値は機 ・数式は機械学習 ・データの外れ値 11
12.
ここまでのまとめ • 機械学習はデータの数値に当てはめているだけ • 単回帰でも
XGBoost でも深層学習でも同じ • 交差検証 (CV) をやるのはそのため • 検証データにも未知の外れ値があるとどうしようもない • 正常値・外れ値のラベルがないまま予測残差を見ても仕方 がない • MSE・RMSE・MAE とにかく意味がない • 比較検証が難しい 12
13.
補足: Morishita (2019)
の方法 • 訓練データは物件を見つけたい地域以外の場所 • 訓練データを標準的な物件の情報とみなしていると明記し ている. • 偏りによる共変量シフトを Importance Weight で補正 • 訓練データにも外れ値はある • 地域によって重点される特徴量は違う. 共変量シフトの前 提に疑問 13
14.
論点 • もっと正確にお買得物件を見つける方法はないか? • 個人にとって実用的なものか? •
不動産情報サイトにとって実用的か? • 検証方法はどうすべきか? 14
15.
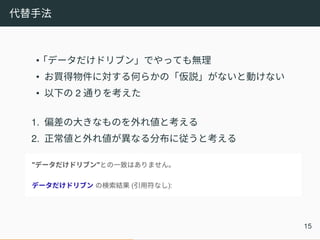
代替手法 •「データだけドリブン」でやっても無理 • お買得物件に対する何らかの「仮説」がないと動けない • 以下の
2 通りを考えた 1. 偏差の大きなものを外れ値と考える 2. 正常値と外れ値が異なる分布に従うと考える 15
16.
代替手法 1: Quantile
Regression Forest • Random forest はいくつもの決定木のアンサンブル学習 • R では ranger か randomForest パッケージで可能 (前 者がおすすめ) • 簡単な解説は自分のブログ (ここ) とか • Meinshausen (2006) による qunatile regression forest • 平均ではなく分位点 (中央値) に合わせる • 分散の大きな外れ値ならこれで検知できる? • R では ranger または quantregForest パッケージ で可能 16
17.
代替手法 2: Gaussian
Finite Mixture Model • ガウシアン有限混合回帰モデル • 複数の分布の合成でモデルを表現する. • データが K 個の分布のどれかから発生している: y = K∑ k=1 πkµk(y | x) • 各個体が k のどの分布に属したかの確率を計算できる. • おおざっぱに言うと本質的にはクラスタリングと同じ •「無限」混合はいわゆるノンパラベイズ • flexmix パッケージで可能 • 使い方は Leisch (2004) 参照 • 日本語なら ここ の解説が実用的でくわしい 17
18.
どう検証するか • 正例/負例のラベルがない • 定量的な評価のしようがない •
疑似データを作るか • 生データと違う分布. 実用的ではない • 苦肉の策 • 生データの一部を修正した疑似データを検出できるか判 定する 18
19.
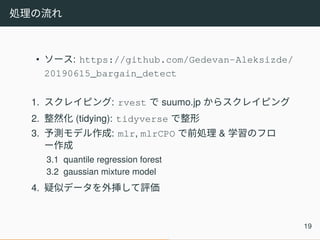
処理の流れ • ソース: https://github.com/Gedevan-Aleksizde/ 20190615_bargain_detect 1.
スクレイピング: rvest で suumo.jp からスクレイピング 2. 整然化 (tidying): tidyverse で整形 3. 予測モデル作成: mlr, mlrCPO で前処理 & 学習のフロ ー作成 3.1 quantile regression forest 3.2 gaussian mixture model 4. 疑似データを外挿して評価 19
20.
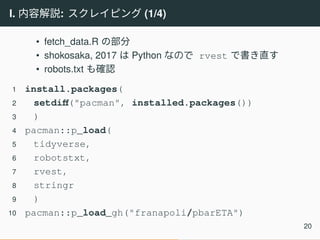
I. 内容解説: スクレイピング
(1/4) • fetch_data.R の部分 • shokosaka, 2017 は Python なので rvest で書き直す • robots.txt も確認 1 install.packages( 2 setdiff("pacman", installed.packages()) 3 ) 4 pacman::p_load( 5 tidyverse, 6 robotstxt, 7 rvest, 8 stringr 9 ) 10 pacman::p_load_gh("franapoli/pbarETA") 20
21.
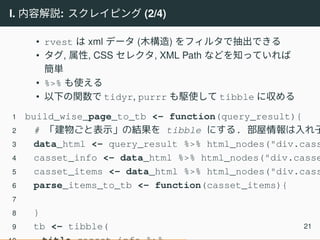
I. 内容解説: スクレイピング
(2/4) • rvest は xml データ (木構造) をフィルタで抽出できる • タグ, 属性, CSS セレクタ, XML Path などを知っていれば 簡単 • %>% も使える • 以下の関数で tidyr, purrr も駆使して tibble に収める 1 build_wise_page_to_tb <- function(query_result){ 2 # 「建物ごと表示」の結果を tibble にする. 部屋情報は入れ子 3 data_html <- query_result %>% html_nodes("div.cass 4 casset_info <- data_html %>% html_nodes("div.casse 5 casset_items <- data_html %>% html_nodes("div.cass 6 parse_items_to_tb <- function(casset_items){ 7 8 } 9 tb <- tibble( 21
22.
I. 内容解説: スクレイピング
(3/4) • これを suumo の検索結果ページから取得. • 取得したのは, 物件名, 間取り, 専有面積, 家賃, 管理費, 階 数, 住所, 最寄り駅, 築年数など • 物件個別ページはスクレイピングしていない • ページ内から検索結果の全ページ数も取得 • これを 23 区それぞれの検索クエリ結果に対して実行 • 進捗がわかりづらいのでプログレスバーを使うと良い (pbarETA がおすすめ) 22
23.
I. 内容解説: スクレイピング
(4/4) Figure 2: スクレイピングしたデータ Figure 3: 入れ子部分の部屋別情報 23
24.
II. 内容解説: 整然化
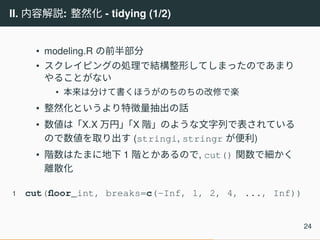
- tidying (1/2) • modeling.R の前半部分 • スクレイピングの処理で結構整形してしまったのであまり やることがない • 本来は分けて書くほうがのちのちの改修で楽 • 整然化というより特徴量抽出の話 • 数値は「X.X 万円」「X 階」のような文字列で表されている ので数値を取り出す (stringi, stringr が便利) • 階数はたまに地下 1 階とかあるので, cut() 関数で細かく 離散化 1 cut(floor_int, breaks=c(-Inf, 1, 2, 4, ..., Inf)) 24
25.
II. 内容解説: 整然化
- tidying (2/2) • 間取りは L, D, K などそれぞれでダミー変数を立てる • 住所などテキストは feature hashing (hash tricking) で強制 的に多次元の数値列にする (FeatureHashing が便利) • スコア勝負じゃないのでこの辺は手抜き 25
26.
III. 内容解説: 予測モデル作成
(1/4) • mlr, mlrCPO を使う • mlr の日本語の解説は以下を参照 • @nozma によるチュートリアル翻訳 + 補足説明 •『mlr パッケージチュートリアル - Quick Walkthrough 編』 •『R の機械学習パッケージ mlr のチュートリアル 3 (ベンチマ ーク試験から可視化まで)』 • kanamichi による『mlr チュートリアルの写経(その 1)』 (2015 年) • 『モデルを跨いでデータを見たい』(第 76 回 Tokyo.R) 26
27.
III. 内容解説: 予測モデル作成
(2/4) • mlr では 1. データフレームと目的変数情報をタスク (task) オブジェ クトとして作成 tsk <- makeRegrTask( id="hoge", data=df, target="rent_price") 2. 学習器オブジェクト (learner) を作成 (listLearners() で使用できるものを一覧できる) 3. MODEL <- train(LEARNER, TASK) で学習結果を得る. 4. predict(MODEL, [DATA/TASK]) で予測値出力 27
28.
III. 内容解説: 予測モデル作成
(3/4) • 登録されていないものは自作するしかない (resgist_mlr_learners.R の部分). • 今回は flexmix も renger (quantreg バージョン) も登録 されていなかった. • 以下を見れば作り方はだいたいわかる (たぶん) •『Integrating Another Learner』 • XGBoost の登録例 28
29.
III. 内容解説: 予測モデル作成
(4/4) • mlrCPO (Composable Preprocessing Operators for MLR) は名前通り前処理関係の機能を強化する • 前処理クラスは mlr にもあるけど数が少ない • cpoScale() %>>% makeLearner() のように %>>% で learner オブジェクトに前処理フローを付加できる • scikit-learn の PipeLine っぽい • ただしこちらもそこまで種類は豊富ではない tidyverse だけ でいいんじゃね? • 目的変数を変換して, predict() 時に逆変換する cpoLogTrafoRegr() は便利 • さあいくぞ 29
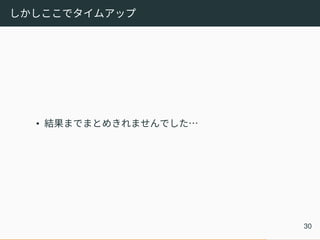
30.
しかしここでタイムアップ • 結果までまとめきれませんでした… 30
31.
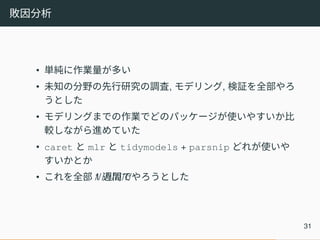
敗因分析 • 単純に作業量が多い • 未知の分野の先行研究の調査,
モデリング, 検証を全部やろ うとした • モデリングまでの作業でどのパッケージが使いやすいか比 較しながら進めていた • caret と mlr と tidymodels + parsnip どれが使いや すいかとか • これを全部 //1 ///週///間///でやろうとした 31
32.
いかがでしたか? • いかがでしたか? お買得物件を正確に発見する方法を調べ てみましたが残念ながらよく分かりませんでした! •
ill_identified 先生の今後の挽回に期待ですね! 32
33.
次は時間内に終わる手堅いテーマを選ぶので許してください. Figure 4: Saint
Peter of Verona, by Vecchietta, public domain 33
34.
今回のまとめ • 教師のない教師あり機械学習が行き場を見失う • 予測モデルの適切な評価をして使おう •
tidyverse, mlr, mlrCPO あたりを組み合わせるととて も便利 • 研究は計画的に 34
35.
参考文献 i Aggarwal, Charu
C. (2017) Outlier Analysis, Cham: Springer International Publishing, DOI: 10.1007/978-3-319-47578-3, DOI: 10.1007/978-3-319-47578-3. Chandola, Varun, Arindam Banerjee, and Vipin Kumar (2009) “Anomaly Detection: A Survey,” ACM Computing Surveys, Vol. 41, No. 3, pp. 1-58, July, DOI: 10.1145/1541880.1541882. Leisch, Friedrich (2004) “FlexMix: A General Framework for Finite Mixture Models and Latent Class Regression in R,” Journal of Statistical Software, Vol. 11, No. 8, DOI: 10.18637/jss.v011.i08. 35
36.
参考文献 ii Meinshausen, Nicolai
(2006) “Quantile Regression Forests,” Journal of Machine Learning Research, Vol. 7, pp. 983-999. Morishita, Gota (2019) 「R でお買い得物件を探せ」,4 月. shokosaka (2017) 「機械学習を使って東京 23 区のお買い得賃 貸物件を探してみた」,11 月. 井出剛 (2015) 『入門機械学習による異常検知 - R による実践 ガイド -』,コロナ社. 36
Download

















![III. 内容解説: 予測モデル作成 (2/4)
• mlr では
1. データフレームと目的変数情報をタスク (task) オブジェ
クトとして作成 tsk <- makeRegrTask( id="hoge",
data=df, target="rent_price")
2. 学習器オブジェクト (learner) を作成
(listLearners() で使用できるものを一覧できる)
3. MODEL <- train(LEARNER, TASK) で学習結果を得る.
4. predict(MODEL, [DATA/TASK]) で予測値出力
27](https://image.slidesharecdn.com/presen-190629061335/85/slide-27-320.jpg)