Download to read offline


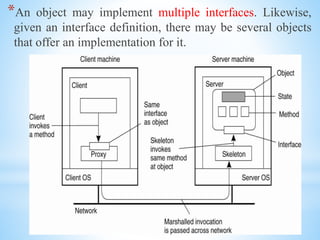





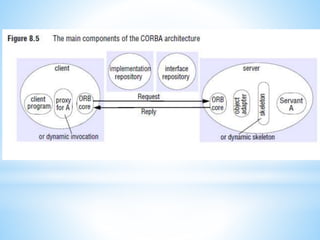







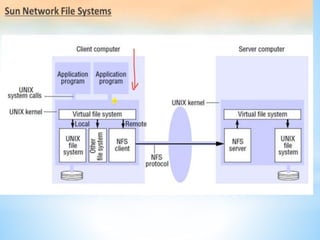




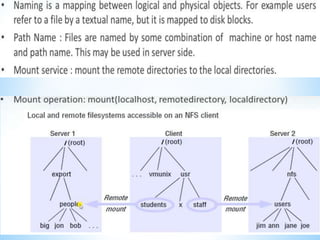



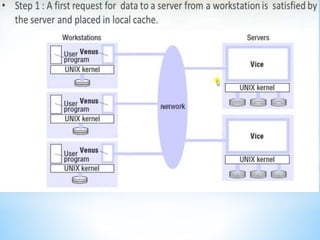





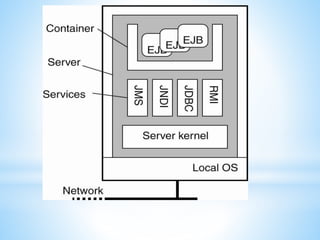







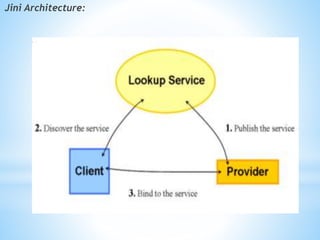


The document discusses several distributed systems technologies including CORBA, distributed file systems like NFS, and Java distributed computing frameworks like Enterprise Java Beans and Jini. CORBA allows software components written in different languages and running on different computers to communicate. Distributed file systems like NFS provide location transparency and redundancy. EJB and Jini simplify building distributed applications by providing services like transactions and naming automatically.
























































