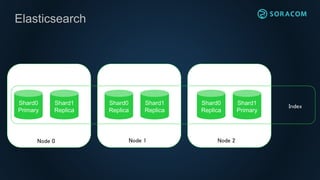
Elasticsearch – LuceneIndex
Shard (Lucene Index)
Lucene IndexはSegmentと呼ばれるファイルの集合。
Segment
Segment
Segment
Inverted Index
Inverted Index
Inverted Index
33.
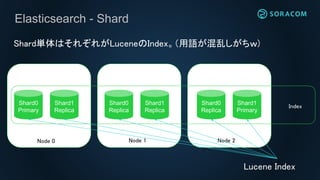
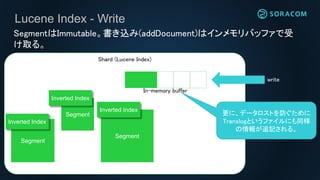
Lucene Index -Write
Shard (Lucene Index)
SegmentはImmutable。書き込み(addDocument)はインメモリバッファで受
け取る。
Segment
Segment
Segment
Inverted Index
Inverted Index
Inverted Index
In-memory buffer
write
更に、データロストを防ぐために
Translogというファイルにも同様
の情報が追記される。
34.
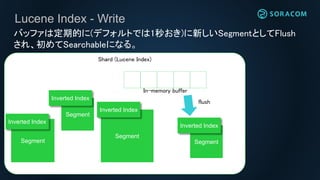
Lucene Index -Write
Shard (Lucene Index)
バッファは定期的に(デフォルトでは1秒おき)に新しいSegmentとしてFlush
され、初めてSearchableになる。
Segment
Segment
Segment
Inverted Index
Inverted Index
Inverted Index
In-memory buffer
Segment
Inverted Index
flush
35.
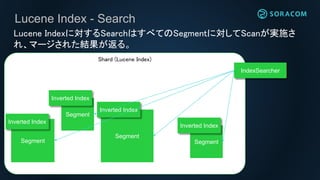
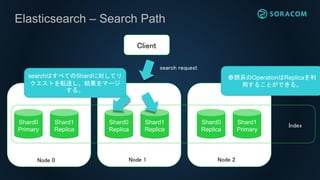
Lucene Index -Search
Shard (Lucene Index)
Lucene Indexに対するSearchはすべてのSegmentに対してScanが実施さ
れ、マージされた結果が返る。
Segment
Segment
Segment
Inverted Index
Inverted Index
Inverted Index
Segment
Inverted Index
IndexSearcher
36.
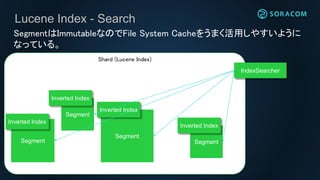
Lucene Index -Search
Shard (Lucene Index)
SegmentはImmutableなのでFile System Cacheをうまく活用しやすいように
なっている。
Segment
Segment
Segment
Inverted Index
Inverted Index
Inverted Index
Segment
Inverted Index
IndexSearcher
37.
Lucene Index -Delete
Shard (Lucene Index)
DeleteはレコードにDeleteフラグを立てるだけ。Search時にフィルタされる。
なのでSearchのコストが高くなる。
Segment
Segment
Segment
Inverted Index
Inverted Index
Inverted Index
Segment
Inverted Index
Deleted : true
38.
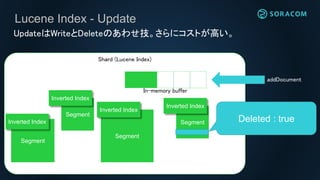
Lucene Index -Update
Shard (Lucene Index)
UpdateはWriteとDeleteのあわせ技。さらにコストが高い。
Segment
Segment
Segment
Inverted Index
Inverted Index
Inverted Index
Segment
Inverted Index
Deleted : true
In-memory buffer
addDocument
39.
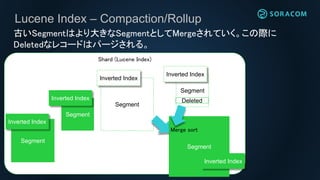
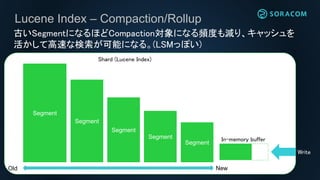
Lucene Index –Compaction/Rollup
Shard (Lucene Index)
古いSegmentはより大きなSegmentとしてMergeされていく。この際に
Deletedなレコードはパージされる。
Segment
Segment
Segment
Inverted Index
Inverted Index
Inverted Index
Segment
Inverted Index
Deleted
Segment
Inverted Index
Merge sort


























































![[AWS EXpert Online for JAWS-UG 18] 見せてやるよ、Step Functions の本気ってやつをな](https://cdn.slidesharecdn.com/ss_thumbnails/awsxon18howfarstepfunctionsgo-211124111849-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)








































