Download to read offline




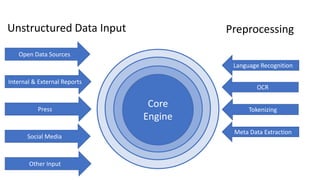
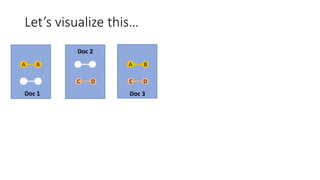
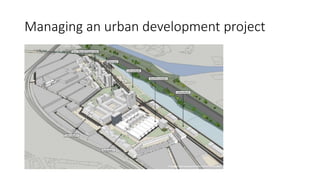


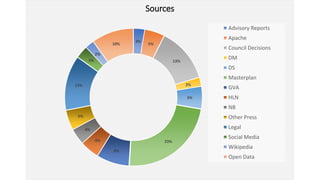

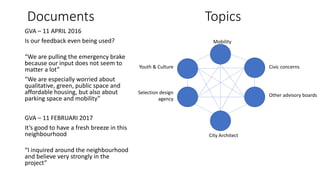
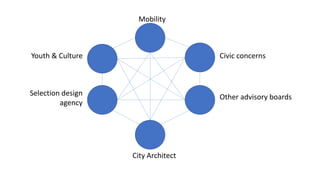

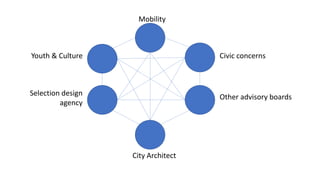

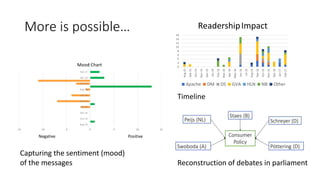


The document discusses the analysis of stakeholder interactions within an urban development project, specifically focusing on various concerns expressed by citizens regarding the Slachthuislaan development. It emphasizes the use of data aggregation methods like retrieval, search, and discovery to manage diverse stakeholder interests, which include regulatory authorities, private owners, and local communities. The analysis involves examining sentiments and topics from various sources, including press releases and citizen feedback, to inform project management decisions.















![[E government policy training] shanghai city presentation](https://cdn.slidesharecdn.com/ss_thumbnails/e-governmentpolicytrainingshanghaicitypresentation-160717080702-thumbnail.jpg?width=640&height=640&fit=bounds)


![[E government policy training] shiraz city presentation](https://cdn.slidesharecdn.com/ss_thumbnails/e-governmentpolicytrainingshirazcitypresentation-160717080841-thumbnail.jpg?width=640&height=640&fit=bounds)
































































![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DSC Europe 25] Stefan Brankovic - #ResumeIsDead. AI-Powered Interviews and C...](https://cdn.slidesharecdn.com/ss_thumbnails/qnmbsv0xq3uysdrq3sev-2-stefan-brankovic-job-bolt-260114111931-a065aa3d-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Nikola Vasiljevic - Player segmentation by combat playstyles ...](https://cdn.slidesharecdn.com/ss_thumbnails/mnvbf0yvrwaqsipzrrv3-2-nikola-vasiljevic-player-segmentation-by-playstyles-in-action-shooter-games-260114111931-b4d766cd-thumbnail.jpg?width=640&height=640&fit=bounds)


