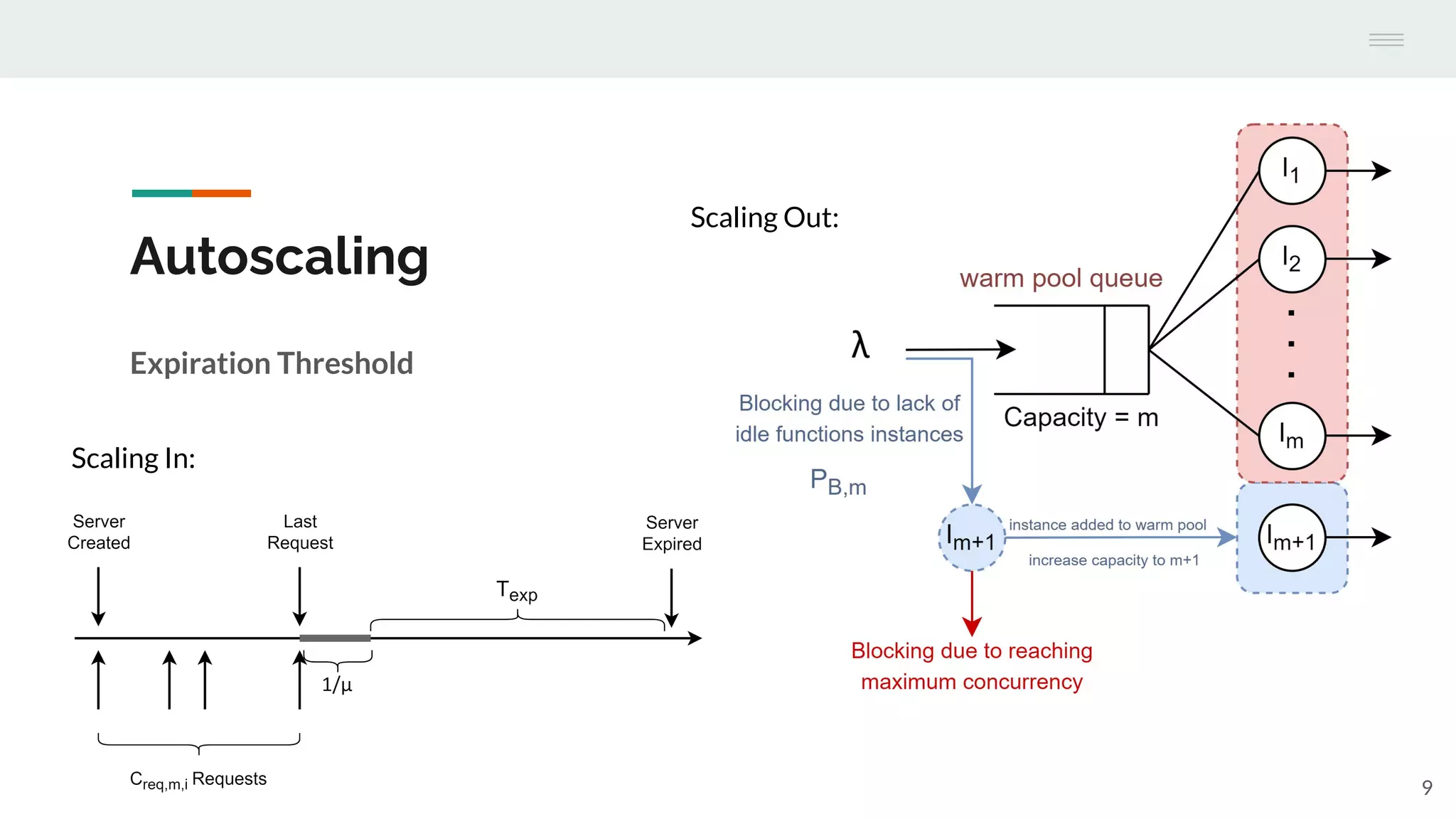
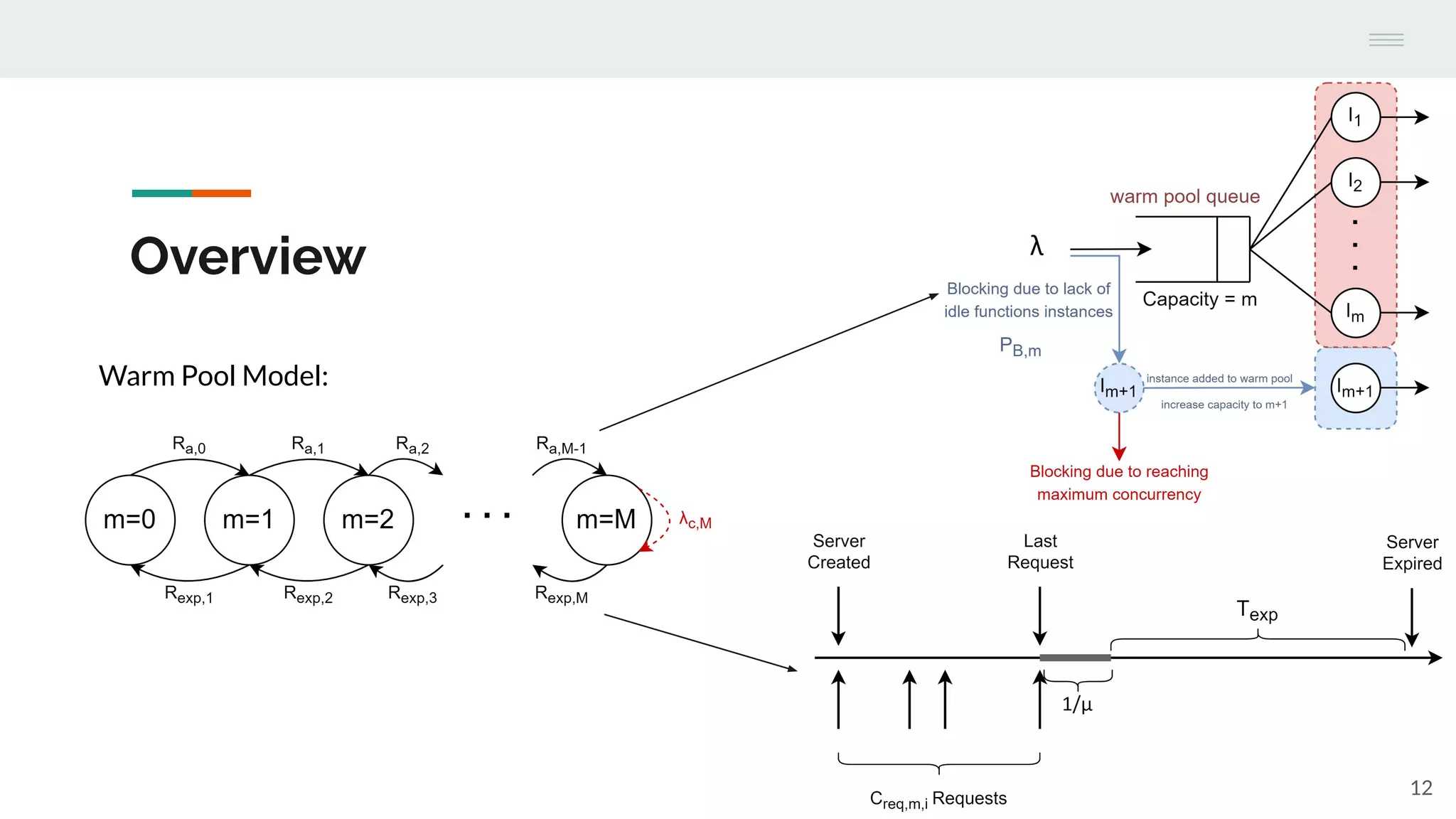
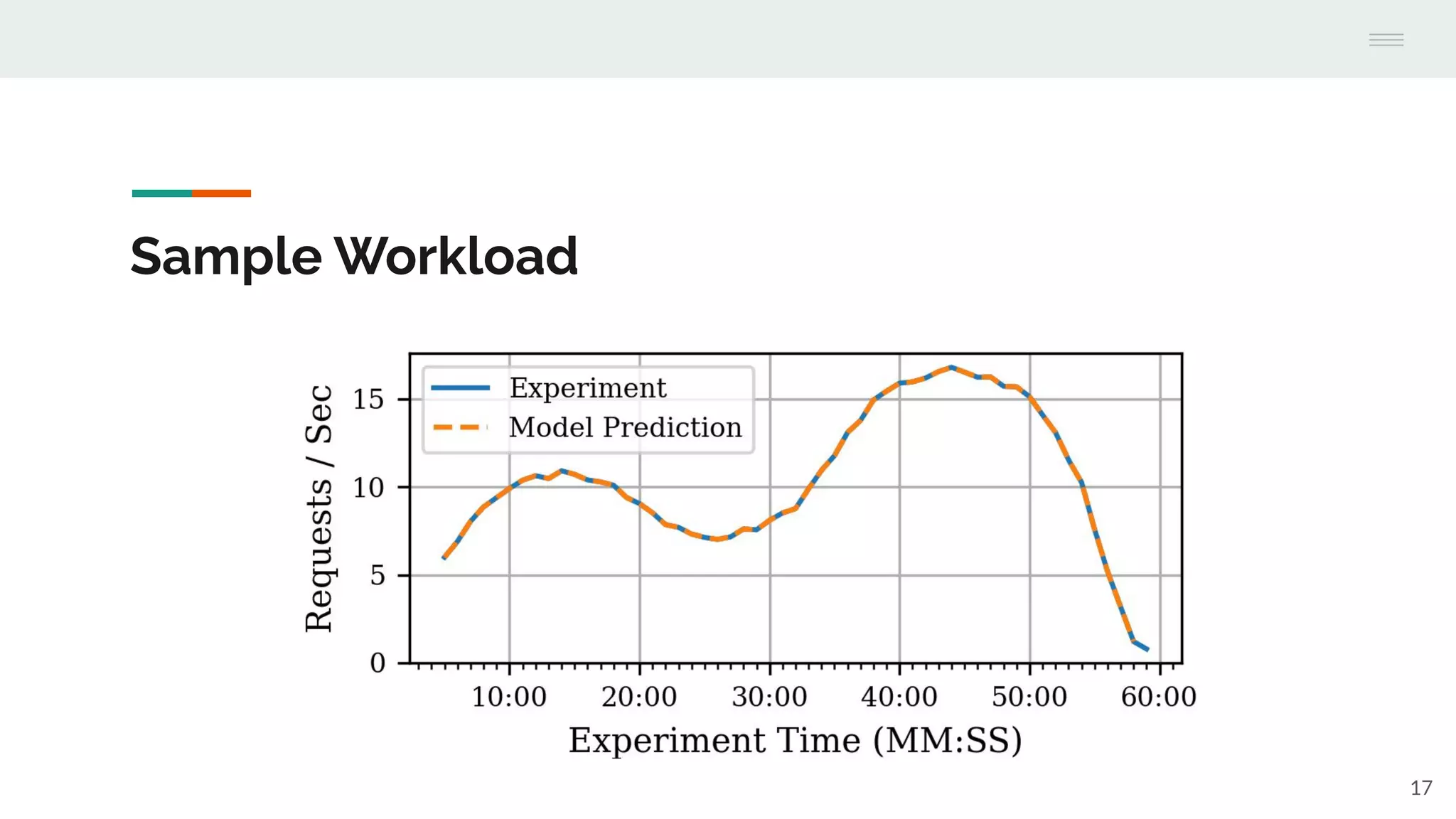
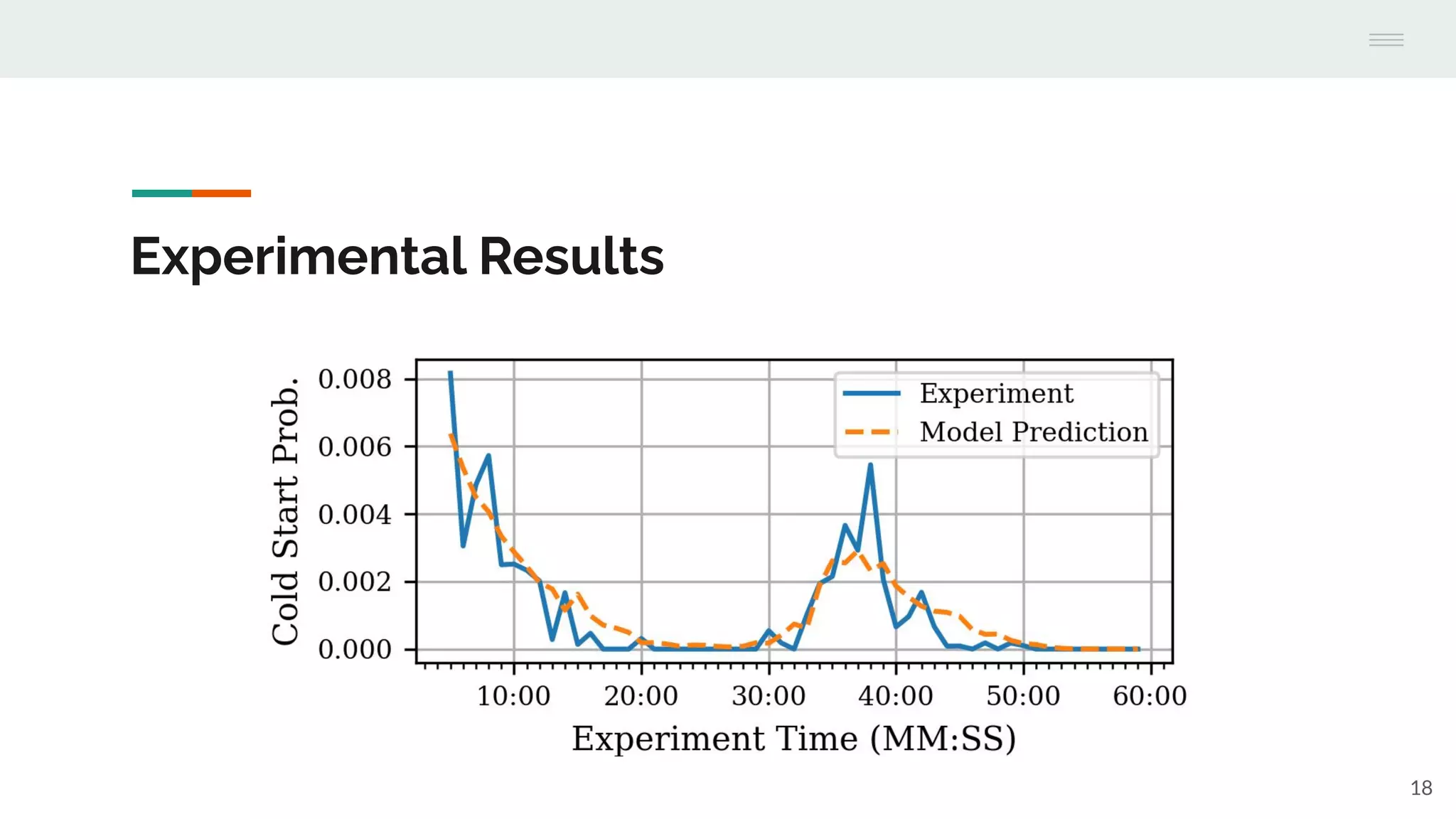
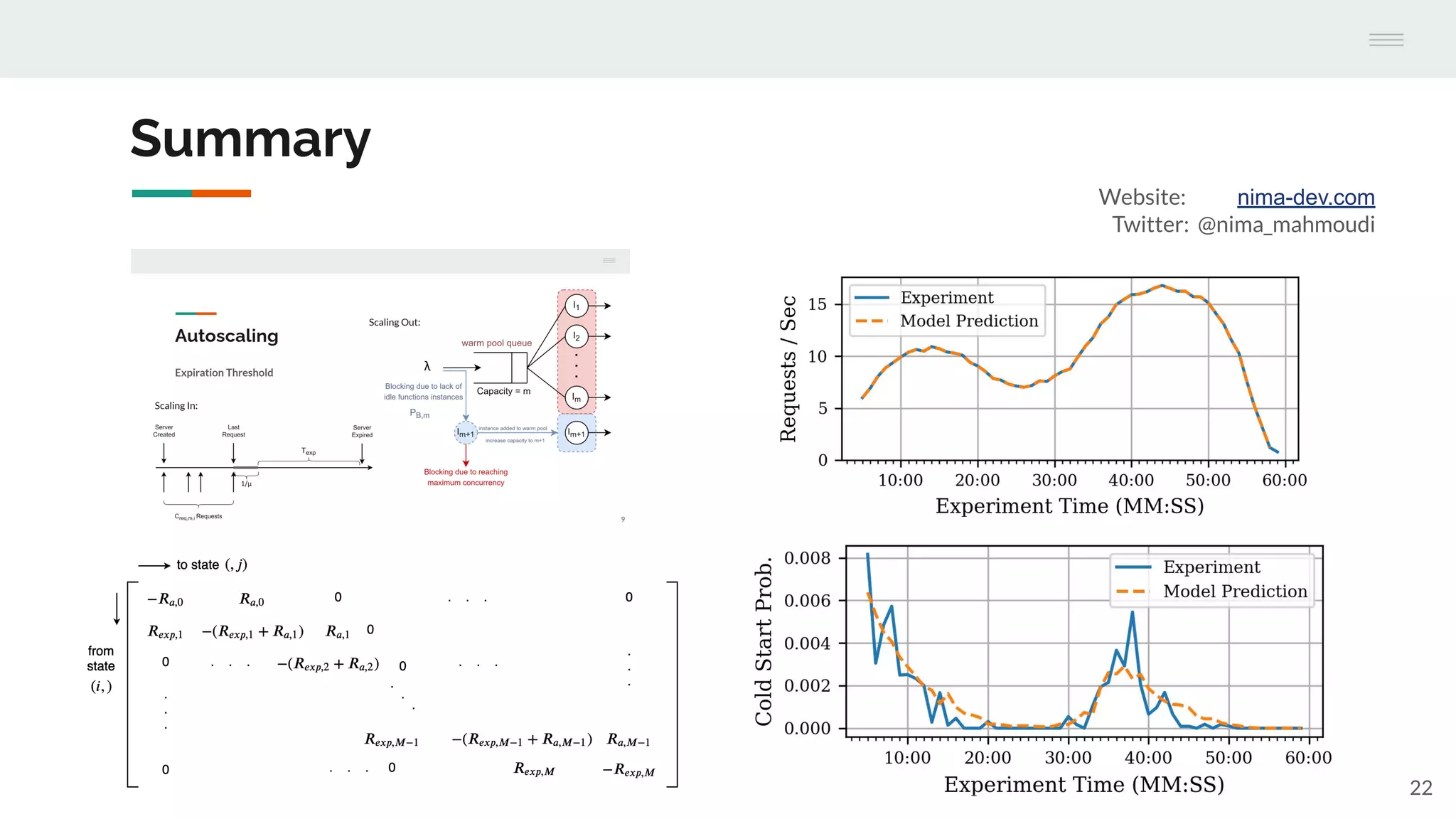
The document discusses the temporal performance modeling of serverless computing platforms presented at the 6th International Workshop on Serverless Computing in 2020. It emphasizes the need for accurate performance models to ensure quality of service, optimize infrastructure costs, and aid both providers and developers in managing performance. The findings indicate that analytical models can effectively predict key performance metrics and can be beneficial for instance management and application optimization.