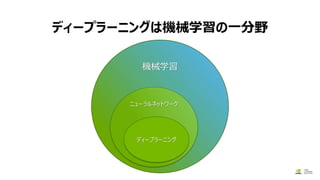
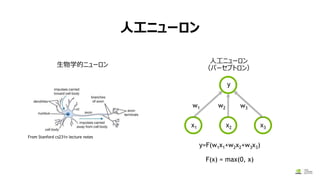
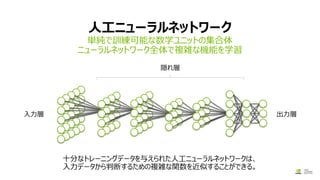
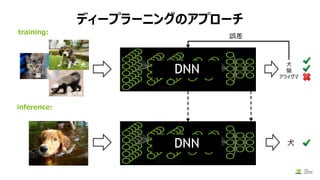
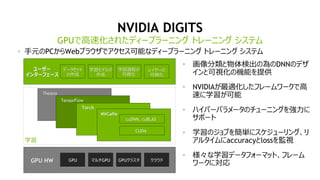
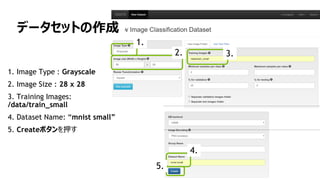
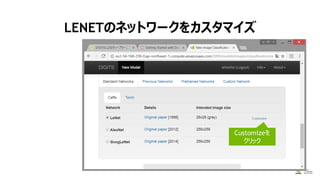
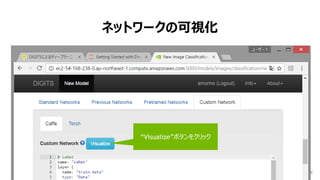
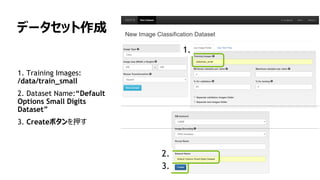
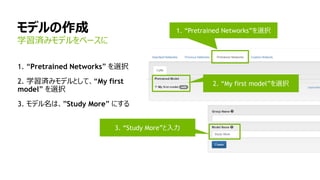
モデルの作成
1. “mnist small”データセットを選択
2. Training Epochs を”8”にする
3. モデルは、”LeNet” を選択
4. モデル名は、”The right model for
the data” を入力
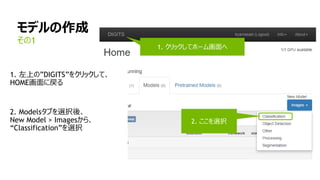
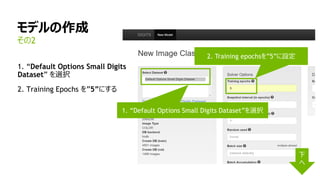
1. “mnist small”データセットを選択
2. Training epochsを”8”に設定
3. “LeNet”を選択
4. “The right model
for the data”を入力
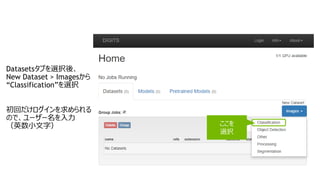
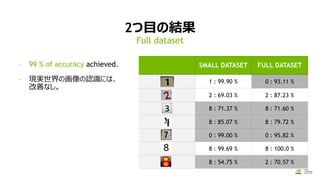
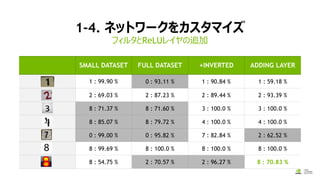
FULL DATASET
10倍大きなデータセット
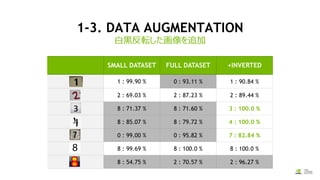
— データセット
—“mnist small”をクローン(Cloneボタンを押す)
— Training Images : /data/train_full
— Dataset Name : MNIST full
— モデル
— “The right model for the data”をクローン(Cloneボタンを押す)
— データを”MNIST full”に変更
— モデル名に“MNIST full”を設定し、”Create”ボタンを押す
9/26/2017



































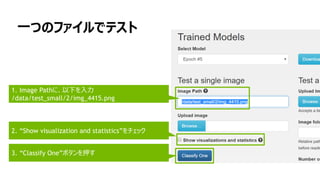
![画像リストファイルの取得
• jupyterに戻る
• In [ ] を実行(Ctrl + Enter)
• 実行後に出力されるan_image.listを
右クリック
• 「テキストファイル」 として保存](https://image.slidesharecdn.com/digits-170925180659/85/DIGITS-51-320.jpg)


























![[DL輪読会]Deep Reinforcement Learning that Matters](https://cdn.slidesharecdn.com/ss_thumbnails/deeprlthatmatters-171212050658-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generat...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks170303-170308031242-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DLHacks 実装]Network Dissection: Quantifying Interpretability of Deep Visual R...](https://cdn.slidesharecdn.com/ss_thumbnails/171030netdissectimple1-171030120240-thumbnail.jpg?width=640&height=640&fit=bounds)



![[IBIS2017 講演] ディープラーニングによる画像変換](https://cdn.slidesharecdn.com/ss_thumbnails/ibis2017iizuka-171120134119-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]High-Fidelity Image Generation with Fewer Labels](https://cdn.slidesharecdn.com/ss_thumbnails/190315dlseminargan-190315004124-thumbnail.jpg?width=640&height=640&fit=bounds)

































