Presentation Bisnis Teknologi Modern Biru & Ungu_20240429_074226_0000.pptx
Tugas komputasi rancang obat
1. Tugas Komputasi rancang Obat
Nama : Moch Kholidin
NIM:11/317018/PA/14136
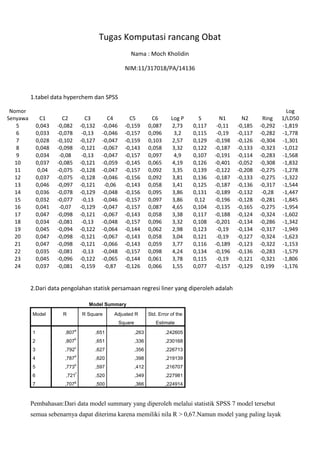
1.tabel data hyperchem dan SPSS
Nomor
Senyawa C1 C2 C3 C4 C5 C6 Log P S N1 N2 Ring
Log
1/LD50
5 0,043 -0,082 -0,132 -0,046 -0,159 0,087 2,73 0,117 -0,11 -0,185 -0,292 -1,819
6 0,033 -0,078 -0,13 -0,046 -0,157 0,096 3,2 0,115 -0,19 -0,117 -0,282 -1,778
7 0,028 -0,102 -0,127 -0,047 -0,159 0,103 2,57 0,129 -0,198 -0,126 -0,304 -1,301
8 0,048 -0,098 -0,121 -0,067 -0,143 0,058 3,32 0,122 -0,187 -0,133 -0,323 -1,012
9 0,034 -0,08 -0,13 -0,047 -0,157 0,097 4,9 0,107 -0,191 -0,114 -0,283 -1,568
10 0,037 -0,085 -0,121 -0,059 -0,145 0,065 4,19 0,126 -0,401 -0,052 -0,308 -1,832
11 0,04 -0,075 -0,128 -0,047 -0,157 0,092 3,35 0,139 -0,122 -0,208 -0,275 -1,278
12 0,037 -0,075 -0,128 -0,046 -0,156 0,092 3,81 0,136 -0,187 -0,133 -0,275 -1,322
13 0,046 -0,097 -0,121 -0,06 -0,143 0,058 3,41 0,125 -0,187 -0,136 -0,317 -1,544
14 0,036 -0,078 -0,129 -0,048 -0,156 0,095 3,86 0,131 -0,189 -0,132 -0,28 -1,447
15 0,032 -0,077 -0,13 -0,046 -0,157 0,097 3,86 0,12 -0,196 -0,128 -0,281 -1,845
16 0,041 -0,07 -0,129 -0,047 -0,157 0,087 4,65 0,104 -0,135 -0,165 -0,275 -1,954
17 0,047 -0,098 -0,121 -0,067 -0,143 0,058 3,38 0,117 -0,188 -0,124 -0,324 -1,602
18 0,034 -0,081 -0,13 -0,048 -0,157 0,096 3,32 0,108 -0,201 -0,134 -0,286 -1,342
19 0,045 -0,094 -0,122 -0,064 -0,144 0,062 2,98 0,123 -0,19 -0,134 -0,317 -1,949
20 0,047 -0,098 -0,121 -0,067 -0,143 0,058 3,04 0,121 -0,19 -0,127 -0,324 -1,623
21 0,047 -0,098 -0,121 -0,066 -0,143 0,059 3,77 0,116 -0,189 -0,123 -0,322 -1,153
22 0,035 -0,081 -0,13 -0,048 -0,157 0,098 4,24 0,134 -0,196 -0,136 -0,283 -1,579
23 0,045 -0,096 -0,122 -0,065 -0,144 0,061 3,78 0,115 -0,19 -0,121 -0,321 -1,806
24 0,037 -0,081 -0,159 -0,87 -0,126 0,066 1,55 0,077 -0,157 -0,129 0,199 -1,176
2.Dari data pengolahan statisk persamaan regresi liner yang diperoleh adalah
Model Summary
Model R R Square Adjusted R
Square
Std. Error of the
Estimate
1 ,807
a
,651 ,263 ,242605
2 ,807
b
,651 ,336 ,230168
3 ,792
c
,627 ,356 ,226713
4 ,787
d
,620 ,398 ,219139
5 ,773
e
,597 ,412 ,216707
6 ,721
f
,520 ,349 ,227981
7 ,707
g
,500 ,366 ,224914
Pembahasan:Dari data model summary yang diperoleh melalui statistik SPSS 7 model tersebut
semua sebenarnya dapat diterima karena memiliki nila R > 0,67.Namun model yang paling layak
2. dapat digunakan harus didukung dengan nilai signifikansi ANOVA.nilai signifikansi ANOVA yang
diterima memiliki nilai Ho<0,005
ANOVA
a
Model Sum of Squares df Mean Square F Sig.
1
Regression ,987 10 ,099 1,677 ,225
b
Residual ,530 9 ,059
Total 1,517 19
2
Regression ,987 9 ,110 2,070 ,136
c
Residual ,530 10 ,053
Total 1,517 19
3
Regression ,951 8 ,119 2,313 ,099
d
Residual ,565 11 ,051
Total 1,517 19
4
Regression ,940 7 ,134 2,797 ,057
e
Residual ,576 12 ,048
Total 1,517 19
5
Regression ,906 6 ,151 3,215 ,037
f
Residual ,611 13 ,047
Total 1,517 19
6
Regression ,789 5 ,158 3,036 ,046
g
Residual ,728 14 ,052
Total 1,517 19
7
Regression ,758 4 ,189 3,745 ,026
h
Residual ,759 15 ,051
Total 1,517 19
Pembahasan: Dari data ANOVA yang diperolah secara statistik signifikansi (Ho) semuanya tidak
memnuhi nilai <0,005 sehingga tidak dapat diteriuma semua.Akan tetapi tidak serta merta
salah,hanya saja dalam keperluan anlisis dipilih yang paling kecil yang dianggap memiliki
probabilitas kesalahan paling kecil dibanding yang lain.Dari 7 model diatas maka nilai signifikansi
yang paling layak digunakan adalah model nomor 7
Coefficients
a
Model Unstandardized Coefficients Standardized
Coefficients
t Sig.
B Std. Error Beta
1
(Constant) 8,218 10,388 ,791 ,449
C1 183,632 74,163 3,947 2,476 ,035
C2 -12,157 14,497 -,436 -,839 ,423
C3 135,742 83,192 4,069 1,632 ,137
C4 -6,049 4,847 -3,910 -1,248 ,244
4. C4 -7,087 2,373 -4,581 -2,986 ,010
C6 56,092 17,522 3,536 3,201 ,006
7
(Constant) 9,648 3,747 2,575 ,021
C1 68,696 24,833 1,477 2,766 ,014
C3 150,964 44,327 4,525 3,406 ,004
C4 -7,820 2,146 -5,055 -3,644 ,002
C6 58,111 17,093 3,663 3,400 ,004
Pembahasan:Dari data koefisien yang diperoleh maka data yang diterima adalah yang memiliki
signifikansi <0,005.maka dari 7 model diatas yang paling representatif adalah model nomor 7.Hal
ini mendukung bersesuaian dengan ANOVA diatasnya serta dapat disimpulkan model yang
digunakan adalah model 7.
Sehingga model QSAR terbaik yang diperoleh adalah
-LogIC50=9,648 +(68,696*qC1) + ( 150,964*qC3) - ( 7,820*qC4)
+(58,111*q6)
Nilai n=20 , nilai F=3,745 dan nilai t=(2,575),(2,766),(3,406),(-3,644),(3,400) dan standar deviasi
S=0,224914
Uraian secara kimia
Analisis QSAR dengan metode semi empiric AM1 menghasilkan 7 model QSAR.Pemilihan model
persamaan QSAR terbaik memperhitungkan parameter-parameter statistik seperti harga
r2
(koefisien korelasi),SD(standar deviasi),Fhit/Ftab PRESS(Predicted Residual Sum of Square).nilai
signifikansi ANOVA dan signifikansi koefisien.Berdasarkan pertimbangan tersebut model ada 1
model layak yang diusulkan sebagai model terbaik QSAR yaitu model nomor 7.Selain itu berkaitan
dengan nilai –log IC50,jika senyawa baru lebih besar nilai –log IC50 dibanding senyawa lama maka
artinya senyawa tersebut memiliki aktivitas inhibisi yang lebih baik dari pada senyawa
sebelumnya.