Downloaded 80 times










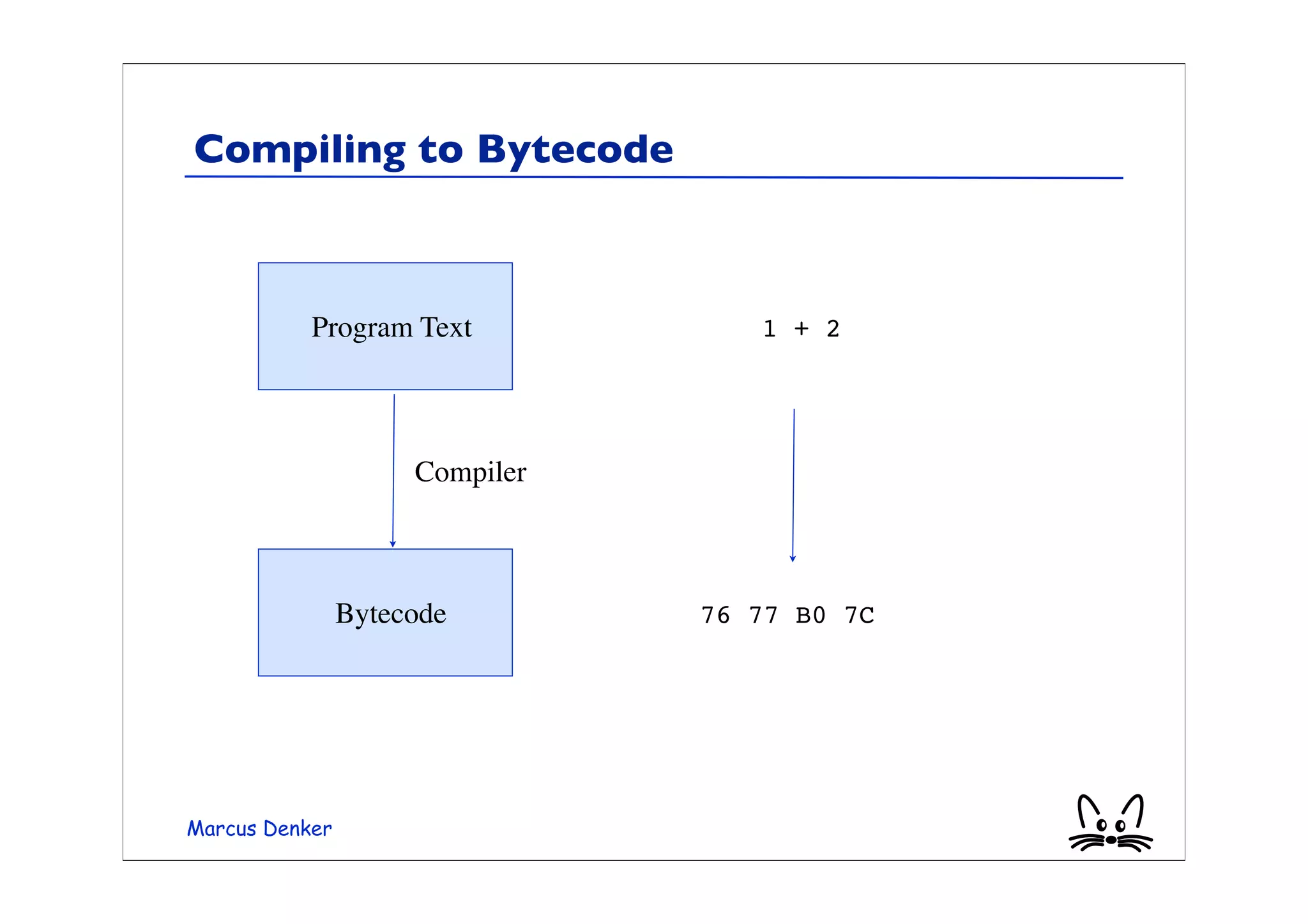

![Example: Java Bytecode
• From class Rectangle
public int perimeter()
0: iconst_2
1: aload_0 “push this”
2: getfield#2 “value of sides”
5: iconst_0
6: iaload
7: aload_0 2*(sides[0]+sides[1])
8: getfield#2
11: iconst_1
12: iaload
13: iadd
14: imul
15: ireturn
Marcus Denker](https://image.slidesharecdn.com/dcc01jitandco-090827194134-phpapp02/75/VMs-Interpreters-JIT-13-2048.jpg)









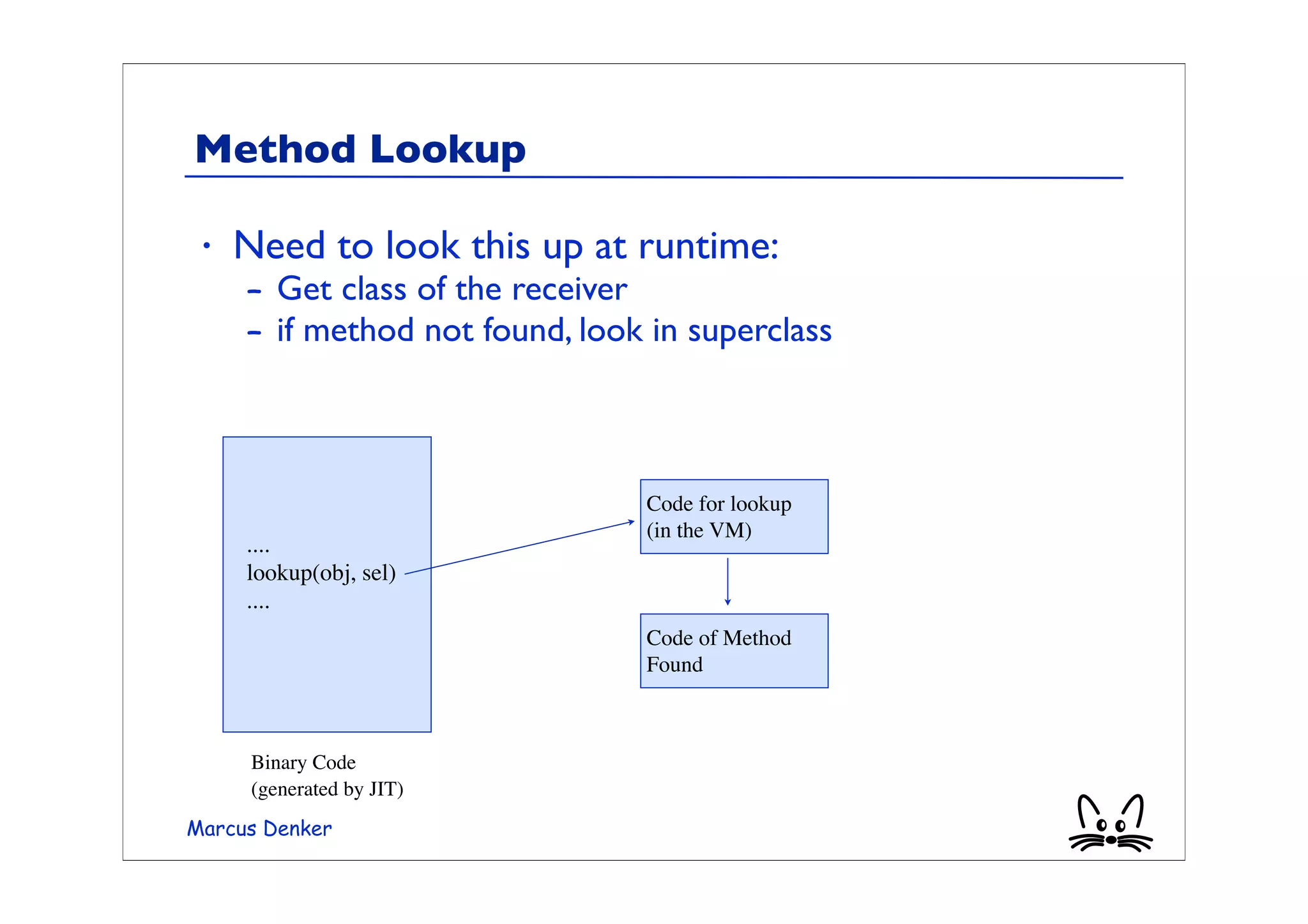
![Example Method Lookup
• A simple example:
array := #(0 1 2 2.5).
array collect: [:each | each + 1]
• The method “+” executed depends on the receiving
object
Marcus Denker](https://image.slidesharecdn.com/dcc01jitandco-090827194134-phpapp02/75/VMs-Interpreters-JIT-24-2048.jpg)


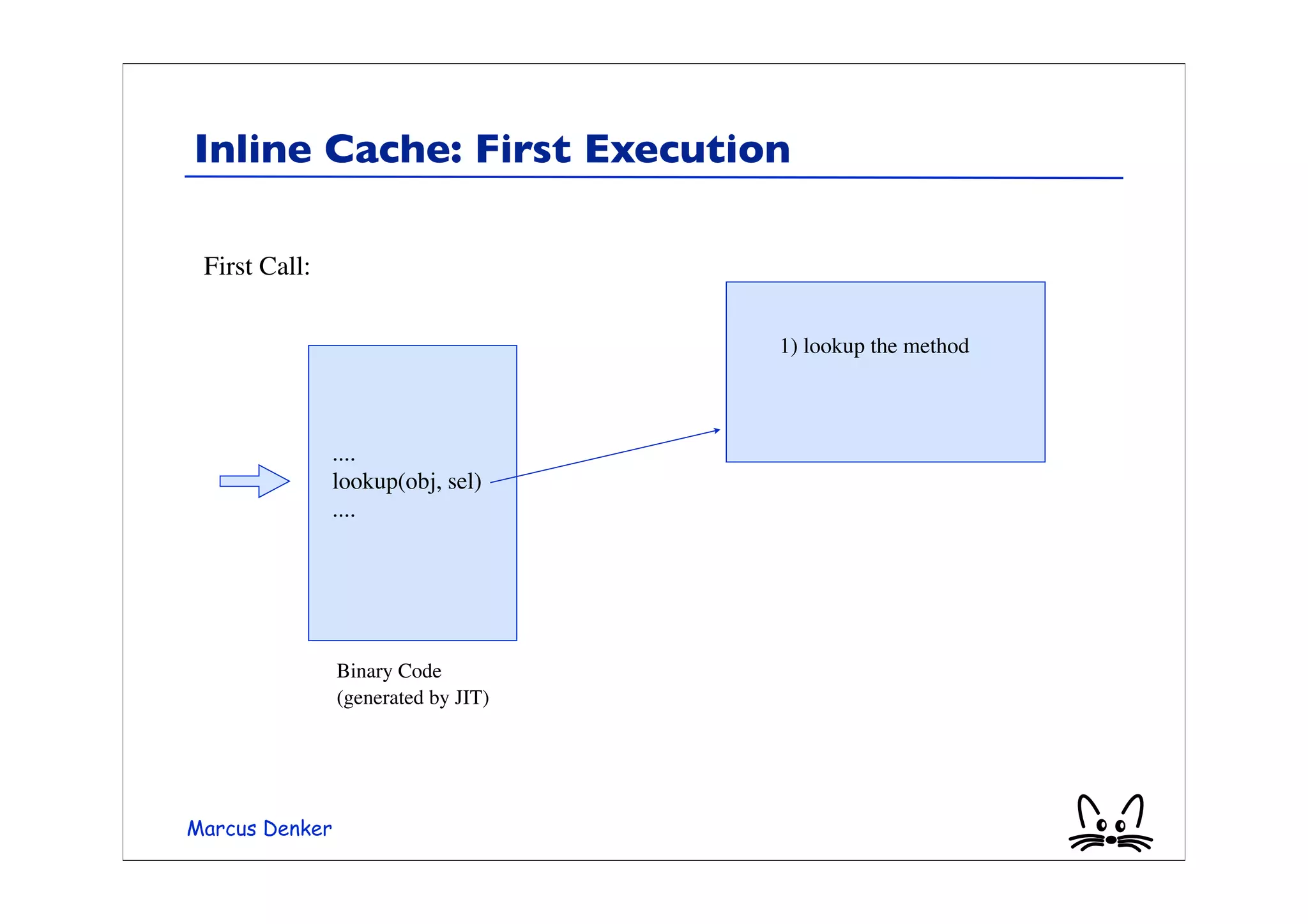

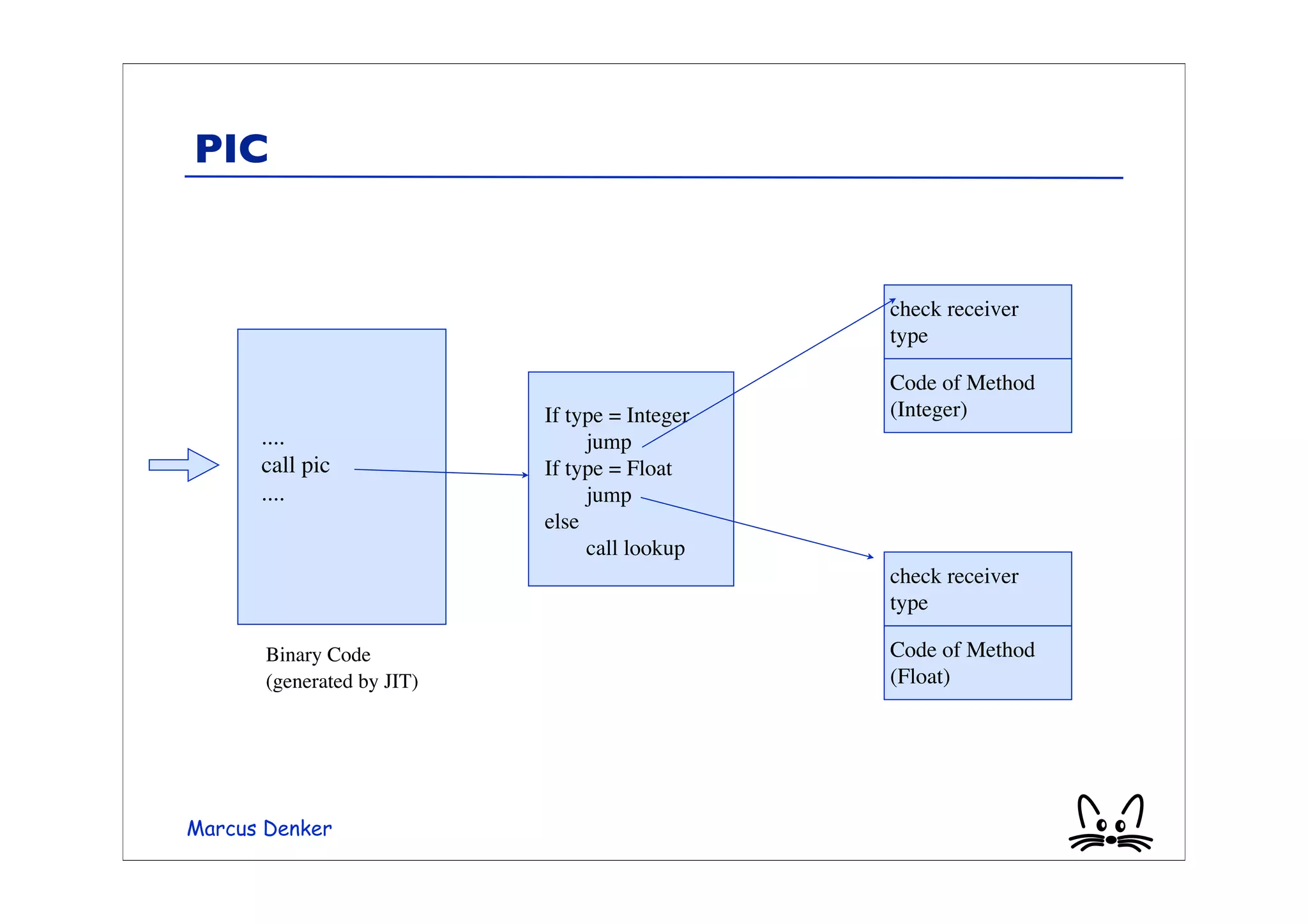
![Example Polymorphic Send
• This example is Polymorphic.
array := #(1 1.5 2 2.5 3 3.5).
array collect: [:each | each + 1]
• Two classes: Integer and Float
• Inline cache will fail at every send
• It will be slower than doing just a lookup!
Marcus Denker](https://image.slidesharecdn.com/dcc01jitandco-090827194134-phpapp02/75/VMs-Interpreters-JIT-35-2048.jpg)







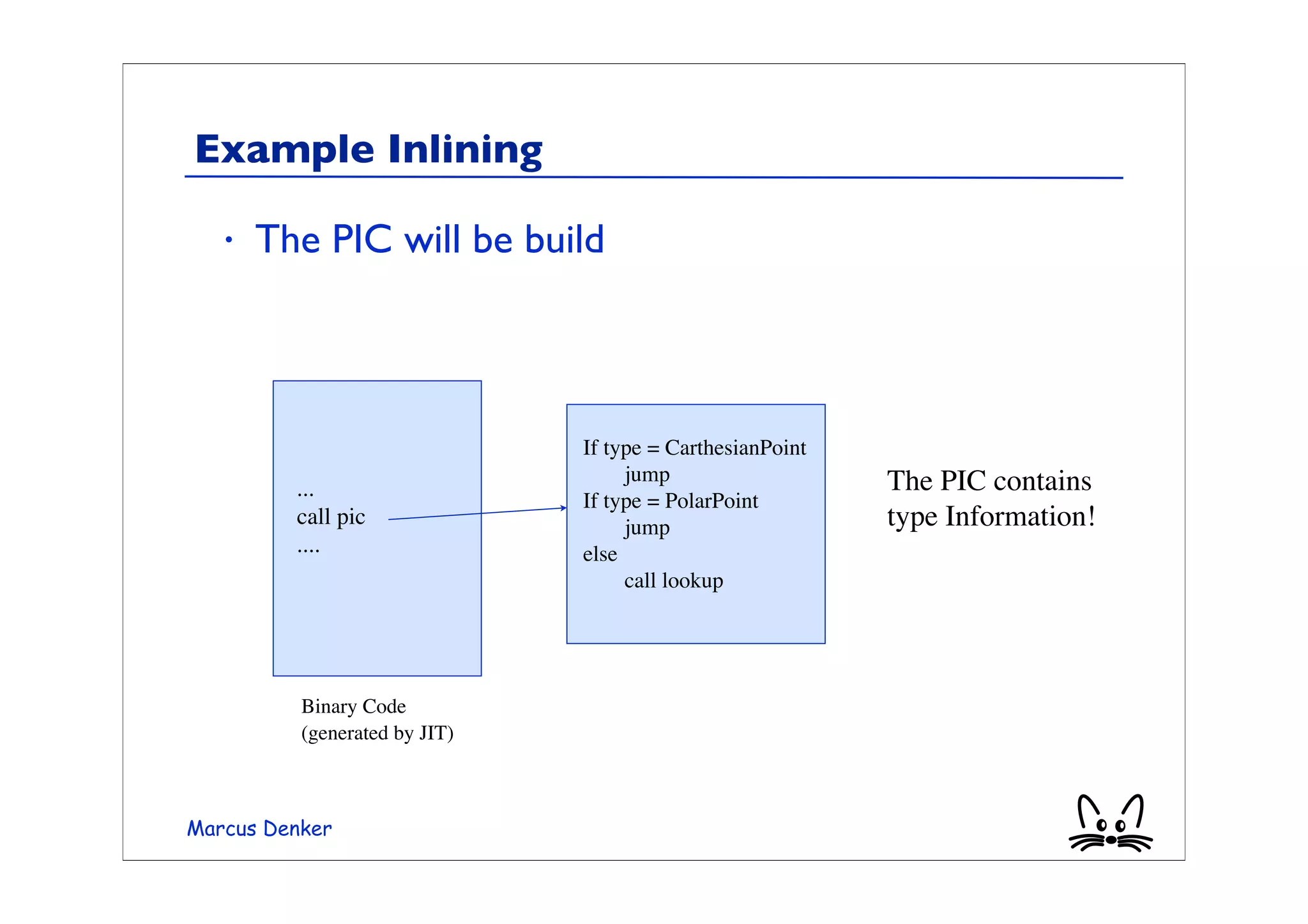




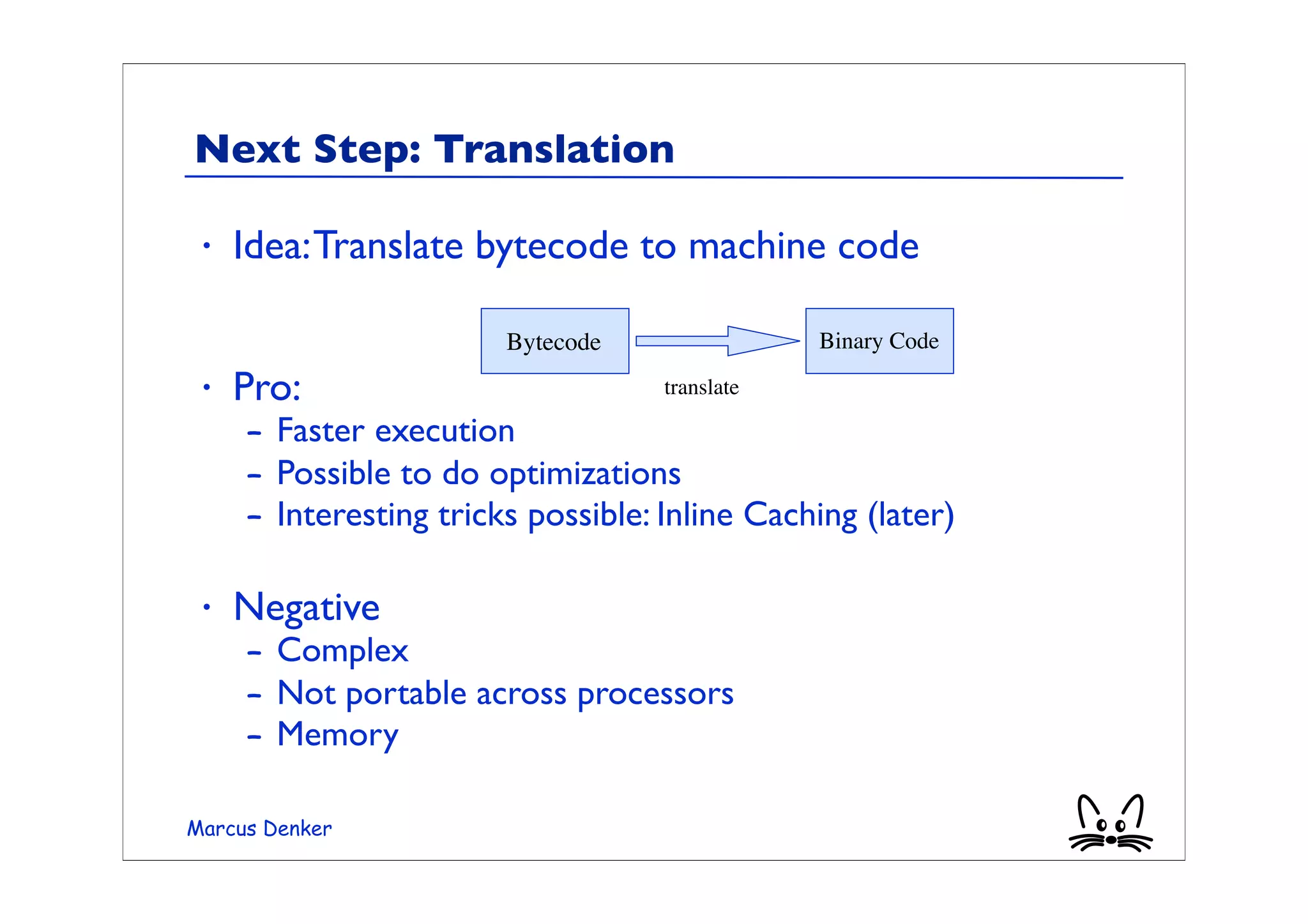
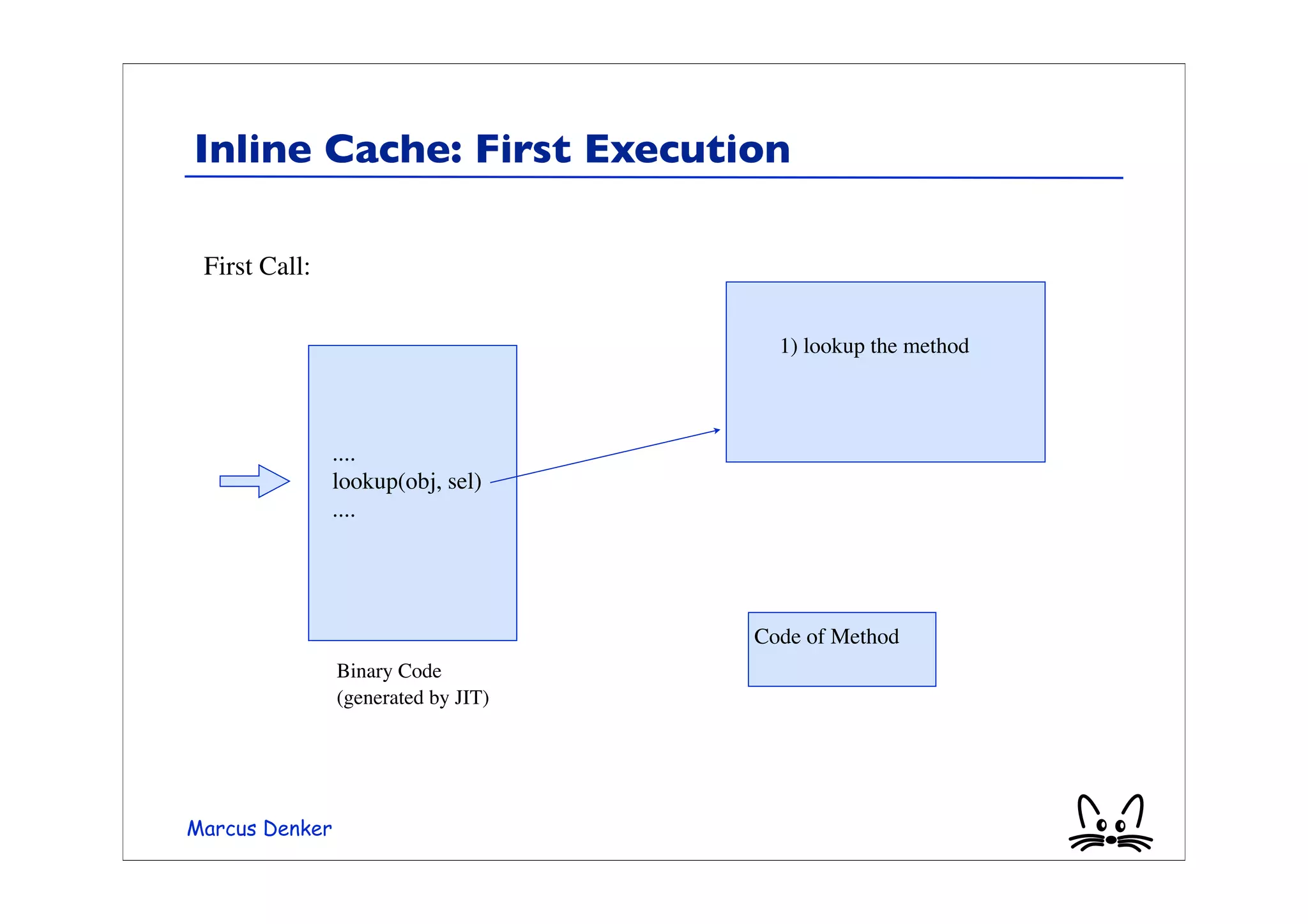
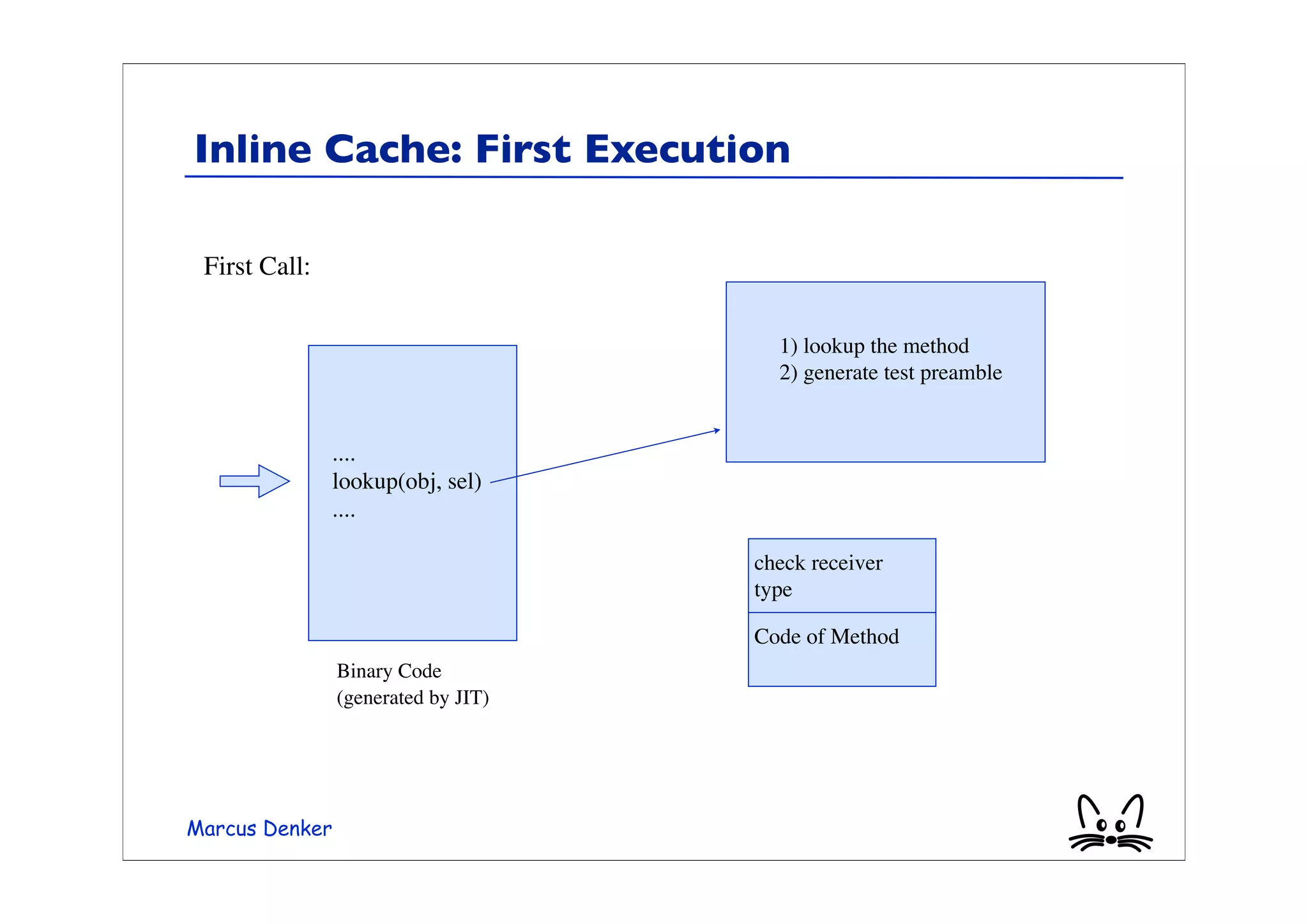
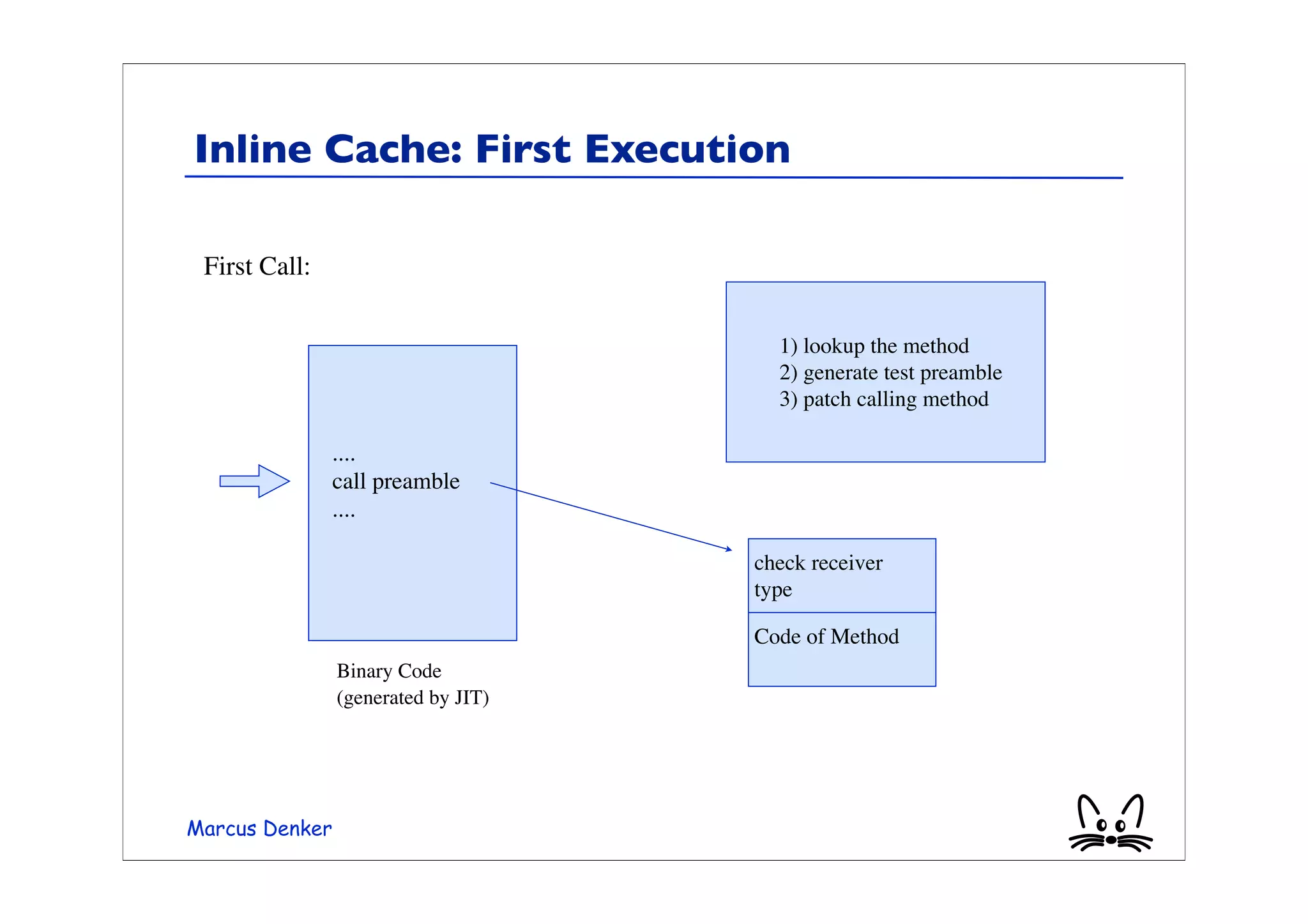
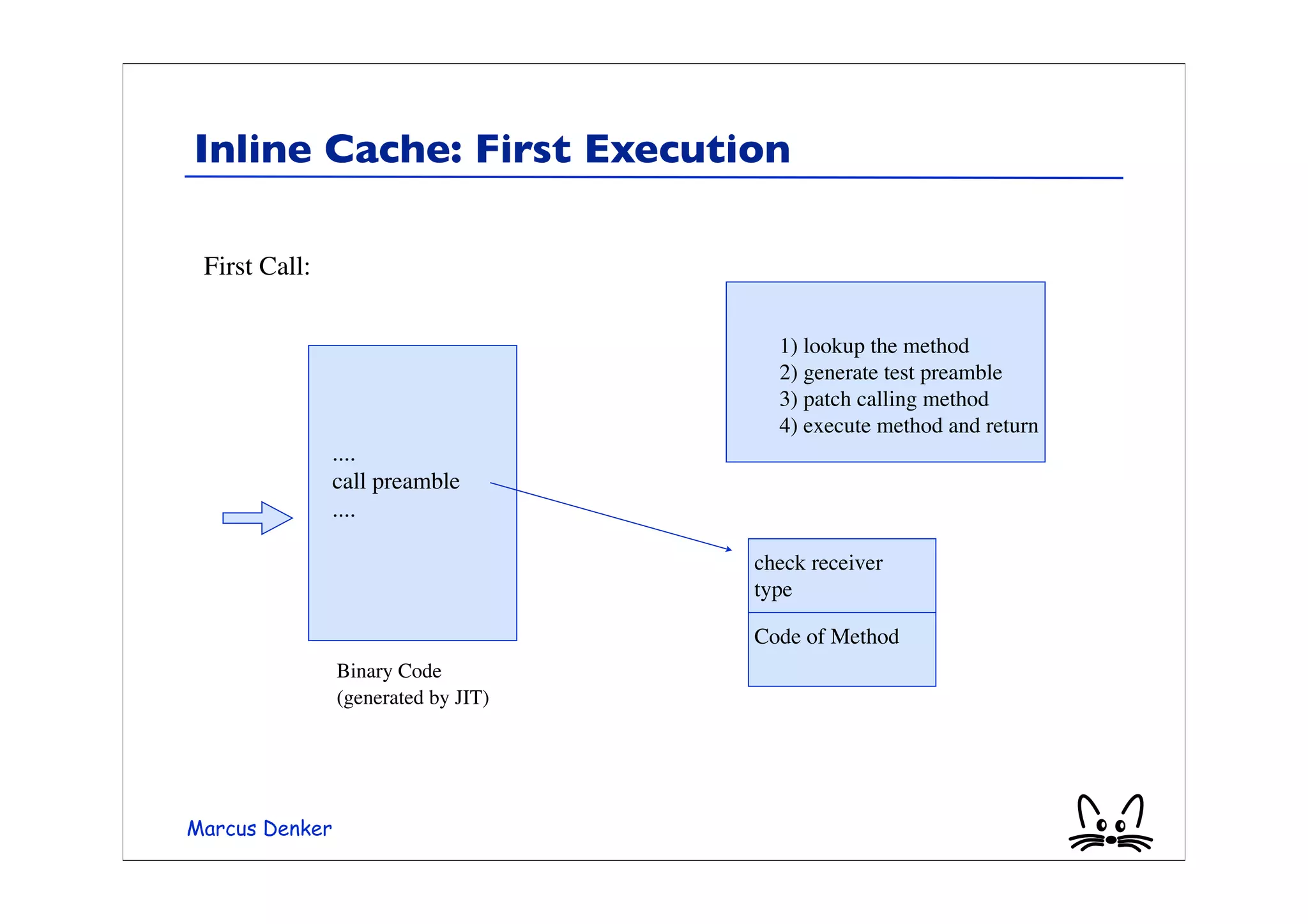
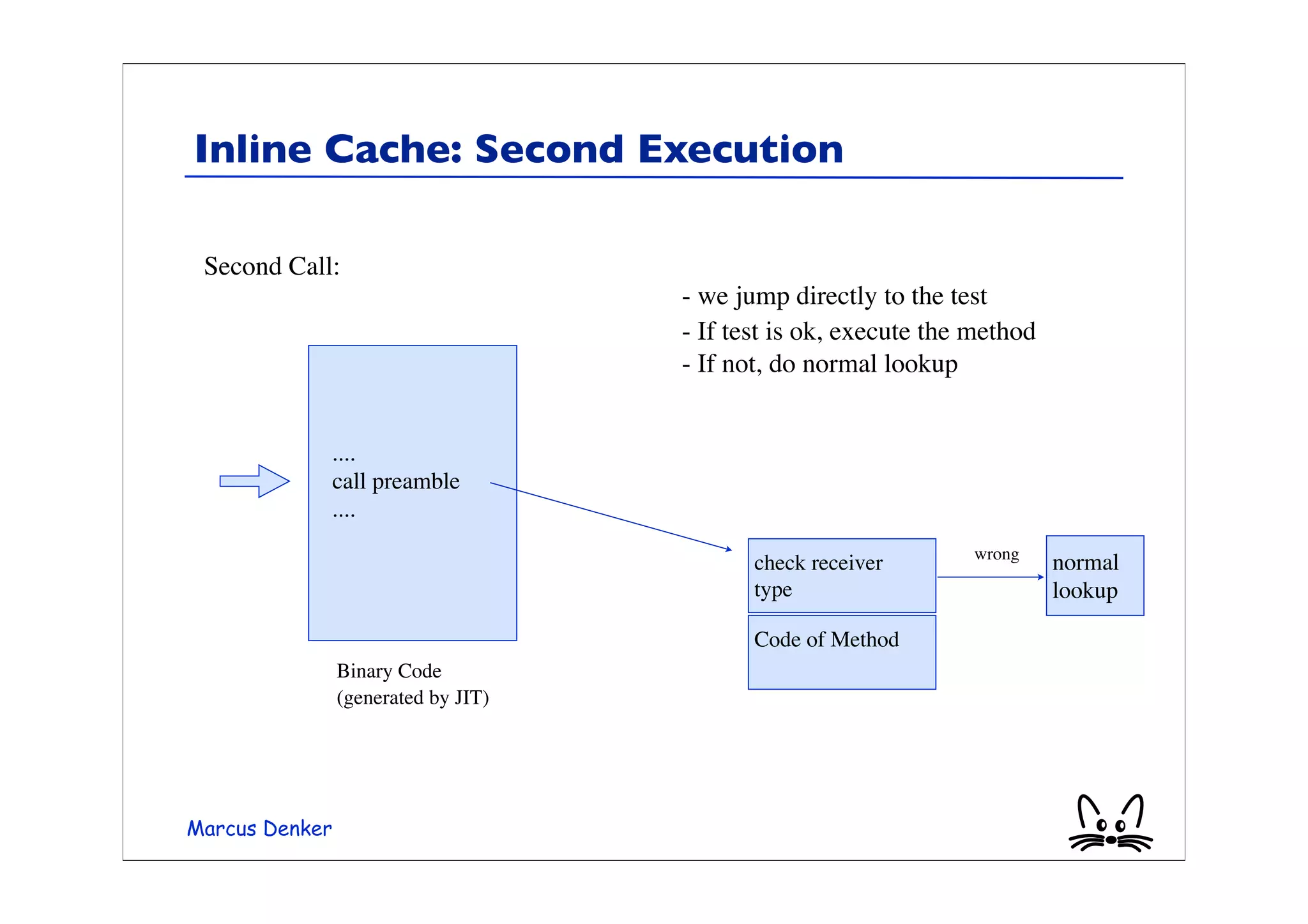
This document provides an overview of virtual machines, bytecode, and techniques for efficiently executing bytecode. It discusses: 1) How virtual machines simulate processors through bytecode instruction sets and memory management. 2) Bytecode formats and examples of bytecode for operations. 3) Different techniques for executing bytecode like interpretation, threaded code, and just-in-time compilation. 4) Optimizations for method lookup like inline caching and polymorphic inline caching to speed up dynamic method dispatch. 5) Advanced dynamic optimization techniques used in virtual machines like HotSpot that recompile and optimize hot code sections at runtime.







![[PH-Neutral 0x7db] Exploit Next Generation®](https://cdn.slidesharecdn.com/ss_thumbnails/ph-neutralnbrito-exploitnextgeneration-110612150913-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)














































































