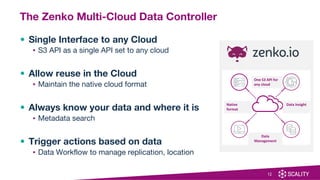
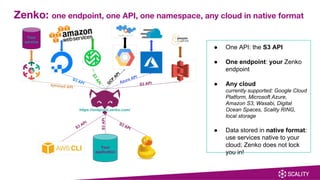
The document introduces Zenko, a multi-cloud data controller that simplifies data management across various cloud platforms using a single API. It highlights capabilities like metadata search, policy-based data management, and a user-friendly management UI, making it ideal for scenarios such as content distribution, compute bursting, and long-term archival. Zenko supports multiple cloud environments including AWS, Google Cloud, and Microsoft Azure, and aims to enhance efficiency and cost-effectiveness for businesses utilizing multi-cloud strategies.

































![Zenko: a stack of microservices
$ docker stack services ls
ID NAME MODE REPLICAS IMAGE PORTS
1j8jb41llhtm zenko-prod_s3-data replicated 1/1 zenko/cloudserver:pensieve-3 *:30010->9991/tcp
3y7vayna97bt zenko-prod_s3-front replicated 1/1 zenko/cloudserver:pensieve-3 *:30009->8000/tcp
957xksl0cbge zenko-prod_mongodb-init replicated 0/1 mongo:3.6.3-jessie
cn0v7cf2jxkb zenko-prod_queue replicated 1/1 wurstmeister/kafka:1.0.0 *:30008->9092/tcp
jjx9oabeugx1 zenko-prod_mongodb replicated 1/1 mongo:3.6.3-jessie *:30007->27017/tcp
o530bkuognu5 zenko-prod_lb global 1/1 zenko/loadbalancer:latest *:80->80/tcp
r69lgbue0o3o zenko-prod_backbeat-api replicated 1/1 zenko/backbeat:pensieve-4
ut0ssvmi10tx zenko-prod_backbeat-consumer replicated 1/1 zenko/backbeat:pensieve-4
vj2fr90qviho zenko-prod_cache replicated 1/1 redis:alpine *:30011->6379/tcp
vqmkxu7yo859 zenko-prod_quorum replicated 1/1 zookeeper:3.4.11 *:30006->2181/tcp
y7tt98x7jdl9 zenko-prod_backbeat-producer replicated 1/1 zenko/backbeat:pensieve-4
[...]
Zenko: Multi-Cloud Data Controller
Cloudserver Backbeat Utapi
S3 API
Multi Cloud API translation
Event-driven data manager
Replication engine
Usage Stats
Custom node.js Kafka- & Zookeeper- -based Redis-based
Bare-Metal Kubespray: custom deployment of Kubespray](https://image.slidesharecdn.com/dockermeetuptokyo1-180515112948/85/Docker-Meetup-Tokyo-23-Zenko-Open-Source-Multi-Cloud-Data-Controller-Laure-Vergeron-37-320.jpg)


![● When versioning is enabled on a bucket:
● CREATE NEW VERSIONS:
○ Put Object, Complete Multipart Upload and Object Copy (to a versioning-enabled bucket) will
return a version id in the ‘x-amz-version-id’ response header.
○ No special syntax necessary.
● When versioning is enabled or suspended:
● TARGETING SPECIFIC VERSIONS:
○ Include the version id in the request query for GET/HEAD Object or PUT/GET Object ACL
■ Example: `GET [bucket]/[object]?versionId=[versionId]`
○ For Object Copy or Upload Copy Part, to copy a specific version from a version-enabled
bucket, add the version id to the ‘x-amz-copy-source’ header:
■ Example value: `[sourcebucket]/[sourceobject]?versionId=[versionId]`
○ Omitting a specific version will get the result for the latest / current version.
Zenko S3 API: Bucket Versioning](https://image.slidesharecdn.com/dockermeetuptokyo1-180515112948/85/Docker-Meetup-Tokyo-23-Zenko-Open-Source-Multi-Cloud-Data-Controller-Laure-Vergeron-40-320.jpg)
![● When versioning is enabled or suspended (cont.):
● NULL VERSIONS:
○ Null versions are created when putting an object before versioning is configured or when
versioning is suspended.
■ Only one null version is maintained in version history.
New null versions will overwrite previous null versions.
○ Target the null version in version-specific actions by specifying the version ID ‘null’.
● DELETING OBJECTS:
○ Regular deletion of objects will create delete markers and return ‘x-amz-delete-marker’: ‘true’
and the version ID of the delete marker in ‘x-amz-version-id’ response headers.
○ Objects with delete markers as the latest version will behave as if they have been deleted when
performing non-version specific actions.
○ Permanently remove delete markers or specific versions by specifying the version ID in the
request query. Example: `DELETE [bucket]/[object]?versionId=[versionId]`
Zenko S3 API: Bucket Versioning](https://image.slidesharecdn.com/dockermeetuptokyo1-180515112948/85/Docker-Meetup-Tokyo-23-Zenko-Open-Source-Multi-Cloud-Data-Controller-Laure-Vergeron-41-320.jpg)
![● When versioning is enabled or suspended (cont.):
● MULTI-OBJECT DELETE:
○ Specify the specific version of an object to delete in a multi-object delete request in the XML
body. Example: http://docs.aws.amazon.com/AmazonS3/latest/API/multiobjectdeleteapi.html
● At any time:
● LISTING OBJECTS:
○ A regular listing will list the most recent versions of an object and ignore objects with delete
markers as their latest version.
○ To list all object versions and delete markers in a bucket, specify ‘versions’ in request query:
■ Example: `GET [bucket]?versions`
○ FMI about output: consult S3 Connector documentation
● GET BUCKET VERSIONING STATUS: use Get Bucket Versioning API.
Zenko S3 API: Bucket Versioning](https://image.slidesharecdn.com/dockermeetuptokyo1-180515112948/85/Docker-Meetup-Tokyo-23-Zenko-Open-Source-Multi-Cloud-Data-Controller-Laure-Vergeron-42-320.jpg)







![These commands assume you have S3 cloned locally, s3cmd configured for your S3 server, AWS
cli configured for a real AWS bucket, and your locationConfig set up
- START SERVER:
S3BACKEND=mem S3DATA=multiple npm start
- MAKE BUCKET:
s3cmd mb s3://[bucket-name]
- PUT OBJECT TO SPECIFIC LOCATION:
s3cmd put [/path/to/file] s3://[bucket-name]/[object-name] --add-header
x-amz-meta-scal-location-constraint:‘[location-name]’
- LIST OBJECTS IN BUCKET:
s3cmd ls s3://[bucket-name]/[object-name]
- GET S3 OBJECT METADATA:
s3cmd info s3://[bucket-name]/[object-name]
- IF PUT TO AWS, LIST OBJECTS ON AWS:
aws s3api list-objects --bucket [bucket-name]
Start S3 Server & Put Object Commands](https://image.slidesharecdn.com/dockermeetuptokyo1-180515112948/85/Docker-Meetup-Tokyo-23-Zenko-Open-Source-Multi-Cloud-Data-Controller-Laure-Vergeron-53-320.jpg)







![[OpenStack Days Korea 2016] Track4 - Deep Drive: k8s with Docker](https://cdn.slidesharecdn.com/ss_thumbnails/45adeepdiveintokubernetes-160226175008-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] Day 2 - E4 - 딥다이브: immutable Kubernetes architecture](https://cdn.slidesharecdn.com/ss_thumbnails/e41530linuxkit-k8s-180704110158-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Open infra] how to calculate the cloud system operating rate](https://cdn.slidesharecdn.com/ss_thumbnails/openinfrahowtocalculatethecloudsystemoperatingrate-210911051805-thumbnail.jpg?width=640&height=640&fit=bounds)










![[OpenStack Days Korea 2016] Track2 - 가상화 네트워크와 클라우드간 협업](https://cdn.slidesharecdn.com/ss_thumbnails/23vmware-160226172243-thumbnail.jpg?width=640&height=640&fit=bounds)





![[OpenStack Days 2016] Track4 - OpenNSL으로 브로드콜 기반 네트,워크 스위치 제어하기](https://cdn.slidesharecdn.com/ss_thumbnails/openstackdaykorea2016jhsuh-160229193513-thumbnail.jpg?width=640&height=640&fit=bounds)







![[Jun AWS 201] Technical Workshop](https://cdn.slidesharecdn.com/ss_thumbnails/aws201general201tworkshop-130708040331-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





















![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)









