Download as PDF, PPTX


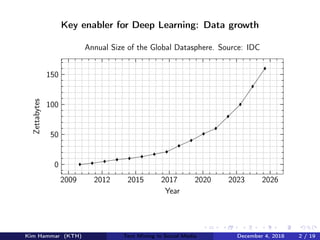
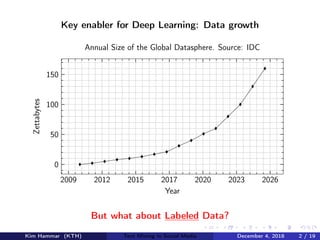

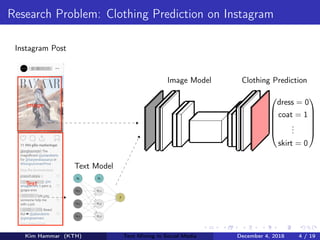

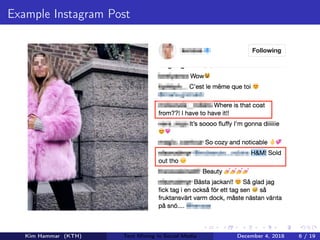
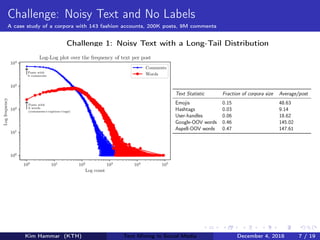
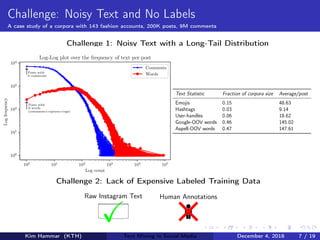








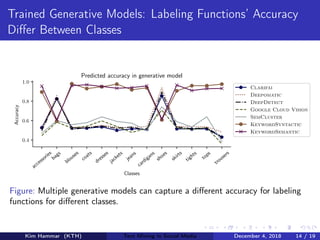








This document describes research on weakly supervised deep text mining of Instagram data without labeled training data. The researchers developed a pipeline that uses various weak supervision sources like open APIs and pre-trained models to generate noisy labels for unlabeled Instagram posts. A generative model is then used to combine the noisy labels, and the combined labels are used to train a discriminative deep learning model for text classification tasks like clothing prediction. The researchers found that their approach using data programming to combine labels outperformed simple majority voting and achieved performance close to human levels.



































































