Download to read offline



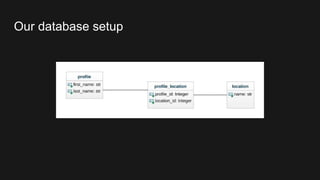

![{
"doc" : {
"first_name": "Carmen",
"last_name": "Sandiego",
"locations": [
"New York",
"London",
"Tangier"
],
"location_id": [
1,
2,
3
]
}
}](https://image.slidesharecdn.com/indexingallthethings-buildingyoursearchengineinpython-171010144107/85/Indexing-all-the-things-Building-your-search-engine-in-python-7-320.jpg)
![def index_single_doc(field_names, profile):
index = {}
for field_name in field_names:
field_value = getattr(profile, field_name)
index[field_name] = field_value
return index
Flattening our documents](https://image.slidesharecdn.com/indexingallthethings-buildingyoursearchengineinpython-171010144107/85/Indexing-all-the-things-Building-your-search-engine-in-python-8-320.jpg)
![location_names = []
location_ids = []
for p in profile.locations.all():
location_names.append(str(p))
location_ids.append(p.id)
What about data in related tables?](https://image.slidesharecdn.com/indexingallthethings-buildingyoursearchengineinpython-171010144107/85/Indexing-all-the-things-Building-your-search-engine-in-python-9-320.jpg)
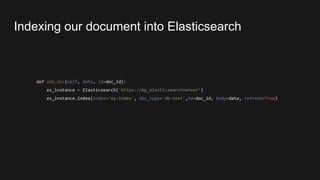

![query_json = {'query': {'simple_query_string': {'query': 'Carmen Sandiego',
'fields':['first_name', 'last_name']}}}
es_results = es_instance.search(index=self.index,
body=query_json,
size=limit,
from_=offset)
Performing our query](https://image.slidesharecdn.com/indexingallthethings-buildingyoursearchengineinpython-171010144107/85/Indexing-all-the-things-Building-your-search-engine-in-python-12-320.jpg)
![{
"took" : 63,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : null,
"hits" : [ {
"_index" : "my-new-index",
"_type" : "db-text",
"_id" : "1",
"sort": [0],
"_score" : null,
"_source": {"first_name": "Carmen", "last_name":"Sandiego","locations": ["New York",
"London", "Tangier"], "location_id": [1, 2, 3]}
}
]
}
}](https://image.slidesharecdn.com/indexingallthethings-buildingyoursearchengineinpython-171010144107/85/Indexing-all-the-things-Building-your-search-engine-in-python-13-320.jpg)
![search_results = []
for _id in raw_ids:
try:
search_results.append(Profile.objects.get(pk=_id))
except:
pass
return search_results
Populating the search results](https://image.slidesharecdn.com/indexingallthethings-buildingyoursearchengineinpython-171010144107/85/Indexing-all-the-things-Building-your-search-engine-in-python-14-320.jpg)


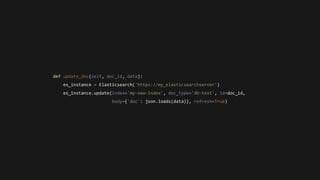


This document discusses building a search engine using Python and Elasticsearch. It describes indexing documents from a SQL database into Elasticsearch for full-text search capabilities. Documents are flattened and indexed one by one using Elasticsearch's JSON over HTTP API. Search queries are performed in Elasticsearch and result IDs are used to retrieve full documents from the SQL database. Asynchronous tasks using Celery are recommended for indexing and updating documents to make the process distributed and production-ready.














































