Download as PDF, PPTX























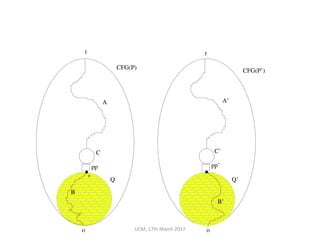






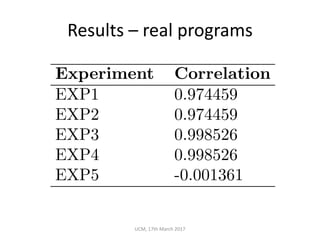
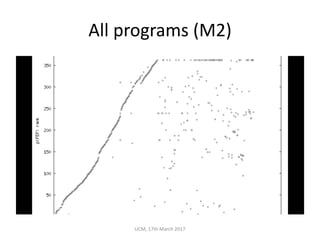
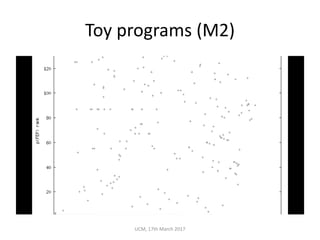
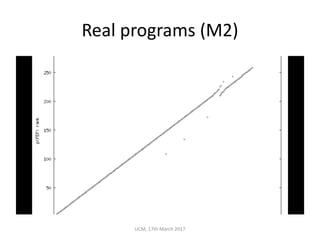


















The document discusses the concepts of conditional entropy and failed error propagation (FEP) in software testing, highlighting the limitations of white-box testing and the importance of coverage. It presents empirical evidence that FEP affects a significant percentage of test cases, which can undermine the effectiveness of testing efforts. The study proposes using information theory measures, such as squeeziness, to predict FEP and improve testing strategies.















































































