Download to read offline










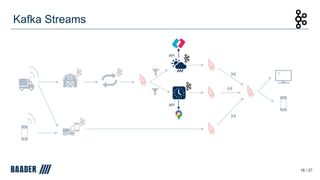
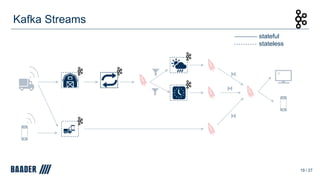


![ksqlDB - Keys
22 / 27
ksqlDB < 0.10.0:
rowtime: 2021/05/12 10:30:00.000 Z,
key: [truck_1],
value: {
"thingId" : "truck_1",
"latitude" : 53.61406,
"longitude" : 10.2328,
"speed_m/s" : 16.1
}
rowtime: 2021/05/12 10:30:00.000 Z,
key: [truck_1],
value: {
"latitude" : 53.61406,
"longitude" : 10.2328,
"speed_m/s" : 16.1
}
ksqlDB ≥ 0.10.0:](https://image.slidesharecdn.com/patrickneffkafkasummit-210607223126/85/Building-a-fully-Kafka-based-product-as-a-Data-Scientist-Patrick-Neff-BAADER-22-320.jpg)
![ksqlDB - Keys
23 / 27
ksqlDB ≥ 0.10.0:
rowtime: 2021/05/12 10:30:00.000 Z,
key: [truck_1],
value: {
"thingId" : "truck_1",
"latitude" : 53.61406,
"longitude" : 10.2328,
"speed_m/s" : 16.1
}
create copy of the key column in the value
More on keys, see Confluent Blog post:
https://www.confluent.io/blog/ksqldb-0-10-updates-
key-columns/](https://image.slidesharecdn.com/patrickneffkafkasummit-210607223126/85/Building-a-fully-Kafka-based-product-as-a-Data-Scientist-Patrick-Neff-BAADER-23-320.jpg)
![ksqlDB - Recreation Handling
● 0.12.0: update queries via CREATE OR REPLACE
● 0.15.0: drop stream and automatically terminate query via DROP
24 / 27
ksql> DROP STREAM MOVING_THINGS;
Cannot drop MOVING_THINGS.
The following streams and/or tables read from this source: [MOVING_THINGS_WITH_DESTINATION].
You need to drop them before dropping MOVING_THINGS.
ksql> DROP STREAM MOVING_THINGS;
Cannot drop MOVING_THINGS.
The following queries read from this source: [CSAS_MOVING_THINGS_WITH_DESTINATION_265].
The following queries write into this source: [INSERTQUERY_37].
You need to terminate them before dropping MOVING_THINGS.
≥ 0.15.0](https://image.slidesharecdn.com/patrickneffkafkasummit-210607223126/85/Building-a-fully-Kafka-based-product-as-a-Data-Scientist-Patrick-Neff-BAADER-24-320.jpg)
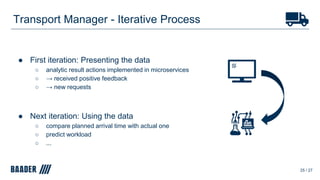



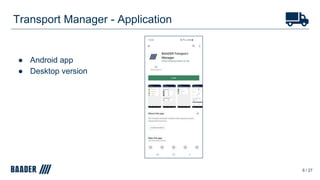
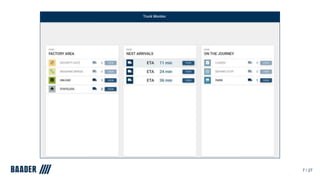
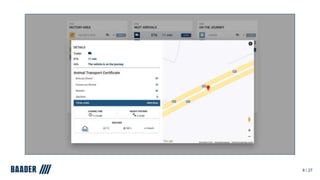
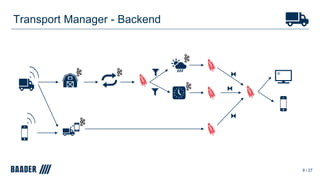
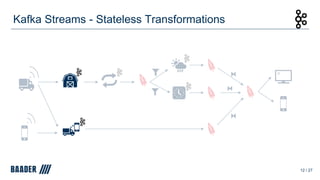
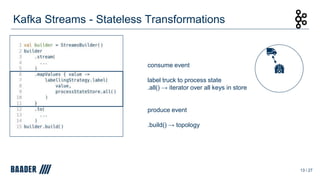
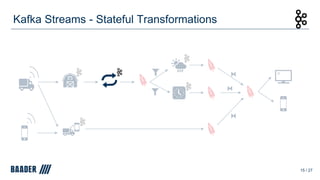
The document outlines Baader's development of a Kafka-based product to enhance data management in animal processing logistics. It describes the Transport Manager application, which includes features like load information processing and predictive analytics for animal welfare and timely deliveries. Additionally, it discusses Kafka Streams and ksqlDB implementations, focusing on iterating and improving microservices through continuous feedback and data analysis.























































































