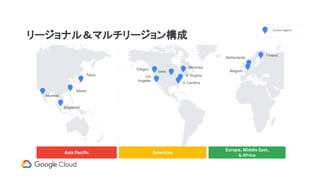
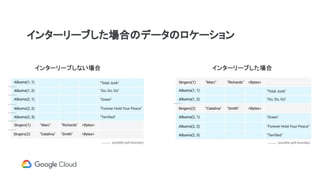
リージョナル&マルチリージョン構成
Asia Pacific Americas
Europe,Middle East,
& Africa
Tokyo
Taiwan
Mumbai
Singapore
Current regions
Netherlands
Finland
Belgium
Los
Angeles
Iowa
N. Virginia
S. Carolina
MontrealOregon
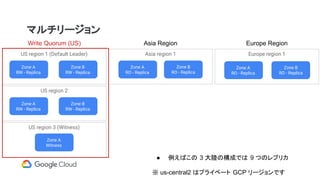
マルチリージョン
Zone A
RW -Replica
US region 1 (Default Leader)
Zone B
RW - Replica
Zone A
RW - Replica
US region 2
Zone B
RW - Replica
Zone A
Witness
US region 3 (Witness)
Write Quorum (US) Asia Region Europe Region
Zone A
RO - Replica
Europe region 1
Zone B
RO - Replica
Zone A
RO - Replica
Asia region 1
Zone B
RO - Replica
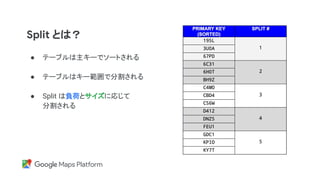
● 例えばこの 3 大陸の構成では 9 つのレプリカ
※ us-central2 はプライベート GCP リージョンです
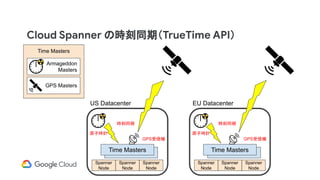
Cloud Spanner の時刻同期(TrueTimeAPI)
US Datacenter EU Datacenter
Time MastersTime Masters
時刻同期 時刻同期
原子時計 原子時計
GPS受信機 GPS受信機
Spanner
Node
Spanner
Node
Spanner
Node
Spanner
Node
Spanner
Node
Spanner
Node
Time Masters
Armageddon
Masters
GPS Masters
14.
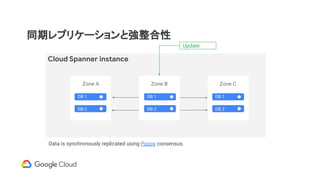
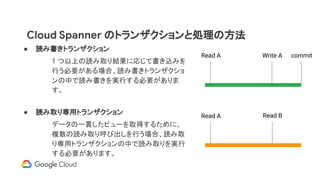
同期レプリケーションと強整合性
Data is synchronouslyreplicated using Paxos consensus.
Update
Cloud Spanner instance
Zone A Zone B Zone C
DB 1
DB 2
DB 1
DB 2
DB 1
DB 2
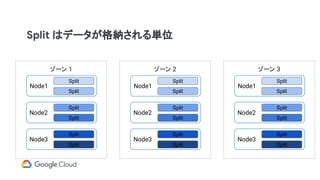
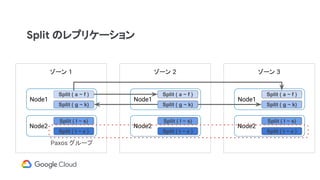
Split のレプリケーション
ゾーン 1
Node1
Node2
Split( a ~ f )
Split ( g ~ k)
Split ( l ~ s)
Split ( t ~ z )
ゾーン 2
Node1
Node2
ゾーン 3
Node1
Node2
Split ( a ~ f )
Split ( g ~ k)
Split ( a ~ f )
Split ( g ~ k)
Split ( l ~ s)
Split ( t ~ z )
Split ( l ~ s)
Split ( t ~ z )
Paxos グループ
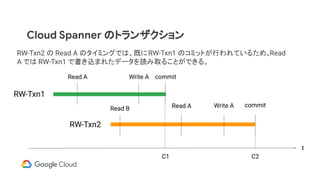
Cloud Spanner のトランザクション
t
RW-Txn1
RW-Txn2
ReadA Write A commit
Read B Read A Write A commit
C1 C2
RW-Txn2 の Read A のタイミングでは、既にRW-Txn1 のコミットが行われているため、Read
A では RW-Txn1 で書き込まれたデータを読み取ることができる。
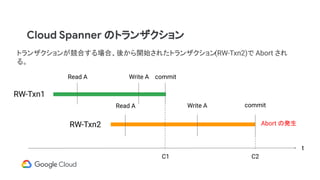
Cloud Spanner のトランザクション
t
RW-Txn1
RO-Txn2
ReadA Write A commit
Read A Read A
C1 R2R1
RO-Txn2 はロックを取らず、過去のコミット履歴のプレフィックスを監視し、Read A が発生し
たタイミングと同じデータを読み続ける。そのため、RO-Txn2 は RW-Txn1 の Write A の影響
を受けない。




















![[GKE & Spanner 勉強会] Cloud Spanner の技術概要](https://image.slidesharecdn.com/gke02-200121091040/85/GKE-Spanner-Cloud-Spanner-36-320.jpg)
![[GKE & Spanner 勉強会] Cloud Spanner の技術概要](https://image.slidesharecdn.com/gke02-200121091040/85/GKE-Spanner-Cloud-Spanner-37-320.jpg)
![[GKE & Spanner 勉強会] Cloud Spanner の技術概要](https://image.slidesharecdn.com/gke02-200121091040/85/GKE-Spanner-Cloud-Spanner-38-320.jpg)





























![[db analytics showcase Sapporo 2018] B13 Cloud Spanner の裏側〜解析からベストプラクティスへ〜](https://cdn.slidesharecdn.com/ss_thumbnails/dbassapporo2018b13-180626013006-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Google Kubernetes Engine と Cloud Spanner の紹介 2020 年 1 月 30 日放送](https://cdn.slidesharecdn.com/ss_thumbnails/0130-200131031138-thumbnail.jpg?width=640&height=640&fit=bounds)








![[Cloud OnAir] Cloud Run & Firestore で、実践アジャイル開発 2020年6月25日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/0625-200625094921-thumbnail.jpg?width=640&height=640&fit=bounds)


![Neo4j Stream, [RDB/NoSQL]Kafka Connector CDC(Change Data Captuer)の紹介](https://cdn.slidesharecdn.com/ss_thumbnails/neo4j-stream-2019-191210054129-thumbnail.jpg?width=640&height=640&fit=bounds)









![[External] 2021.12.15 コンテナ移行の前に知っておきたいこと @ gcpug 湘南](https://cdn.slidesharecdn.com/ss_thumbnails/external2021-211216025522-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Cloud OnAir] 事例紹介 : 株式会社マーケティングアプリケーションズ 〜クラウドへのマイグレーションとその後〜 2020年12月17日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ppp-201221033858-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] 【実演】Google Cloud VMware Engine と VMware ソリューションを組み合わせたハイブリッド環境の...](https://cdn.slidesharecdn.com/ss_thumbnails/pta-201210085248-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Google Workspace でできる データ分析と業務自動化のご紹介 2020年12月3日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ol-201203090835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Google Cloud へのマイグレーション ツールの紹介 2020年11月26日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ii-201126090801-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Google Cloud における RDBMS の運用パターン 2020年11月19日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/yy-201119084816-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] 事例紹介: 株式会社オープンハウス 〜Google サービスを活用したオープンハウスの AI の取り組み〜 2020年11月1...](https://cdn.slidesharecdn.com/ss_thumbnails/h-201112061942-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] 【Anthos 演習】 解説を聞きながら Anthos を体験しよう 2020年11月5日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ab-201105085037-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] 【Google Kubernetes Engine 演習】解説を聞きながら GKE を体験しよう 2020年10月29日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/bb-201029090440-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Google Cloud の AI / IoT 最新事例紹介 2020年10月22日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/aa-201022092013-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Google Cloud Next '20: OnAir 特別編 〜世界で人気のあったセッション特集〜 2020年9月24日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ooo-200924094839-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Talks by DevRel Vol.5 アプリケーションのモダナイゼーション 2020年9月3日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ffffffffffffffff-200903090943-thumbnail.jpg?width=640&height=640&fit=bounds)

