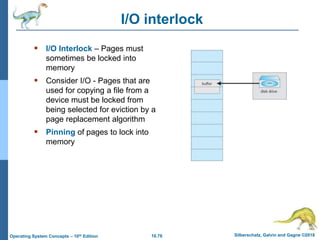
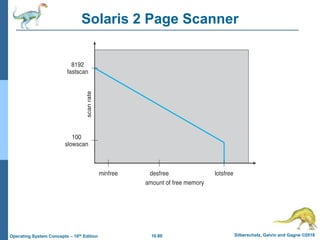
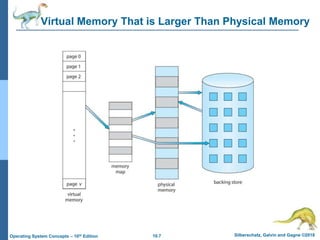
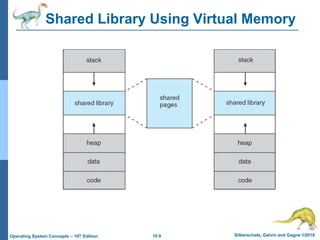
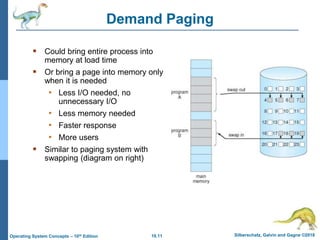
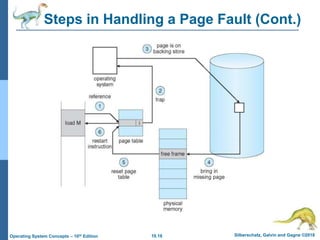
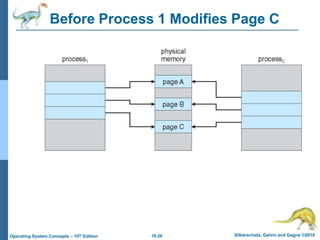
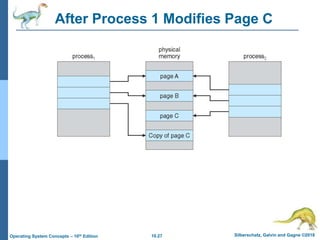
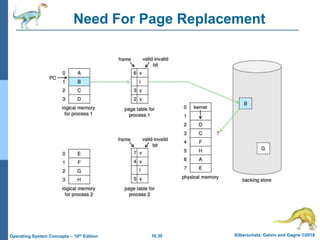
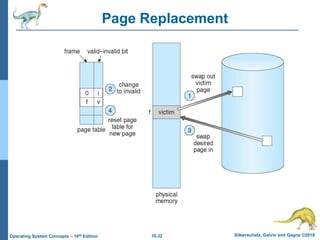
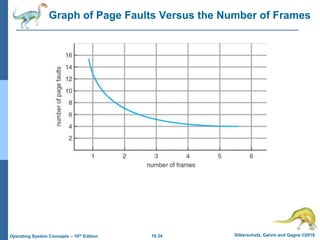
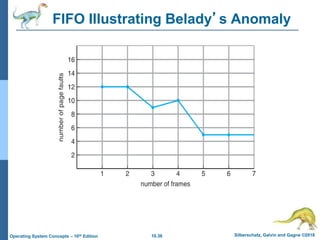
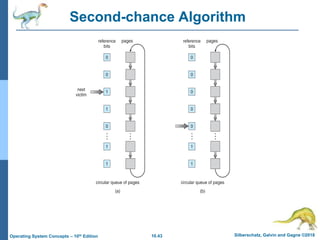
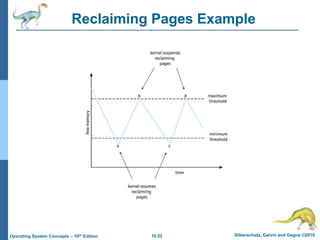
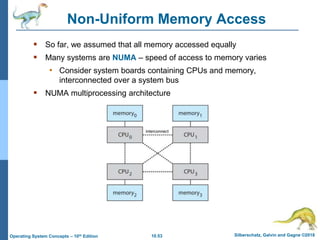
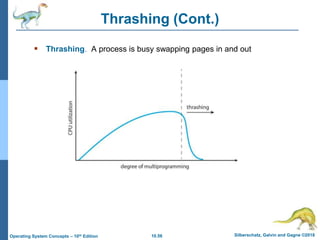
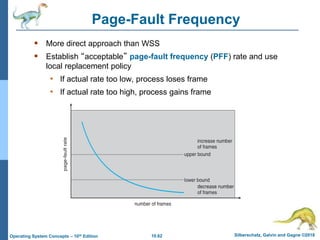
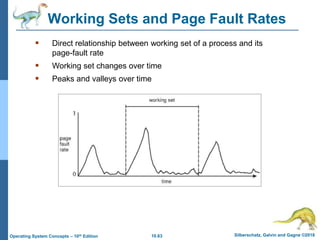
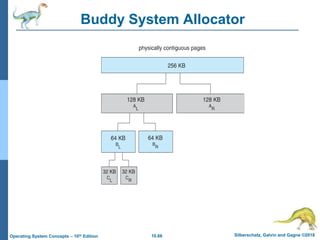
The document summarizes key concepts about virtual memory from the 10th edition of the textbook "Operating System Concepts". It discusses how virtual memory allows processes to have a logical address space larger than physical memory by swapping pages between main memory and secondary storage as needed. When a process attempts to access a memory page not currently in RAM, a page fault occurs which is handled by the operating system by finding a free frame, loading the requested page, and resuming execution. Page replacement algorithms like FIFO are used when free frames are unavailable. Demand paging loads pages lazily on first access rather than up front.
























































![10.75 Silberschatz, Galvin and Gagne ©2018
Operating System Concepts – 10th Edition
Program Structure
Program structure
• int[128,128] data;
• Each row is stored in one page
• Program 1
for (j = 0; j <128; j++)
for (i = 0; i < 128; i++)
data[i,j] = 0;
128 x 128 = 16,384 page faults
• Program 2
for (i = 0; i < 128; i++)
for (j = 0; j < 128; j++)
data[i,j] = 0;
128 page faults](https://image.slidesharecdn.com/ch10-220105163107/85/Chapter-10-Operating-Systems-silberschatz-75-320.jpg)