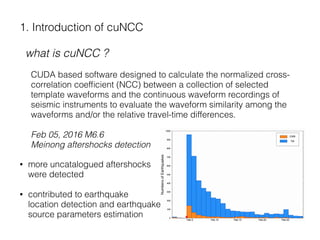
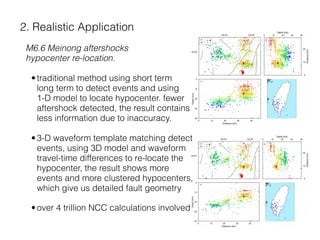
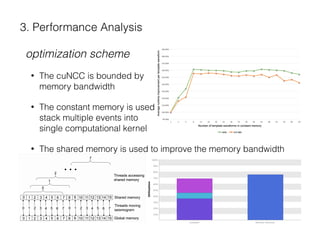
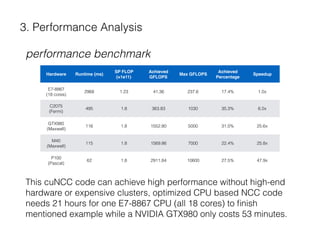
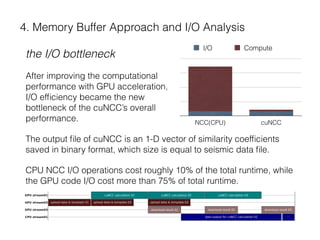
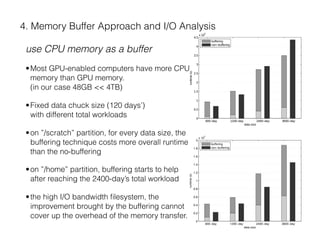
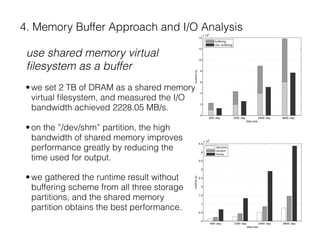
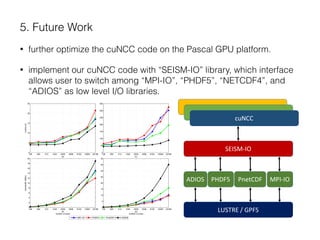
The document describes a CUDA-based software called CUNCC, designed for normalized cross-correlation calculations between earthquake waveform recordings, enabling improved detection of seismic events. It outlines the performance benefits gained through optimization techniques such as enhancing memory bandwidth utilization, and details the impact of I/O bottlenecks as GPU acceleration is applied. Future work includes further optimizations and the integration of additional I/O libraries for enhanced flexibility.