1. Introduction
Chemical tissue staining is currently used for
studying cancer pathology: tissue cores
extracted from a patient are thinly sliced and
stained using chemical dyes to highlight
different cell types. The stained tissue samples
are examined under a microscope to diagnose
disease.
The Bioimaging Science and Technology group
at the Beckman Institute uses infrared
spectroscopy to directly collect chemical
information. The goal is to use this quantitative
information to improve disease diagnosis by
providing more accurate information to
pathologists.
Methods and results
The first step in our program is loading the
ENVI header information. This includes all of
the properties of the image, such as the x and y
resolution, the resolution of the infrared spectra
(number of bands), and the units of
measurement used. These parameters define
how the random forest is constructed. Our
program stores them as variables for later use.
Due to the large file size of the ENVI images,
an entire image cannot be stored in memory,
and must rather be streamed from the hard
drive and classified sequentially. This is known
as out-of-core processing. Our program feeds
individual chunks into the classifier one by one,
building up a fully classified image.
Because four collaborators all worked on the
same program concurrently, utilizing a
distributed version control system called Git
was extremely important. This allowed us to
keep track of and comment on any edits made
in our code. Git also allows for branching, so
separate users can work independently, then
merge all the branches back into one main
master branch.
Our code was managed using Cmake, which
allows us to easily link our programs with
external libraries, such as Qt and ALGLIB,
which were used for user-interface design and
classification.
Spectroscopic Images
This resulting infrared signal produces a digital
image, in which each pixel corresponds to a
frequency in a spectrum graph where the point
will vibrate. This data is stored using the ENVI
(Environment for Visualizing Images) format.
This large, specialized file is then run through a
classification program using the Random-
Forest algorithm (Figure 5). This classifier
analyzes each pixel based on its spectrum and
surroundings.
David Bergvelt and Max Li, under the supervision of David Mayerich
Led by Professor Bhargava at Bioimaging Science and Technology group, Beckman Institute, University of Illinois at Urbana-Champaign
Digitizing cancer pathology research
Acknowledgments
We would like to thank Professor Bhargava for
giving us the opportunity to work alongside his
Bioimaging group, and also we would like to
thank David Mayerich for giving us the chance
to try our hands at programming, and guiding
us along our way.
We would also like to thank David Bergandine
for sponsoring us and advising us throughout
the I-STEM program, and Ms. Williams and
Mrs. Destefano for organizing the I-STEM
program.
Experience
We found that the hands-on experience of
working with programming in C++ helped a lot
in learning the language. Learning how to use
Git and Cmake, two industry standard
applications, will be very useful in the future. It
was also a very interesting experience
connecting the topics of cancer pathology and
statistical analysis together using programming
languages.
Working along with Dr. Mayerich in Professor
Bhargava’s group gave us the experience of
working in a research group doing cutting edge
research related how the future of cancer
research and diagnosis will look like. Overall,
the I-STEM experience was excellent, and we
hope to continue working with Dr. Mayerich and
the Bhargava group in the future.
Aim
Our project focuses on building a C++ program
which allows the user to load a spectroscopic
image of a tissue sample, feed it into the
Random-Forest algorithm, and output a
classified image showing differences in tissue
type.
The final program will incorporate a graphical
user interface, making it user-friendly and
useful to a wide range of researchers. We hope
that this will encourage researchers to adopt
these quantitative methods in their own
research and diagnostic practices. In
particular, we expect that this type of
technology will be useful for accurate disease
diagnosis in hospitals.
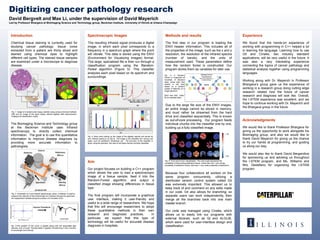
Fig. 1: Image of a breast tumor biopsy stained using various chemical methods
(left) and an image of the same biopsy stained digitally after spectroscopic
imaging and classification (right).
Fig. 5: A Random
Forest is composed of
hundreds of decision
trees, where each tree
selects a cell type
based on a random
subset of features of a
single spectrum.
Each tree then “votes”
for its selected class.
Fig. 4: Each pixel making up the image of the digitally stained cell carries its
own infrared spectrum (a and b). The image is the classified into various cell
types, such as epithelium, fibroblasts, etc. The accuracy of the classifier is
given using the precision: the ratio of cell types that are correctly classified.
1200 1800 2400 3000 3600
0.0
0.1
0.2
0.3
0.4
Absorbance(a.u.)
Wavenumber (cm-1
)
Fig. 2: Schematic of a mid-infrared spectroscopy setup. A detector is used to
measure the intensity of the infrared light as it passes through the specimen,
the independent variable being the position of a movable mirror.
Fig. 3:The position of the mirror is plotted along with the associated light
intensity, and a Fourier Transformation if applied, transforming it into a function
of wavelength and intensity.
1.00
0.00
Fig. 6: Final result of our classification. The color scale represents the
probability of tissue being epithelium tissue, where dark red = very strong
probability of epithelium tissue, dark blue = very weak probability of epithelium.
(a) (b)
(c)