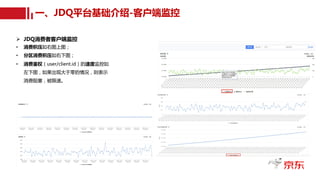
Ø JDQ技术优化实践-MM优化
ü JDQ集群间数据同步服务MirrorMaker4.0服务优化,随着业务的数据量增长,MM性能达到瓶颈,性能受压缩方式影响大。优化:去
中间数据解压缩、压缩环节,去掉对压缩方式的依赖。
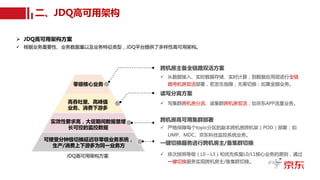
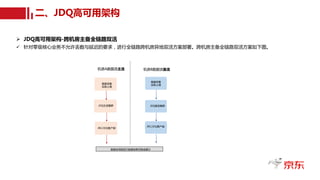
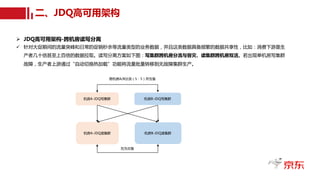
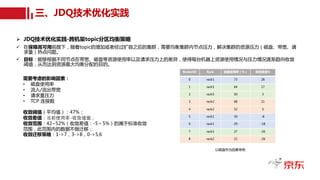
读写分离与跨机房部署
•读写分离:分担生产(写集群)、消费(读集群)压力,生产、消费解耦。
• 双读热备:跨机房数据镜像。
• 跨机房读集群部署既减轻单个机房压力,又可实现跨机房物理隔离与容灾。
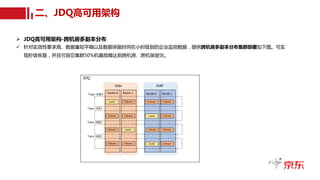
JDQ-MM数据镜像服务架构与优化研发设计
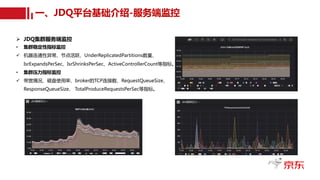
三、JDQ技术优化实践
机房A 机房B
Producer Producer Producer Producer Producer Producer
Consumer Consumer Consumer Consumer Consumer Consumer
push push
pull pull
MM
MM
MM
MM
JDQ写集群
JDQ写集群
JDQ读集群 JDQ读集群
跨机房
互备
跨机房
互备
JDQ读写分离高可用架构图
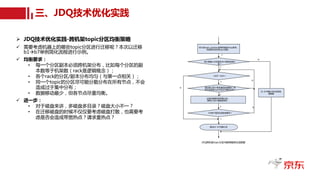
JDQ-MirrorMaker
JDQ-A
Cluster
JDQ-B
Cluster
Buffer
MM-Consumer MM-Producer
Deserializer
Decompress
Consumer
Record
Producer
Record
Serializer
Compress
Record
Batch
Record
Batch
x
x
x
x
x
x
x
x
JDQ-MM优化数据同步流程图
消耗CPU
14.
三、JDQ技术优化实践
Ø JDQ技术优化实践-MM优化
ü 下面是经过我们特殊优化之后MM的性能压测结果(注:相同条件下,使用线上流量数据进行压测)。
ü相比与优化之前MM任务,CPU的使用率从90%左右下降到20%,
降低4倍以上(左上图)。
ü 相比与MM3.0,MM4.0每分钟单Pod单分区同步数据量从500w增
加到800w,速度提升60%,同时GC次数减小(左下图)。
ü 同时,我们按照我们的业务场景进行了相应的功能研发:
• 支持指定数据字段过滤;
• 支持单任务同步多topic并切自动识别同步topic列表信息变更。
• 支持多种数据同步策略:
a) Follow模式:源/目标集群严格进行数据;
b) 针对存在消息key热点数据采取粘性分区策略进行目标
集群数据的二次均衡(主要是为了消除源集群按照消息
key存在热点分区问题,从而保障目标集群的消费下游
均衡消费)。
c) 按照消息key做hash同步数据(为了解决源集群与目标
集群分区不一致,目标集群可按需扩分区)。
三、JDQ技术优化实践
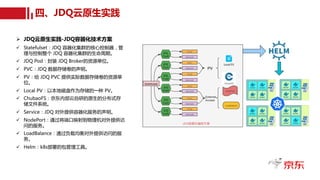
Ø JDQ技术优化实践-跨机架topic分区均衡策略
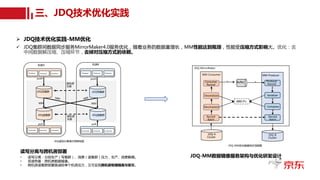
ü 需要考虑机器上的哪些topic分区进行迁移呢?本次以迁移
b1àb7举例简化流程进行示例。
ü均衡要求:
• 每一个分区副本必须跨机架分布,比如每个分区的副
本数等于机架数(rack是逻辑概念);
• 各个rack的分区/副本分布均匀(与第一点相关);
• 同一个topic的分区尽可能分散分布在所有节点,不会
造成过于集中分布;
• 数据移动最少,但各节点尽量均衡。
ü 进一步:
• 对于磁盘来讲,多磁盘多目录?磁盘大小不一?
• 在迁移磁盘的时候不仅仅要考虑磁盘打散,也需要考
虑是否会造成带宽热点?请求量热点?
对b1的topic-partition按照存储进行top排序,
并获取所有所有topic信息;
输出b1~b7均衡计划
记录迁移操作到均衡计划;
更新b1与b7磁盘使用率;
Y
N
Y
Y
Y
top0~topm;
预迁移之后b7是否满足收敛要求?并
且不会造成topic分区过于集中分布?
b1和b7是否达到收敛要求?
Y N
预计算最小分区是否令b7满足收敛标
准?
Y
N
b1-b7均衡计划为空的处
理策略
N
JDQ跨机架topic分区均衡策略简化流程图
18.
四、JDQ云原生实践
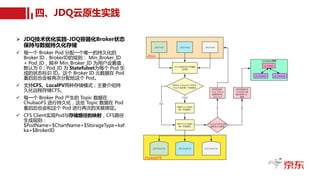
Ø JDQ云原生实践-JDQ容器化技术方案
ü Statefulset:JDQ容器化集群的核心控制器,管
理与控制整个 JDQ 容器化集群的生命周期。
ü JDQ Pod:封装 JDQ Broker的资源单位。
ü PVC:JDQ 数据存储卷的声明。
ü PV:给 JDQ PVC 提供实际数据存储卷的资源单
位。
ü Local PV:以本地磁盘作为存储的一种 PV。
ü ChubaoFS:京东内部云自研的原生的分布式存
储文件系统。
ü Service:JDQ 对外提供容器化服务的声明。
ü NodePort:通过将端口映射到物理机对外提供访
问的服务。
ü LoadBalance:通过负载均衡对外提供访问的服
务。
ü Helm:k8s部署的包管理工具。
19.
四、JDQ云原生实践
Ø JDQ技术优化实践-JDQ容器化Broker状态
保持与数据持久化存储
ü 每一个Broker Pod 分配一个唯一的持久化的
Broker ID,BrokerID的规则: Min_Broker_ID
+ Pod_ID,其中 Min_Broker_ID 为用户设置值,
默认为 0;Pod_ID 为 Statefulset为每个 Pod 生
成的状态标识 ID。这个 Broker ID 元数据在 Pod
重启后也会被再次分配给这个 Pod。
ü 支持CFS、LocalPV两种存储模式;主要介绍持
久化远程存储CFS。
ü 每一个 Broker Pod 产生的 Topic 数据在
ChubaoFS 进行持久化,这些 Topic 数据在 Pod
重启后也会和这个 Pod 进行再次的关联绑定。
ü CFS Client实现Pod与存储路径的映射,CFS路径
生成规则:
$PodName=$ChartName+$StorageType+kaf
ka+$BrokerID
四、JDQ云原生实践
Ø JDQ技术优化实践-JDQ容器化Broker状态
保持与数据持久化存储
ü 每一个 Broker Pod 分配一个唯一的持久化的
Broker ID,BrokerID的规则: Min_Broker_ID
+ Pod_ID,其中 Min_Broker_ID 为用户设置值,
默认为 0;Pod_ID 为 Statefulset为每个 Pod 生
成的状态标识 ID。这个 Broker ID 元数据在 Pod
重启后也会被再次分配给这个 Pod。
ü 支持CFS、LocalPV两种存储模式;主要介绍持
久化远程存储CFS。
ü 每一个 Broker Pod 产生的 Topic 数据在
ChubaoFS 进行持久化,这些 Topic 数据在 Pod
重启后也会和这个 Pod 进行再次的关联绑定。
ü CFS Client实现Pod与存储路径的映射,CFS路径
生成规则:
$PodName=$ChartName+$StorageType+kaf
ka+$BrokerID




















![[오픈소스컨설팅]쿠버네티스를 활용한 개발환경 구축](https://cdn.slidesharecdn.com/ss_thumbnails/opensourceconsutingkubernetesv0-191010000815-thumbnail.jpg?width=640&height=640&fit=bounds)










![Oracle Cloud Infrastructure セキュリティの取り組み [2021年8月版]](https://cdn.slidesharecdn.com/ss_thumbnails/202108ocisecurityoverviewforslideshare-210820075200-thumbnail.jpg?width=640&height=640&fit=bounds)






















