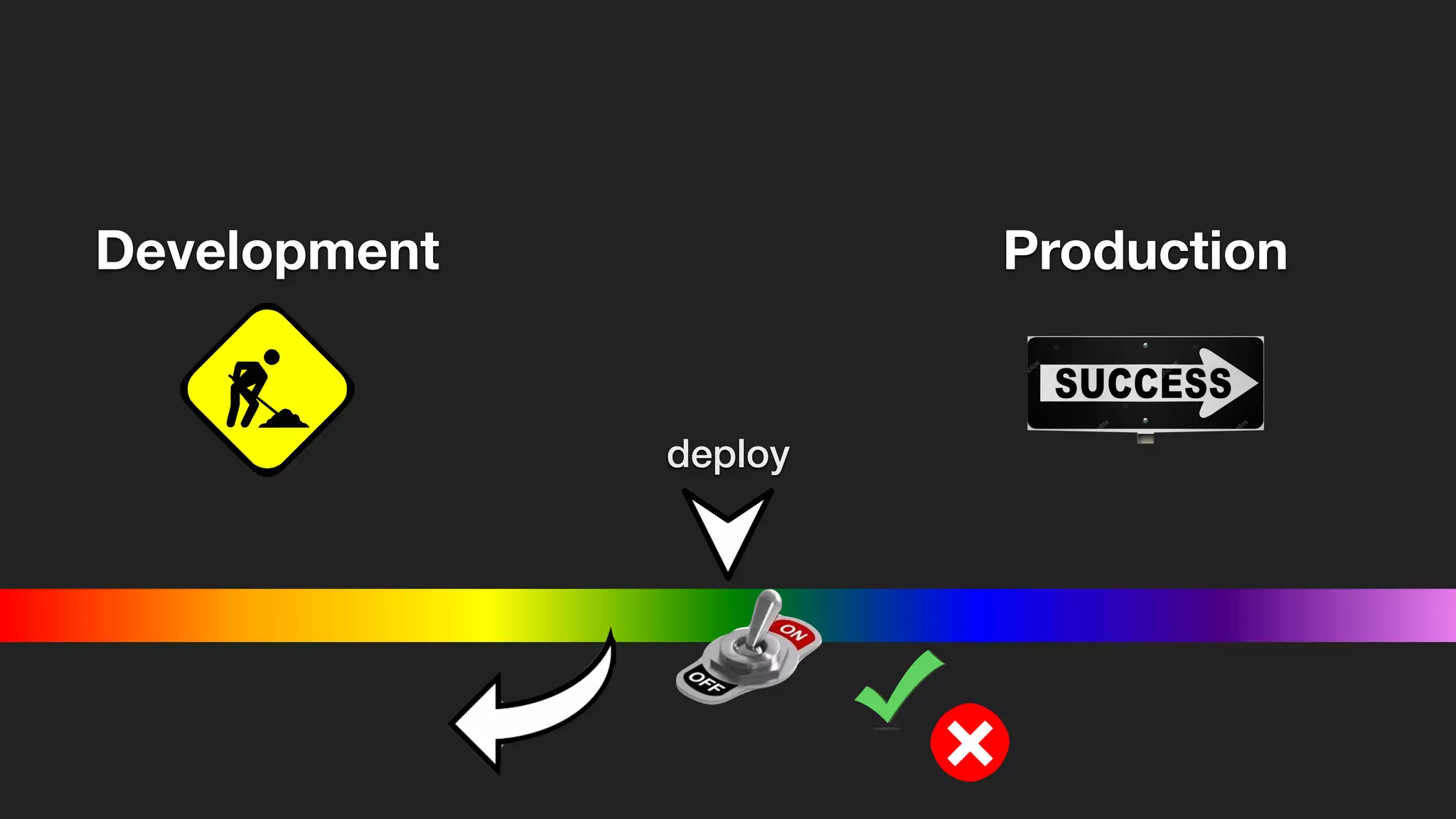
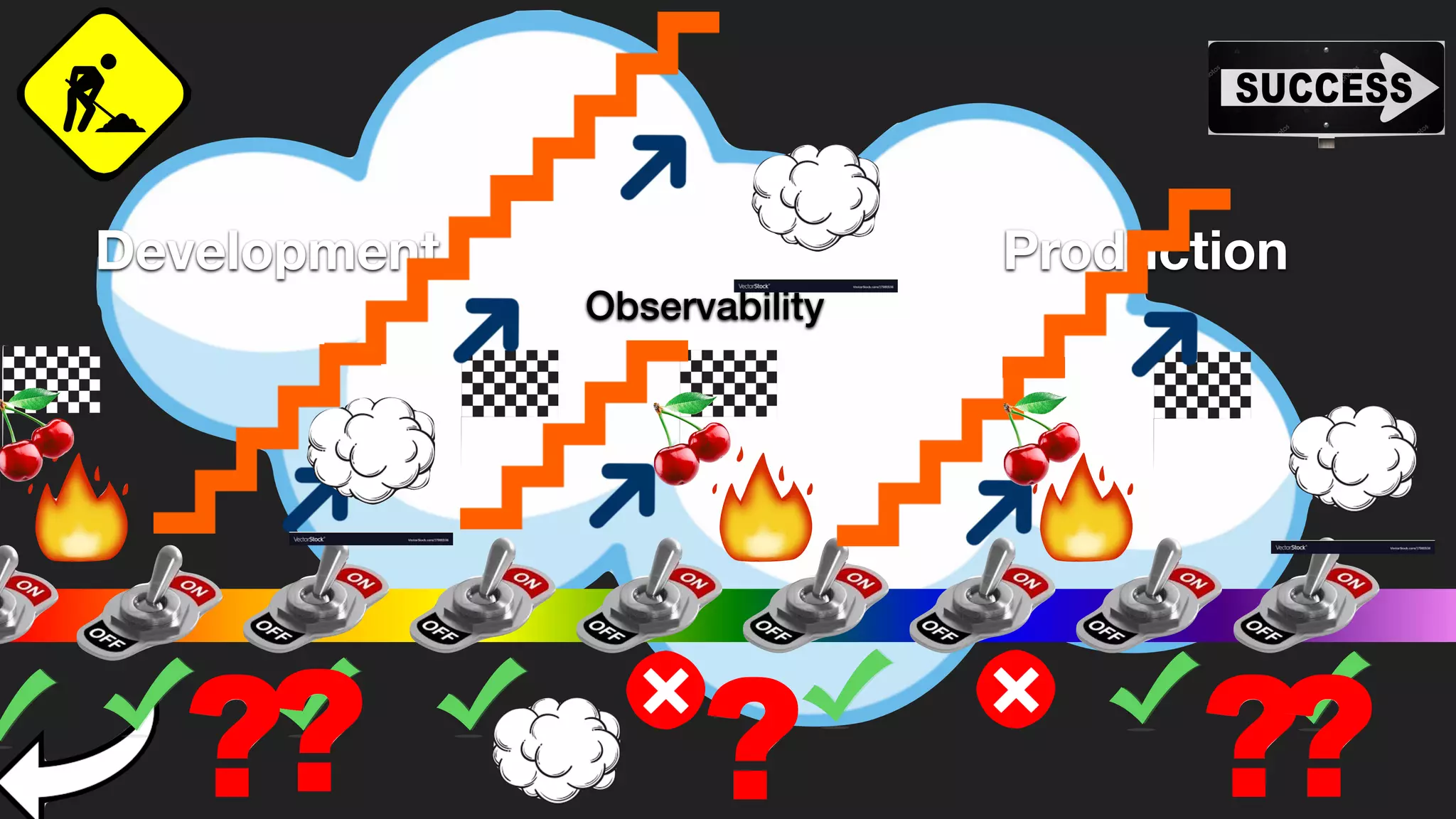
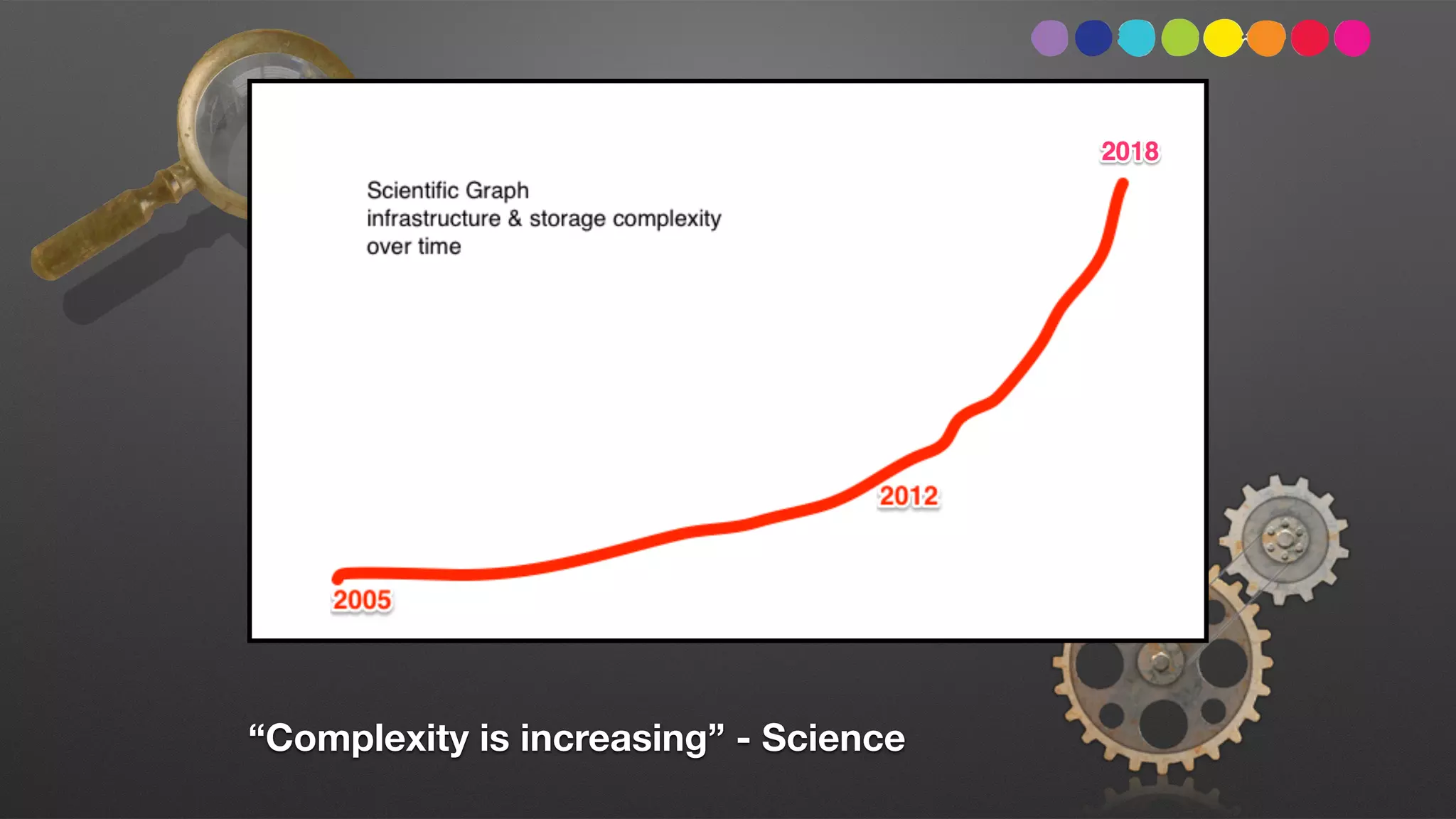
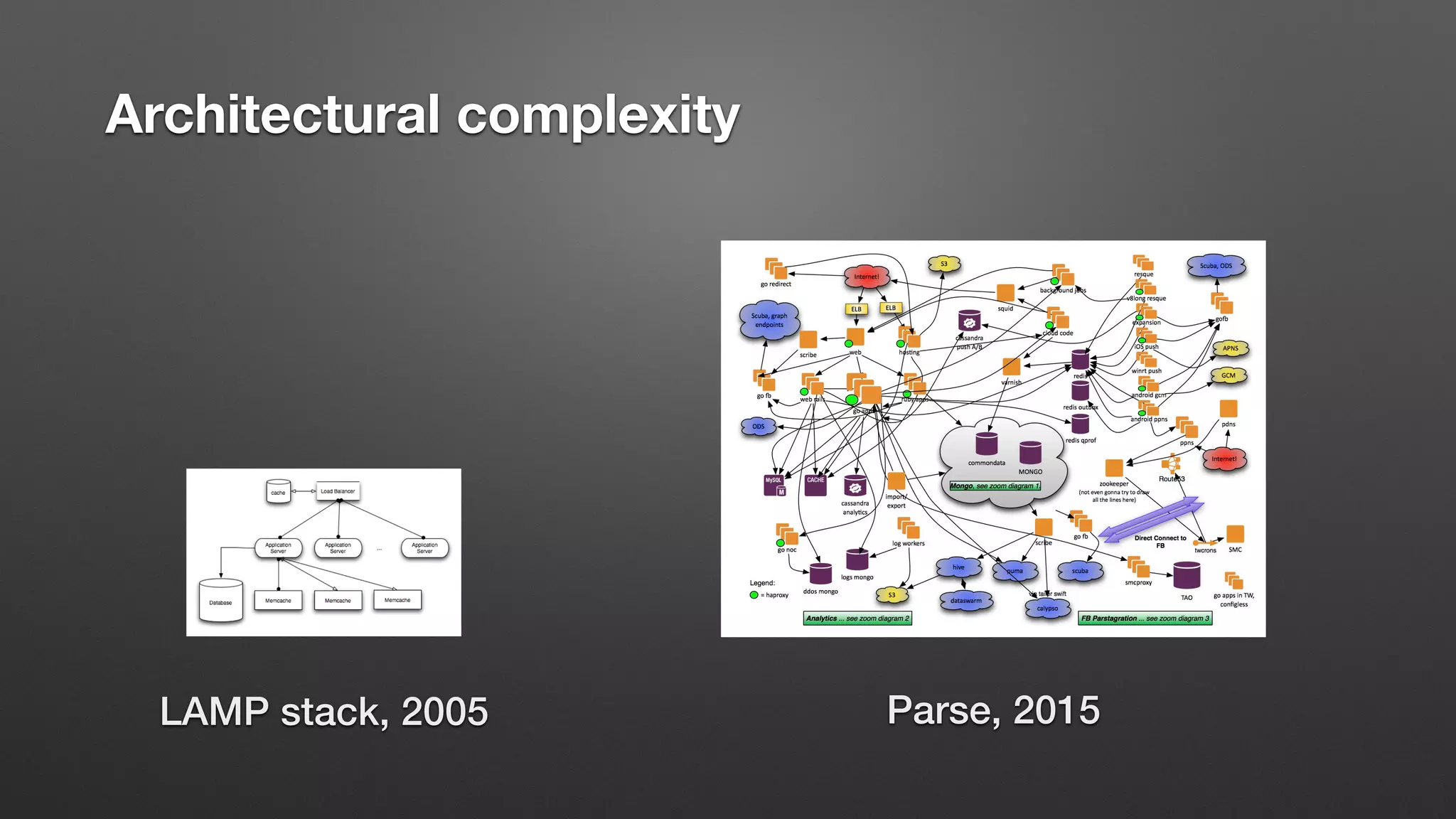
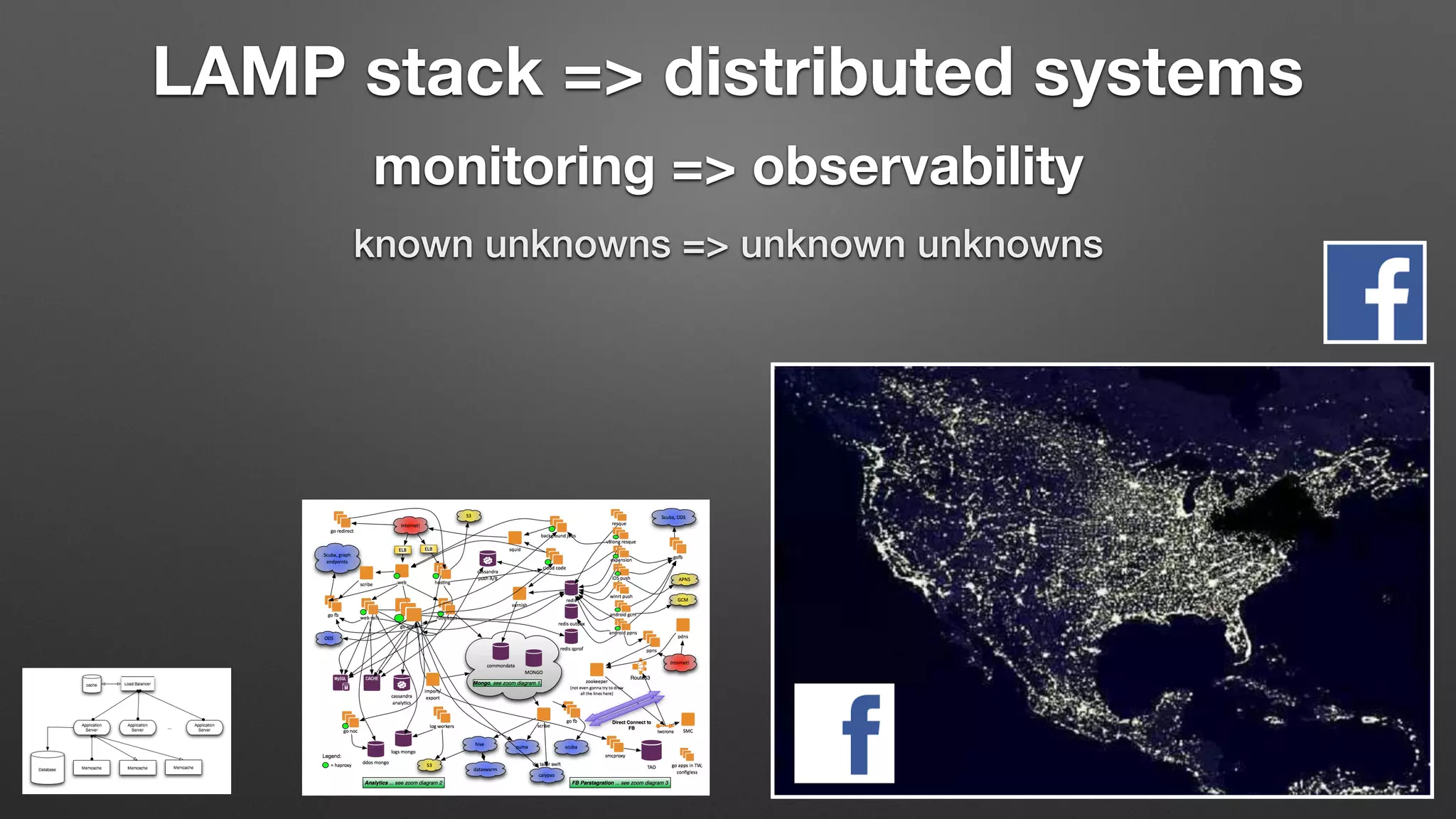
The document discusses the importance of observability over traditional monitoring for complex distributed systems. It argues that observability allows engineers to understand what is happening inside their systems by asking questions from outside using instrumentation and structured data from the system. True observability requires events with high cardinality and dimensionality to account for unknown problems. It emphasizes testing systems in production and gaining an operational literacy to debug issues without prior knowledge.



































































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















