Download to read offline





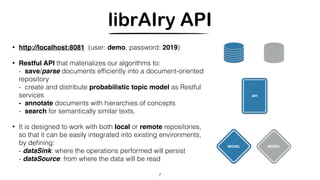
![• http://librairy.linkeddata.es/
• Suite of services aimed at analyzing large-
scale document collections
• It combines NLP techniques, machine
learning algorithms and semantic
knowledge.
librAIry
5
EXPLORER
MODEL
APINLP
REPOSITORY
Carlos Badenes-Olmedo, Jose Luis Redondo-Garcia, and Oscar Corcho. 2017. Distributing Text Mining tasks with librAIry. In Proceedings of the 2017 ACM Symposium on Document Engineering
(DocEng 17). ACM, New York, NY, USA, 63-66. [DOI][PDF]](https://image.slidesharecdn.com/crosslingual-search-engine-191120220018/85/Crosslingual-search-engine-5-320.jpg)


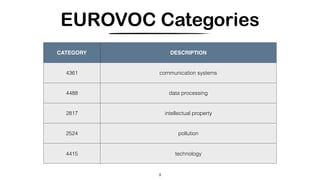

















This document outlines steps to build a cross-lingual search engine using topic modeling and document annotations. It describes loading English and Spanish documents, training topic models on each language, annotating documents with topics, and building a search interface to browse the multi-lingual corpus filtered by topics, languages, and semantic similarities. External topic models can also be used to annotate documents to create a cross-lingual search engine.












































































