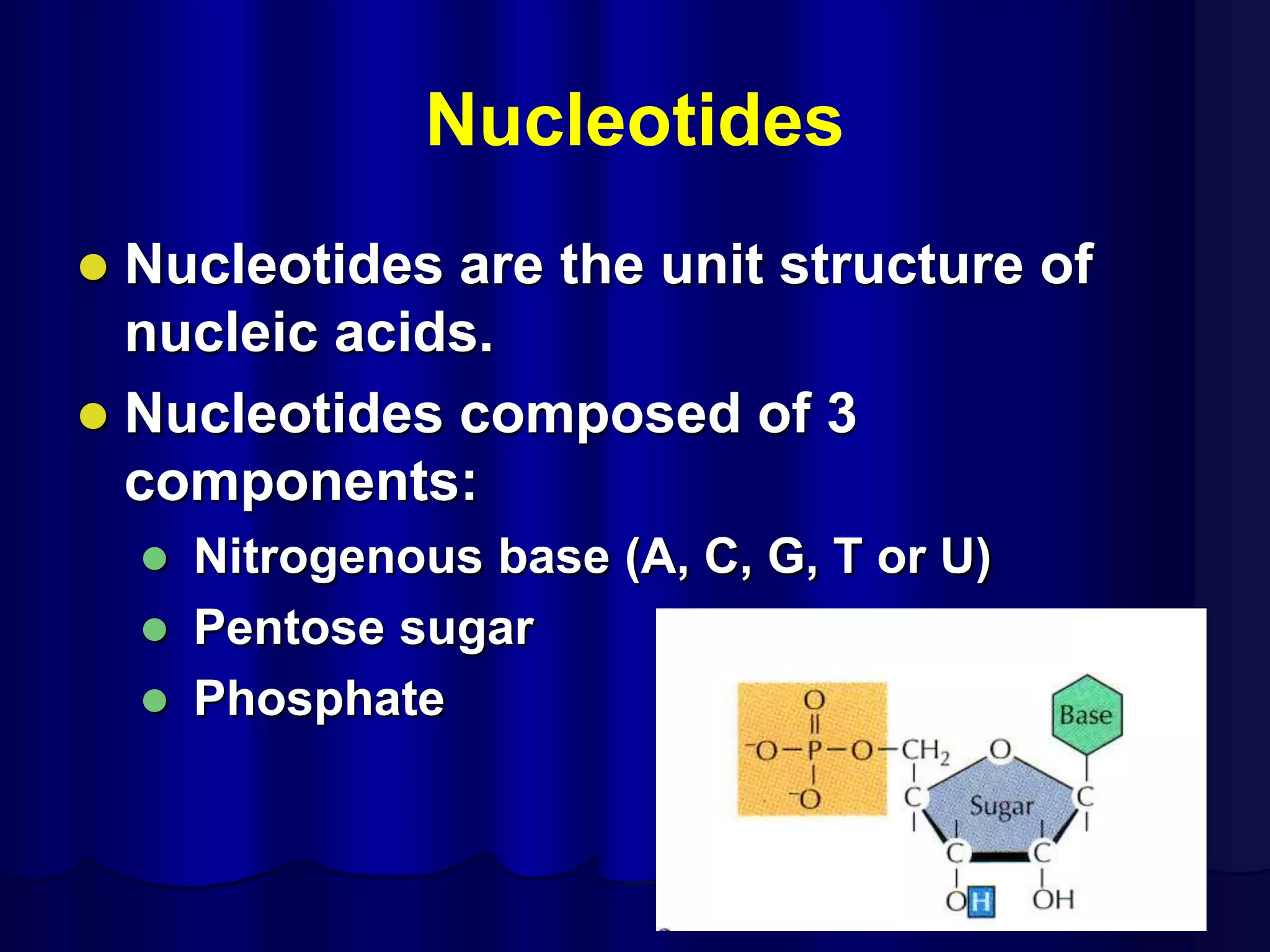
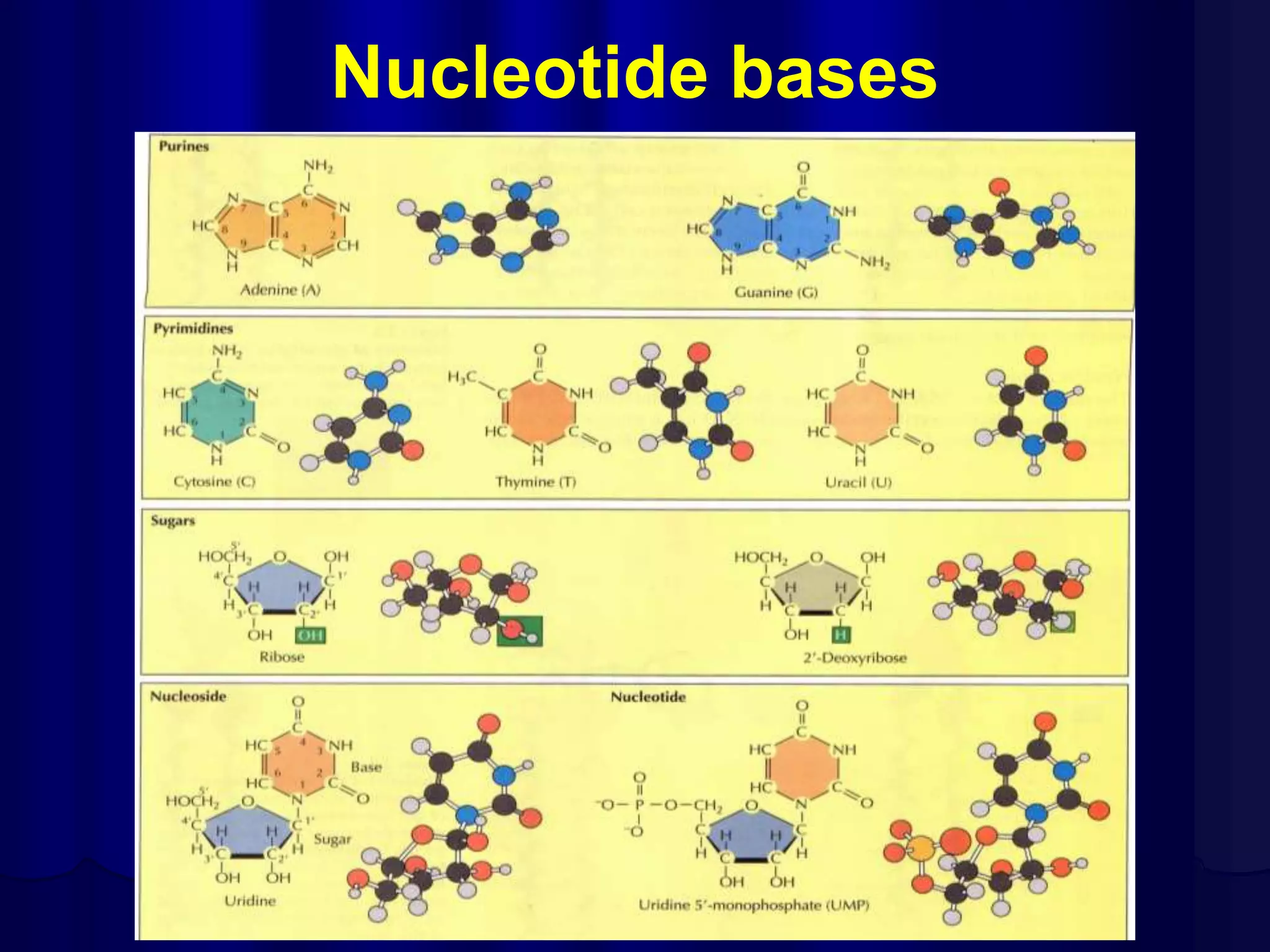
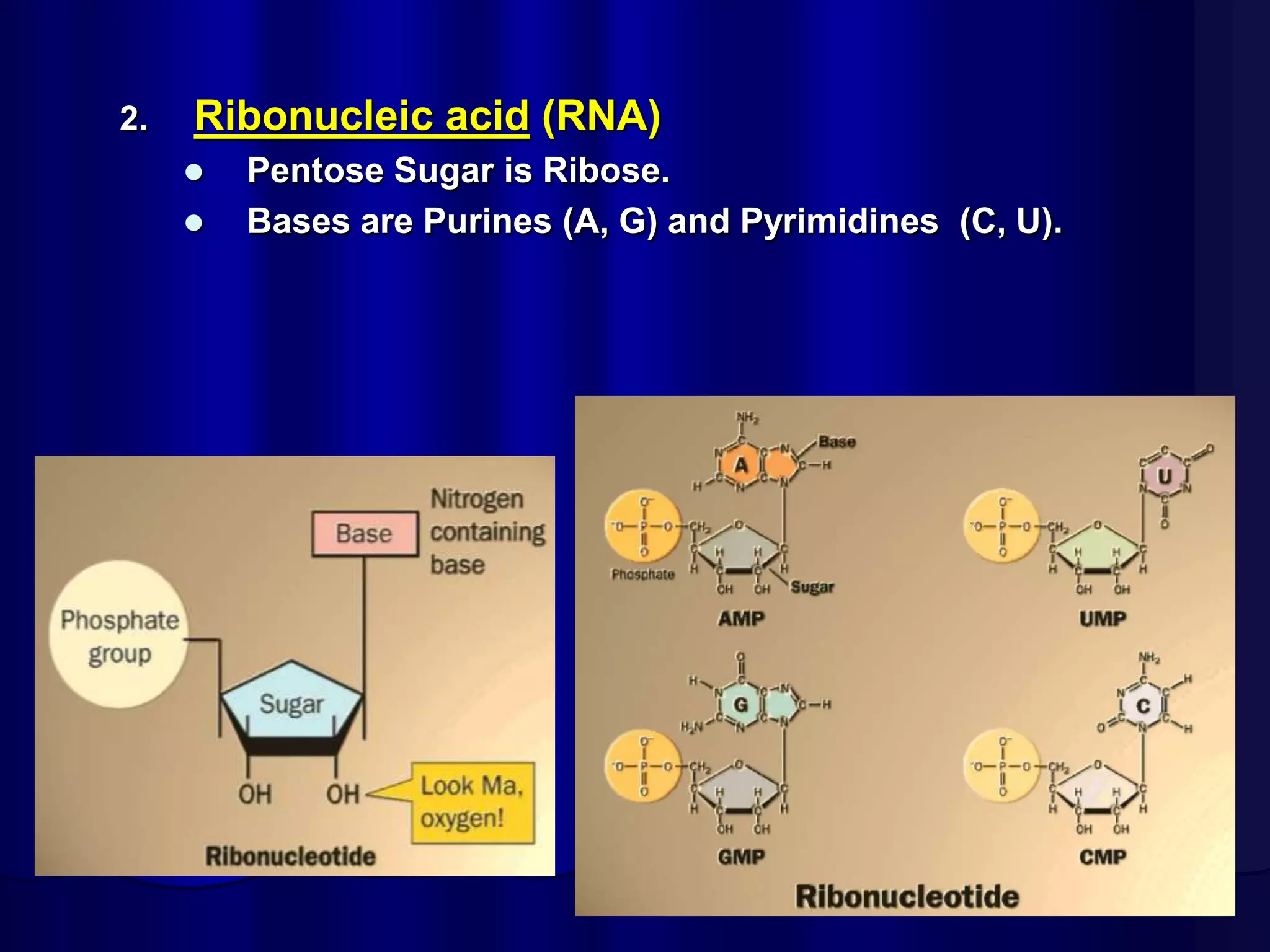
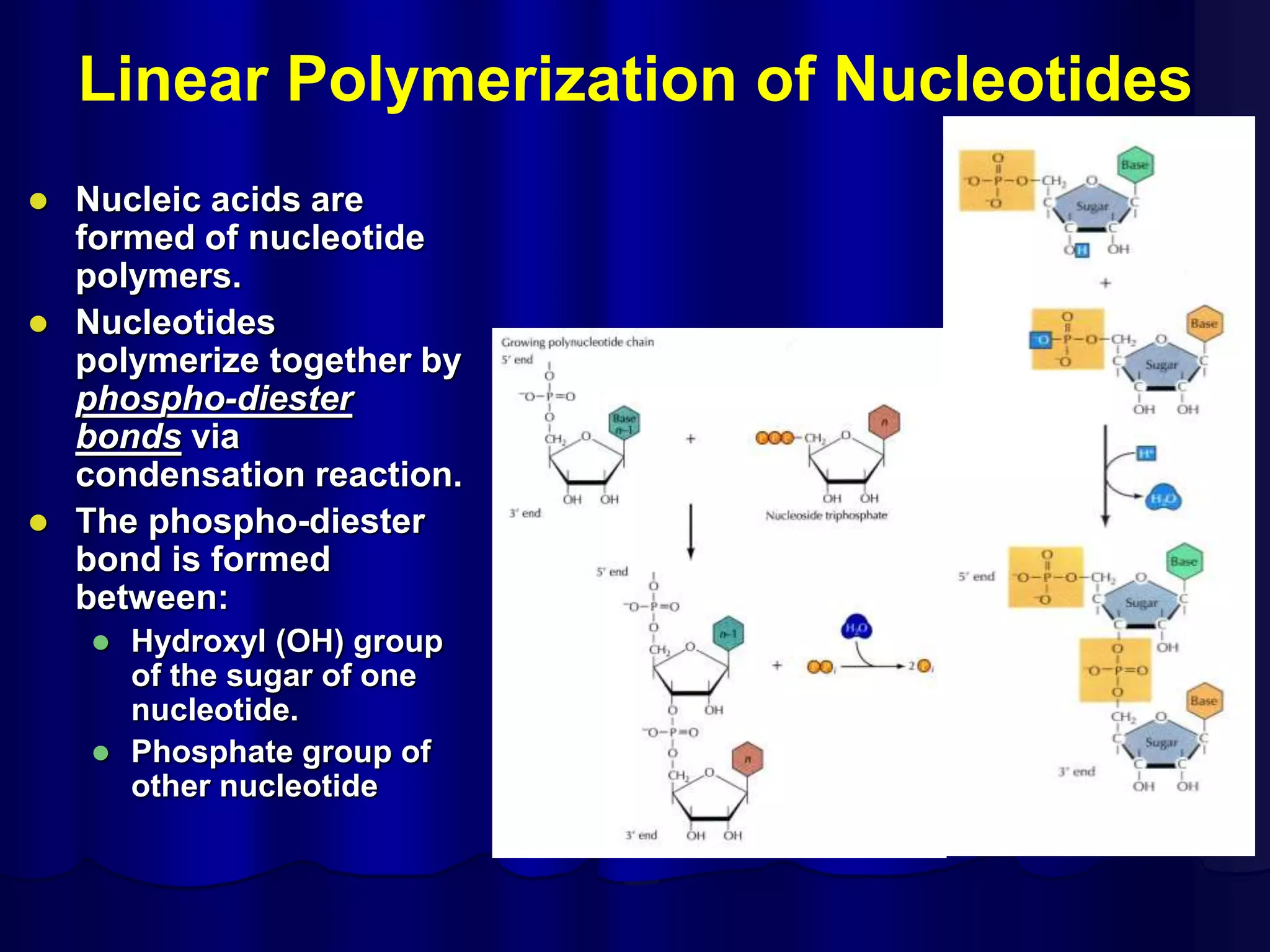
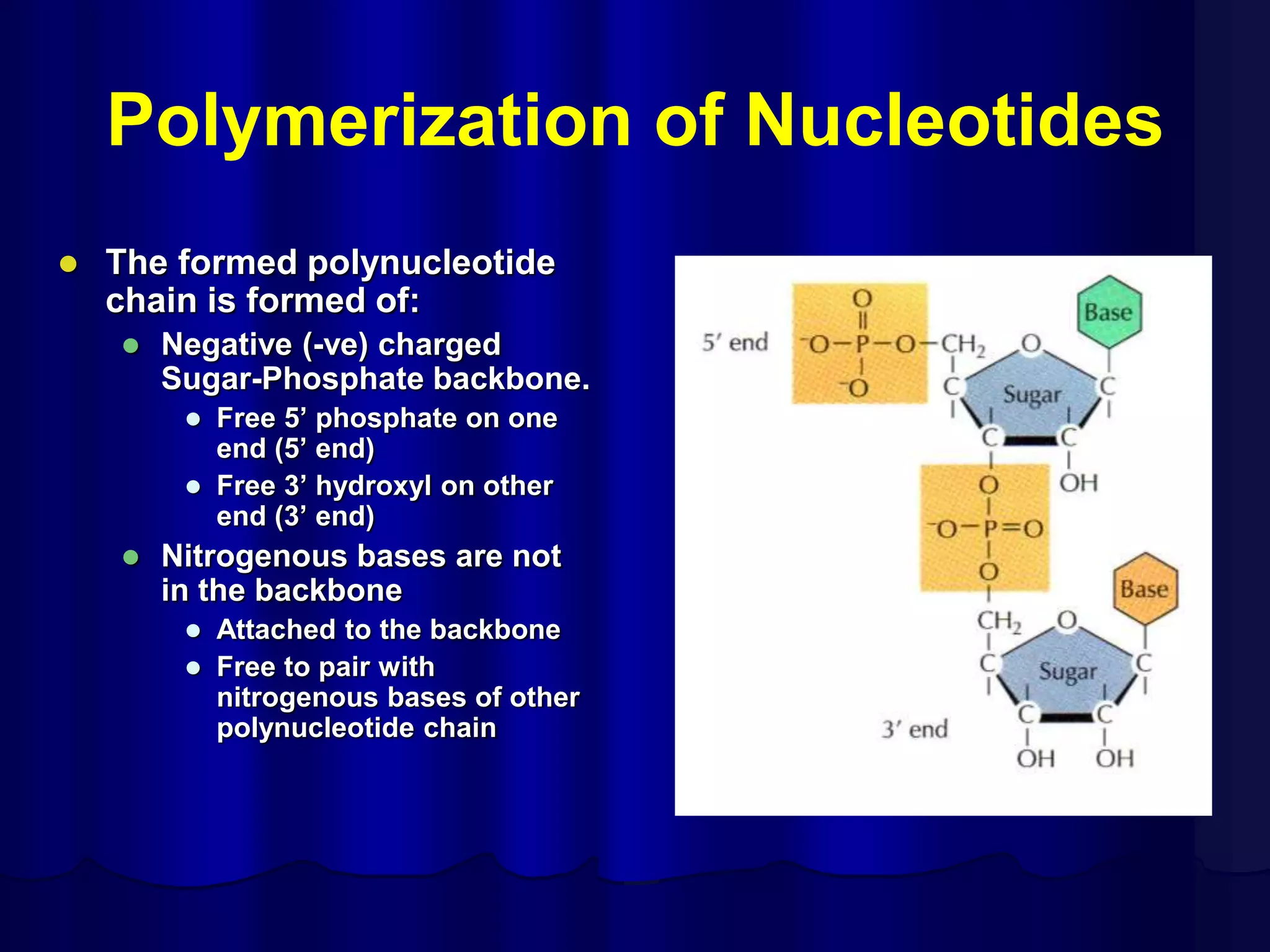
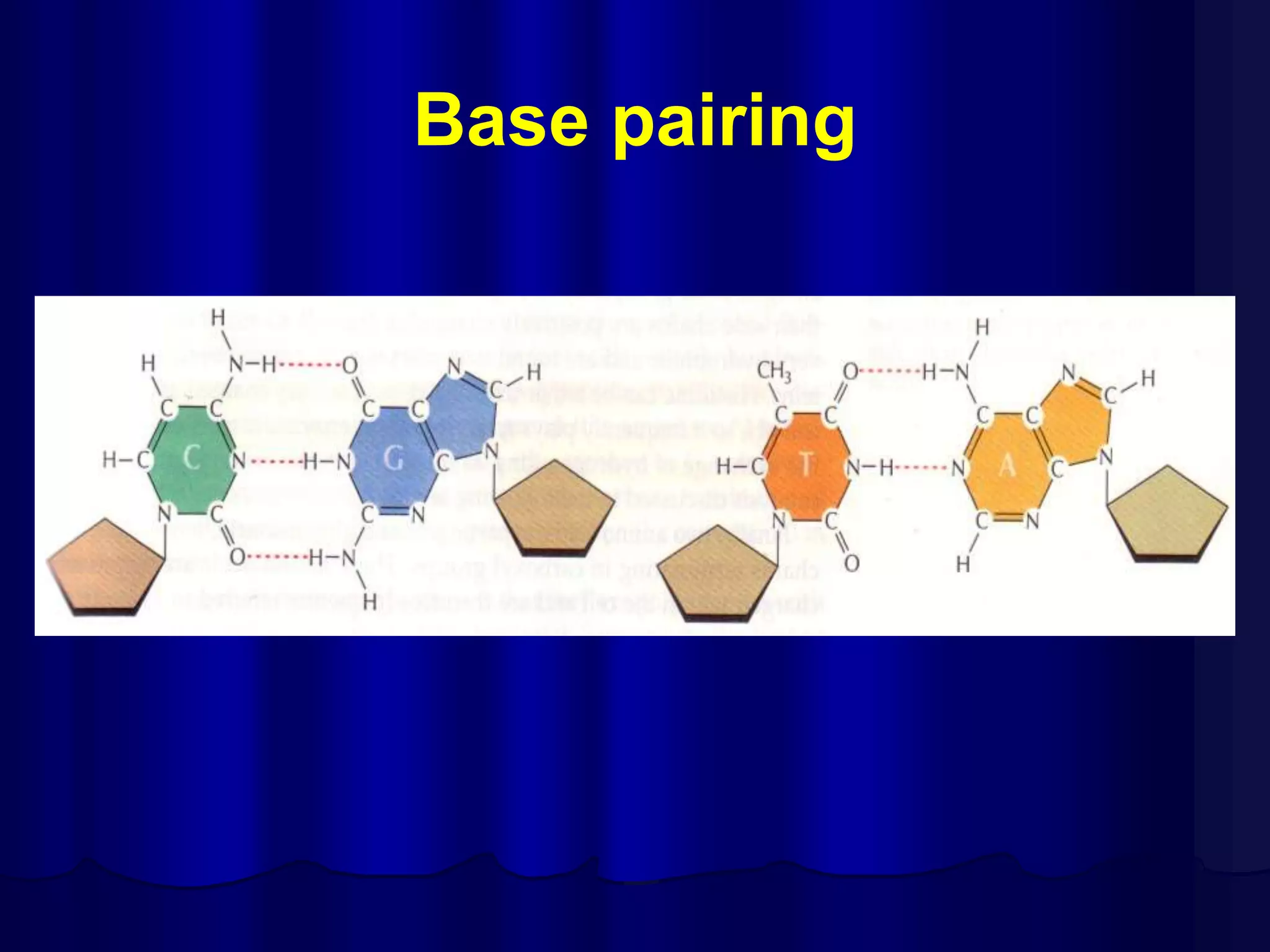
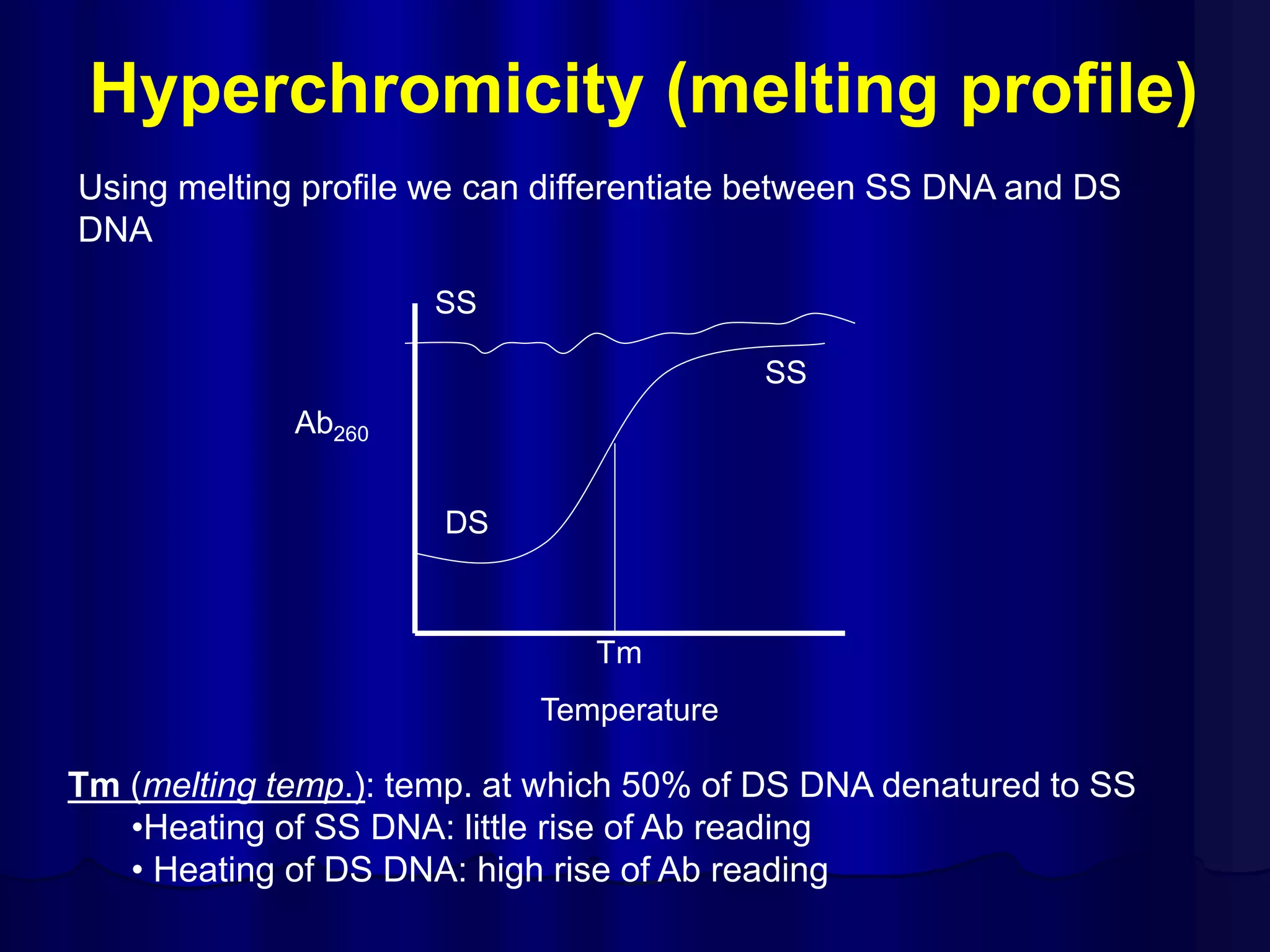
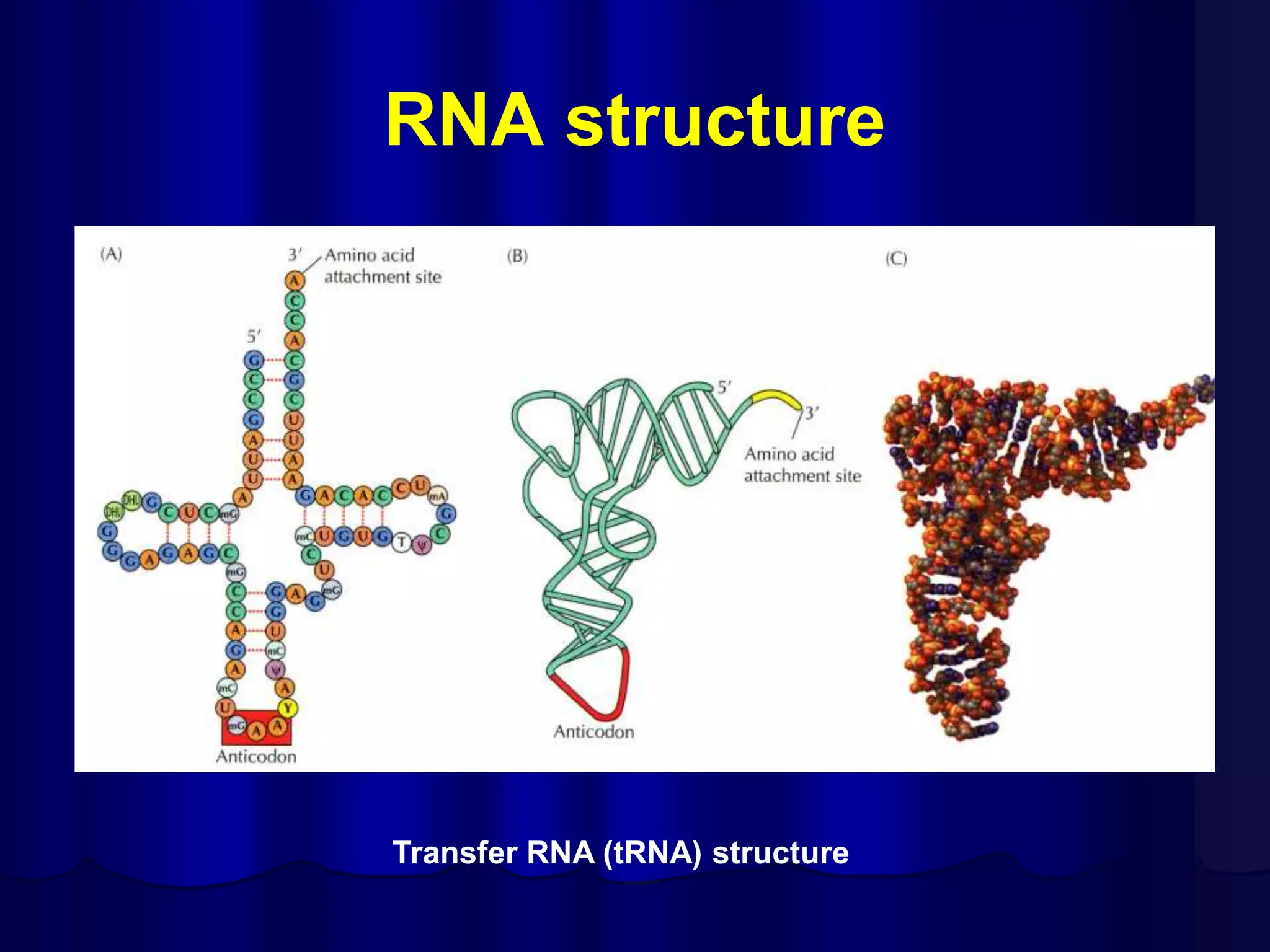
The document summarizes key aspects of DNA structure and function. It describes the central dogma of molecular biology whereby DNA is transcribed into RNA and then translated into protein. It explains gene expression and the genetic code using codons. It discusses the structures of nucleic acids, nucleotides, and their polymerization to form DNA and RNA. It also summarizes DNA replication, the different forms of DNA/RNA, and their complementary base pairing.




































































![Apporach to lung biopsy [Auto-saved].pptx latest](https://cdn.slidesharecdn.com/ss_thumbnails/apporachtolungbiopsyauto-saved-251211225655-93258539-thumbnail.jpg?width=640&height=640&fit=bounds)







