Download as PDF, PPTX



























The document discusses the importance of HATEOAS (Hypermedia as the Engine of Application State) within RESTful APIs, emphasizing that it reduces assumptions between client and server to accommodate future changes. A case study illustrates how incremental updates to an API can impact user experience and backward compatibility, stressing the need for flexibility as features and services evolve. The takeaway highlights HATEOAS as crucial for minimizing maintenance costs while supporting legacy applications, even as it introduces complexities in efficiency.
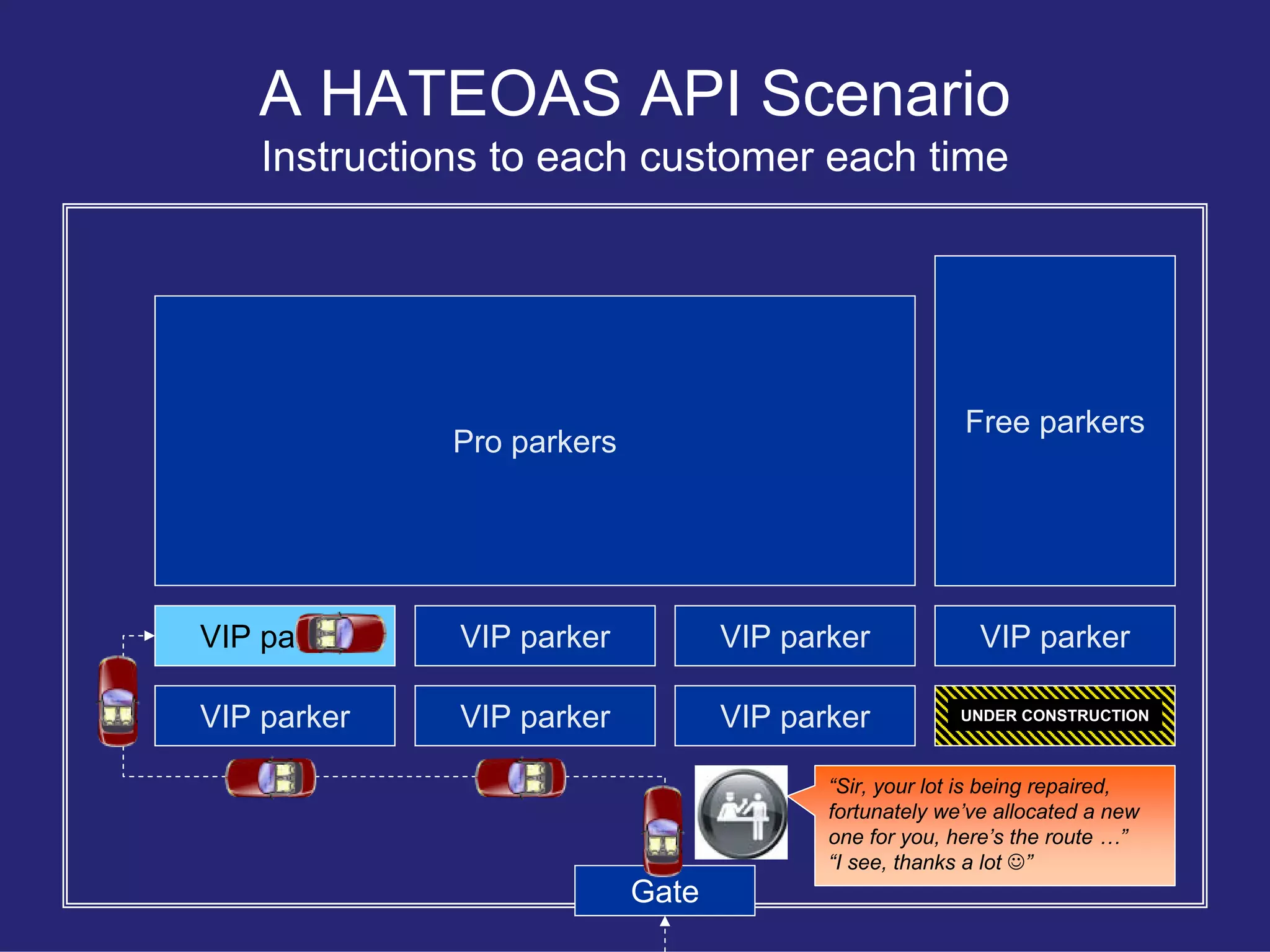
Discusses HATEOAS (Hypermedia as the Engine of Application State) as a REST API constraint introduced by Roy Fielding.
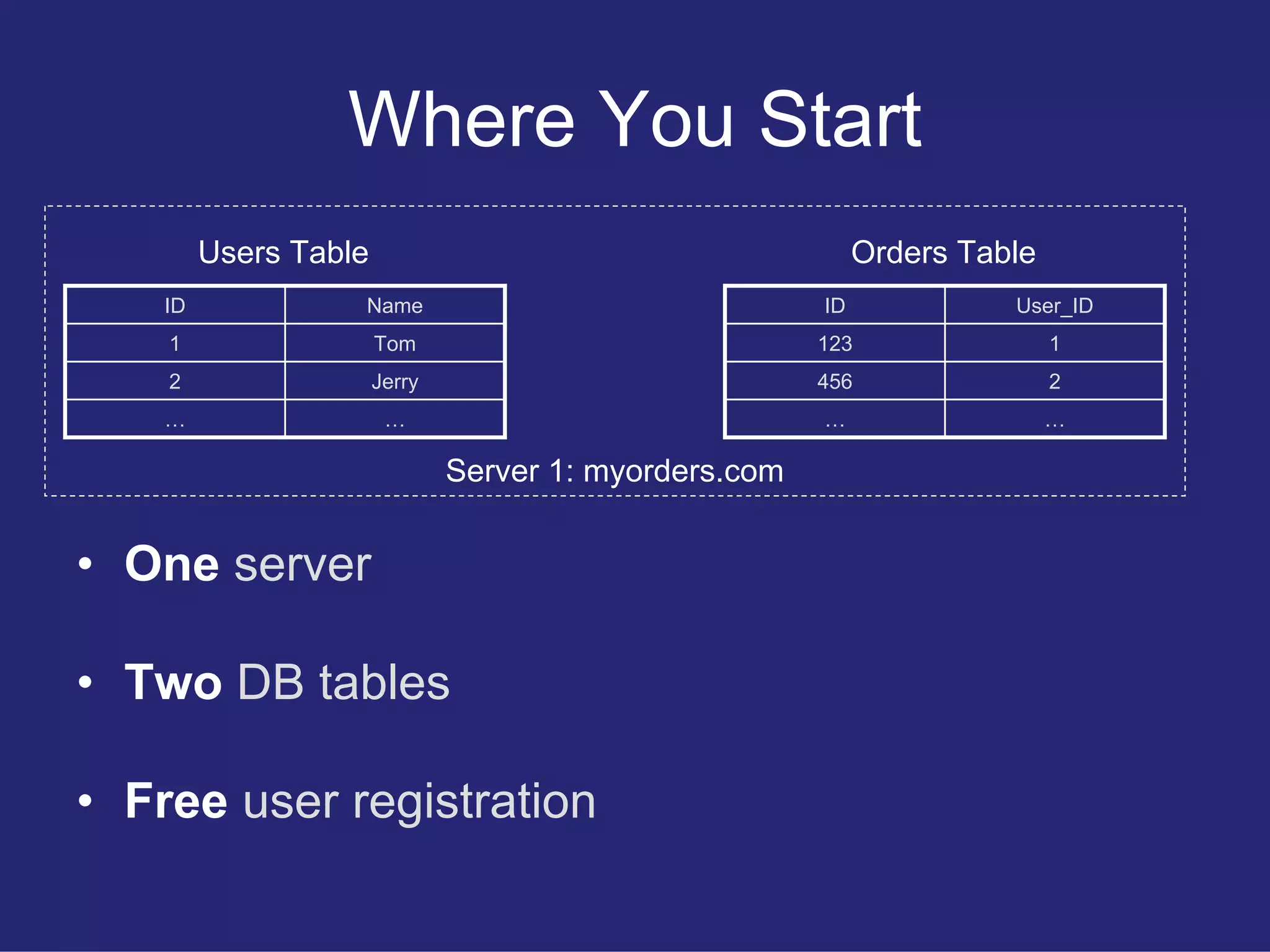
Describes a case study of an online order manager, outlining initial setup with user and order databases, and the first version of REST API for order retrieval.
Illustrates how the API evolved to include explicit user names, maintaining backward compatibility to support old applications.
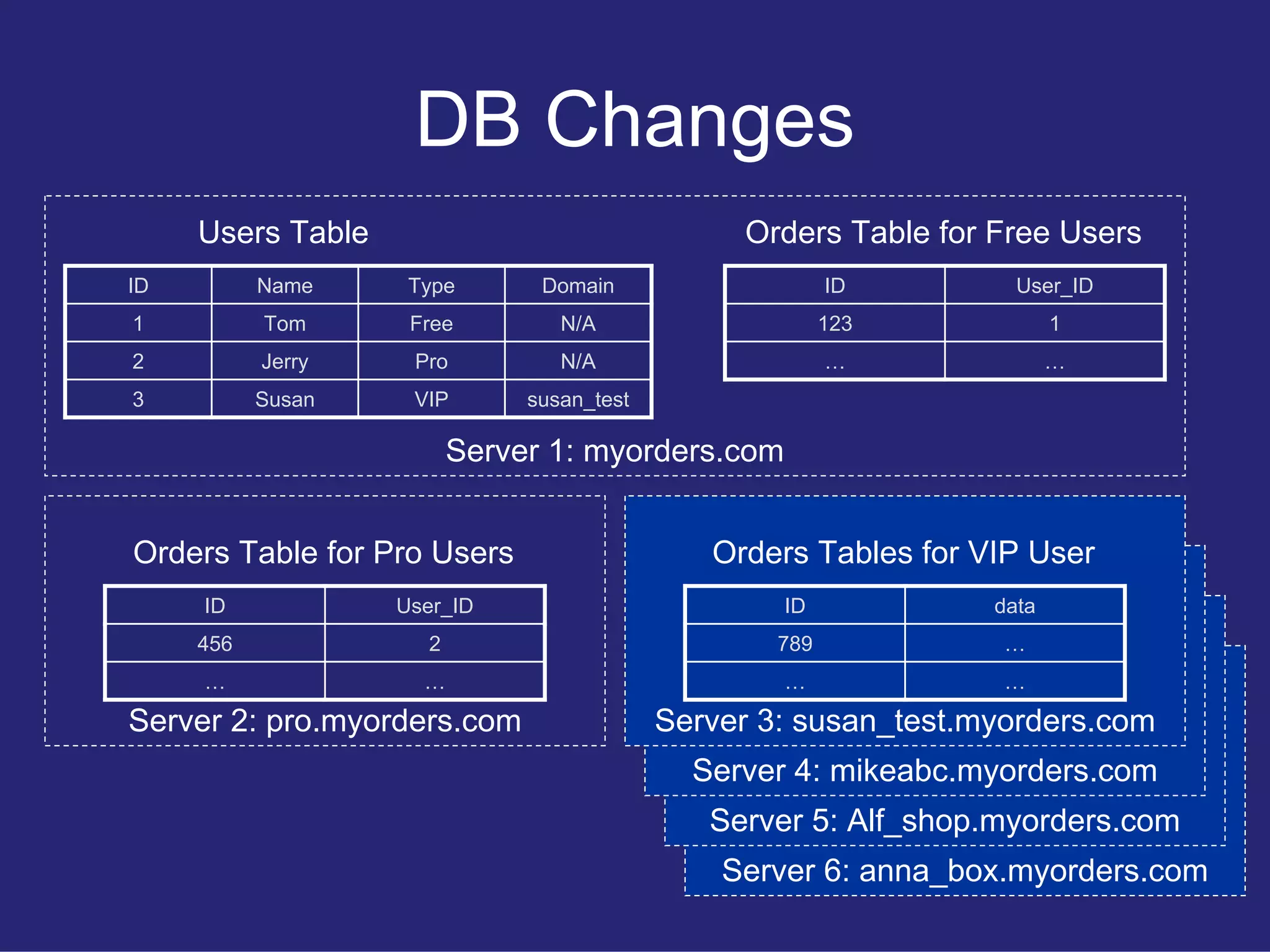
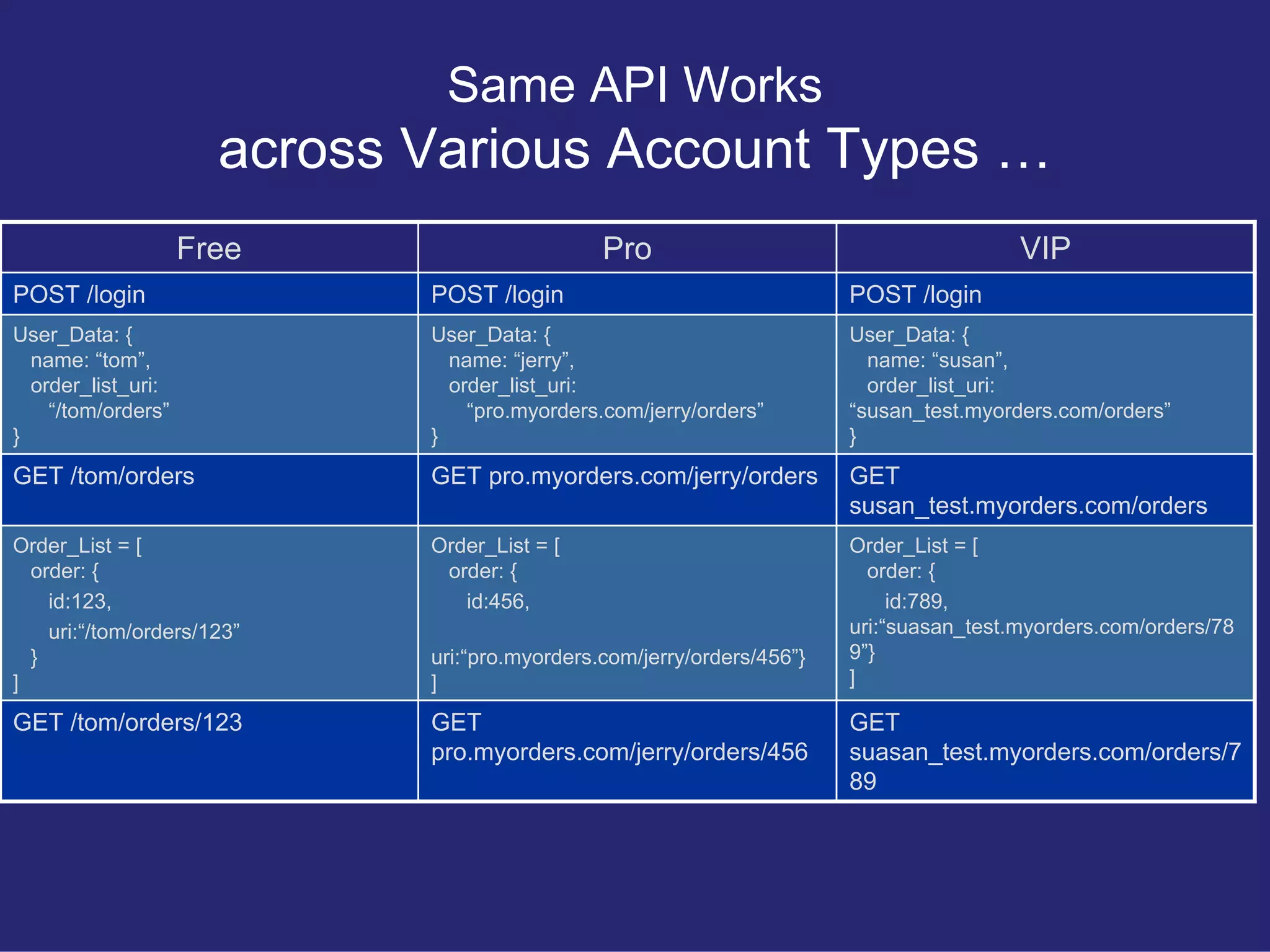
Explains the introduction of different account types (Free, Pro, VIP) in the REST API and the corresponding URI rules for each.
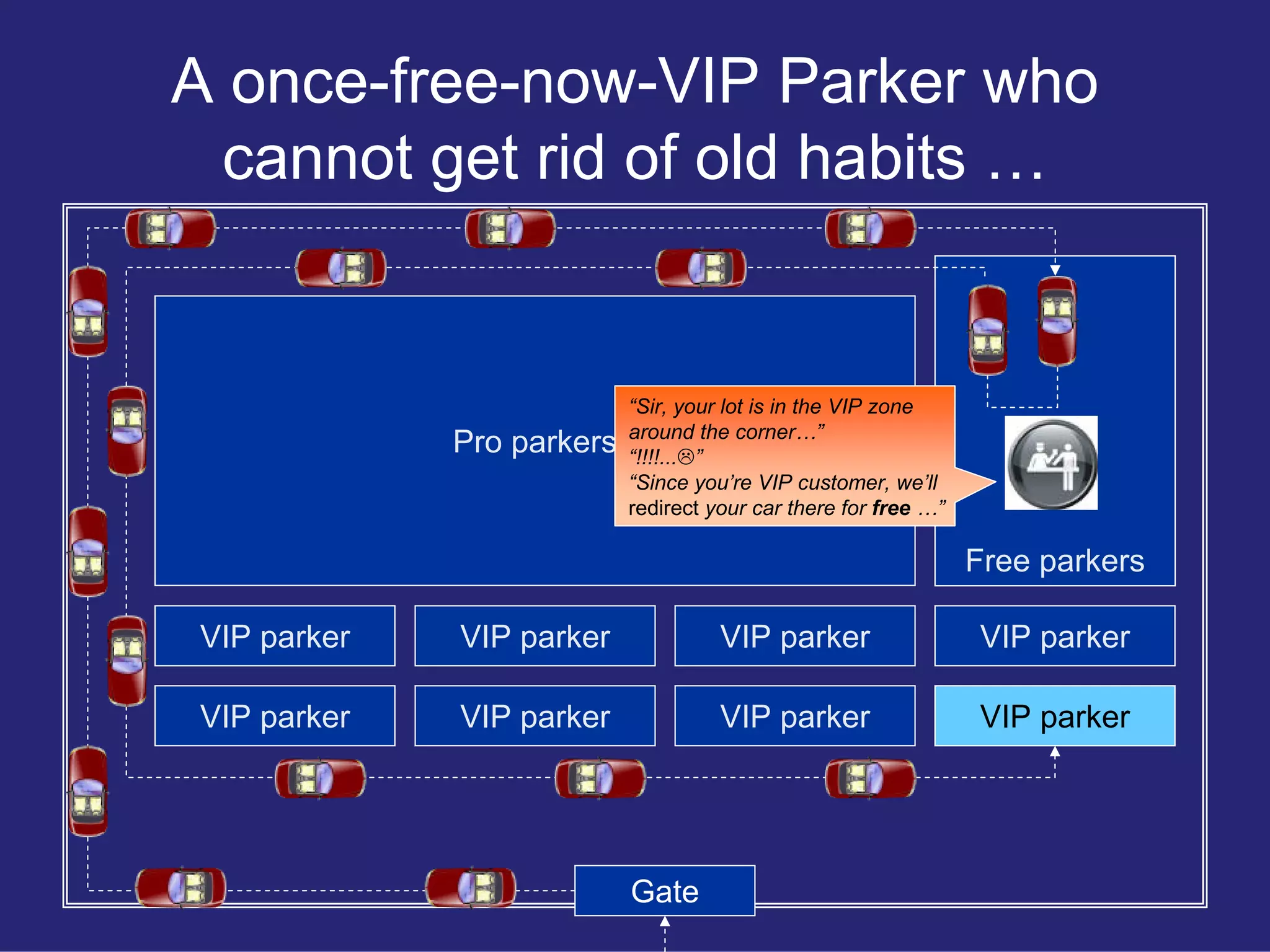
Details the complexities and challenges added to the API due to evolving requirements and functionalities as more user types are introduced.
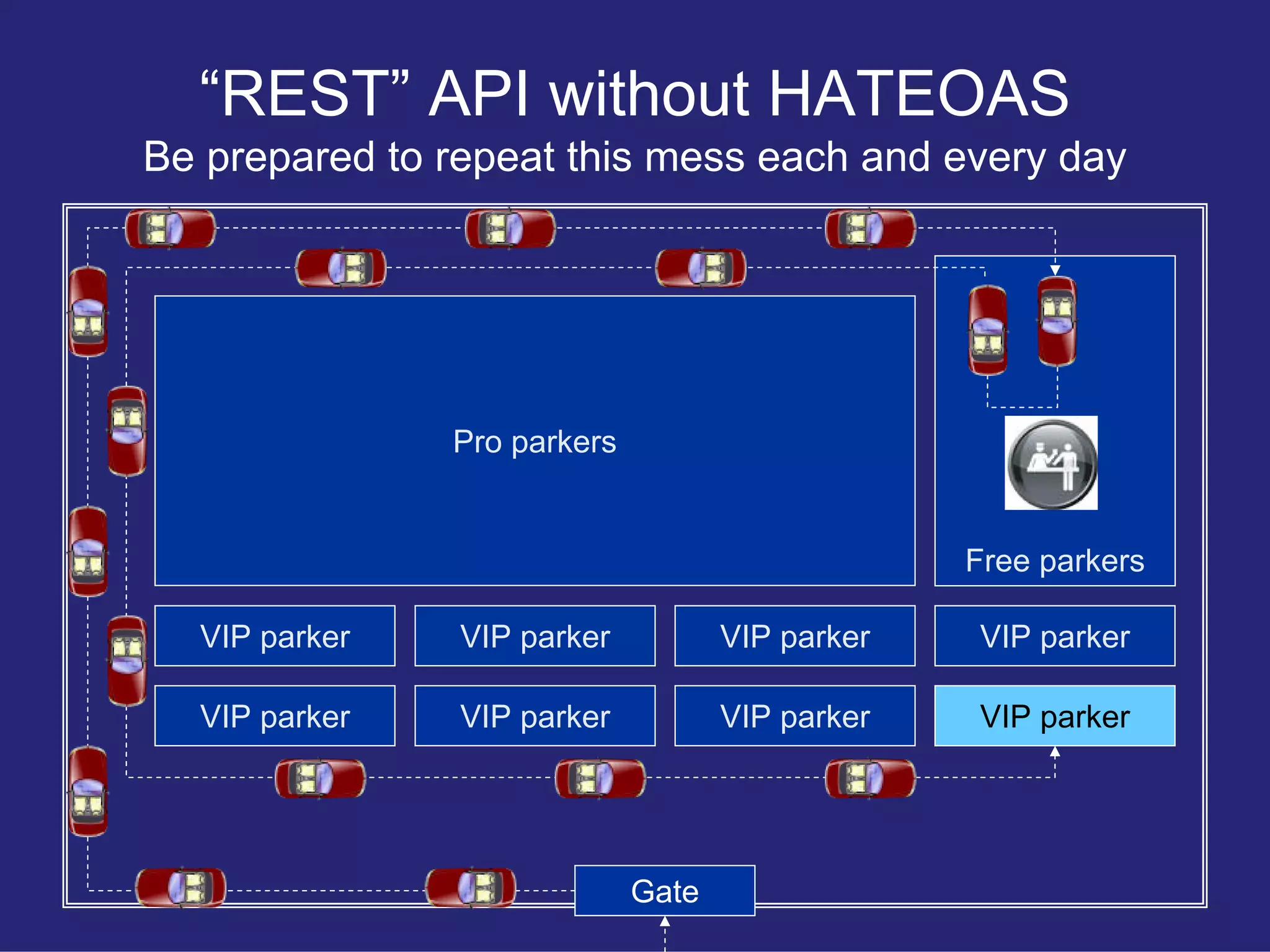
Critiques the initial REST API structure for allowing too many assumptions which lead to tightly coupled systems.
Presents a more robust REST API design that minimizes client assumptions and strengthens API structure across various account types.
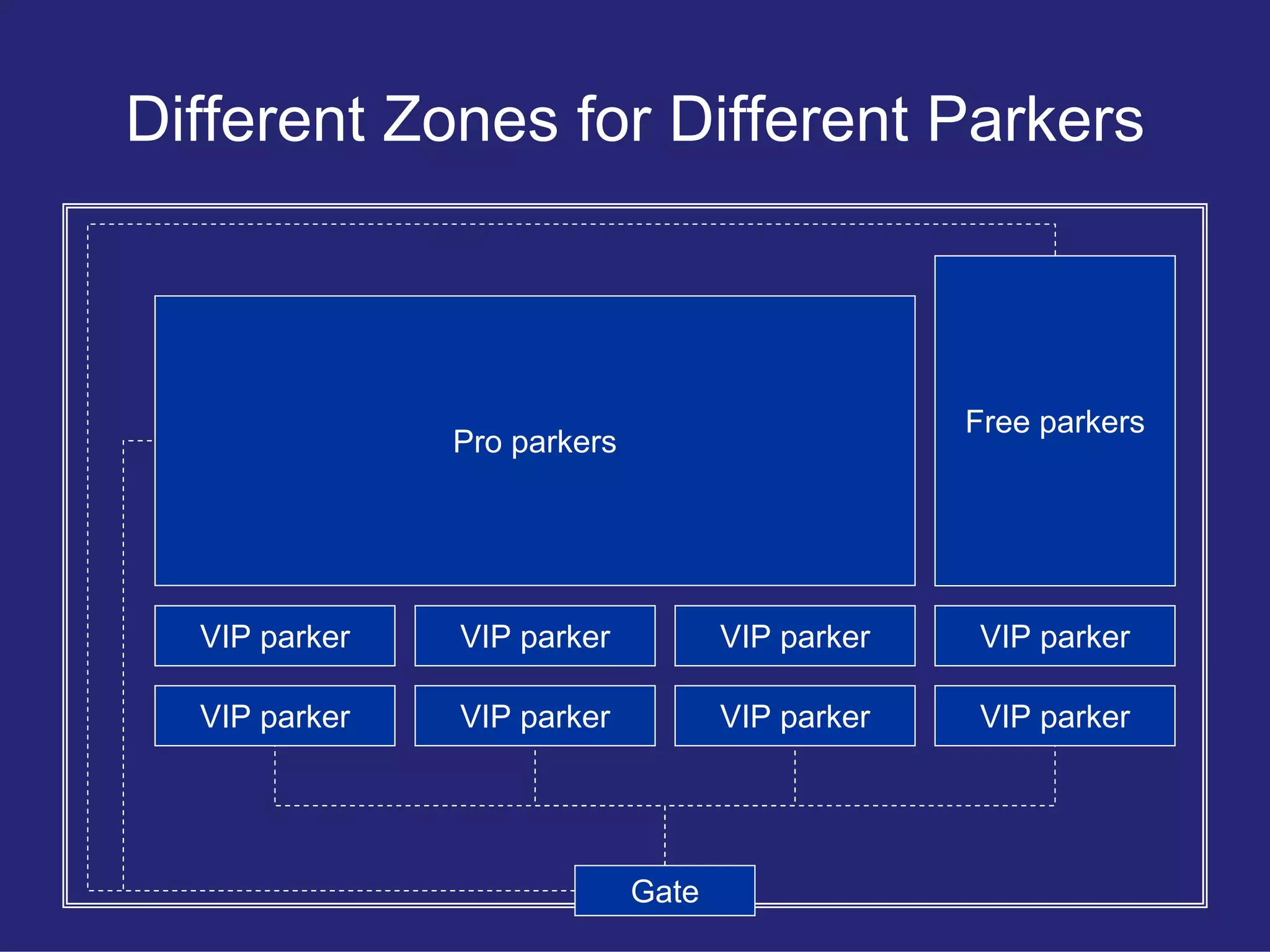
Uses a parking lot analogy to explain the differentiation in user experience for Free, Pro, and VIP account holders in an effective API design.
Contrasts RPC and HATEOAS terms, emphasizing the efficiency of HATEOAS while acknowledging the need for maintenance and support.
Concludes on the importance of HATEOAS for evolving API systems while noting the trade-off with efficiency.






![[오픈소스컨설팅] 쿠버네티스와 쿠버네티스 on 오픈스택 비교 및 구축 방법](https://cdn.slidesharecdn.com/ss_thumbnails/osck8svsk8sonopenstackkhoj-210310051504-thumbnail.jpg?width=640&height=640&fit=bounds)




![[오픈소스컨설팅] Ansible을 활용한 운영 자동화 교육](https://cdn.slidesharecdn.com/ss_thumbnails/ansibleautomationv1-190221013416-thumbnail.jpg?width=640&height=640&fit=bounds)






































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















