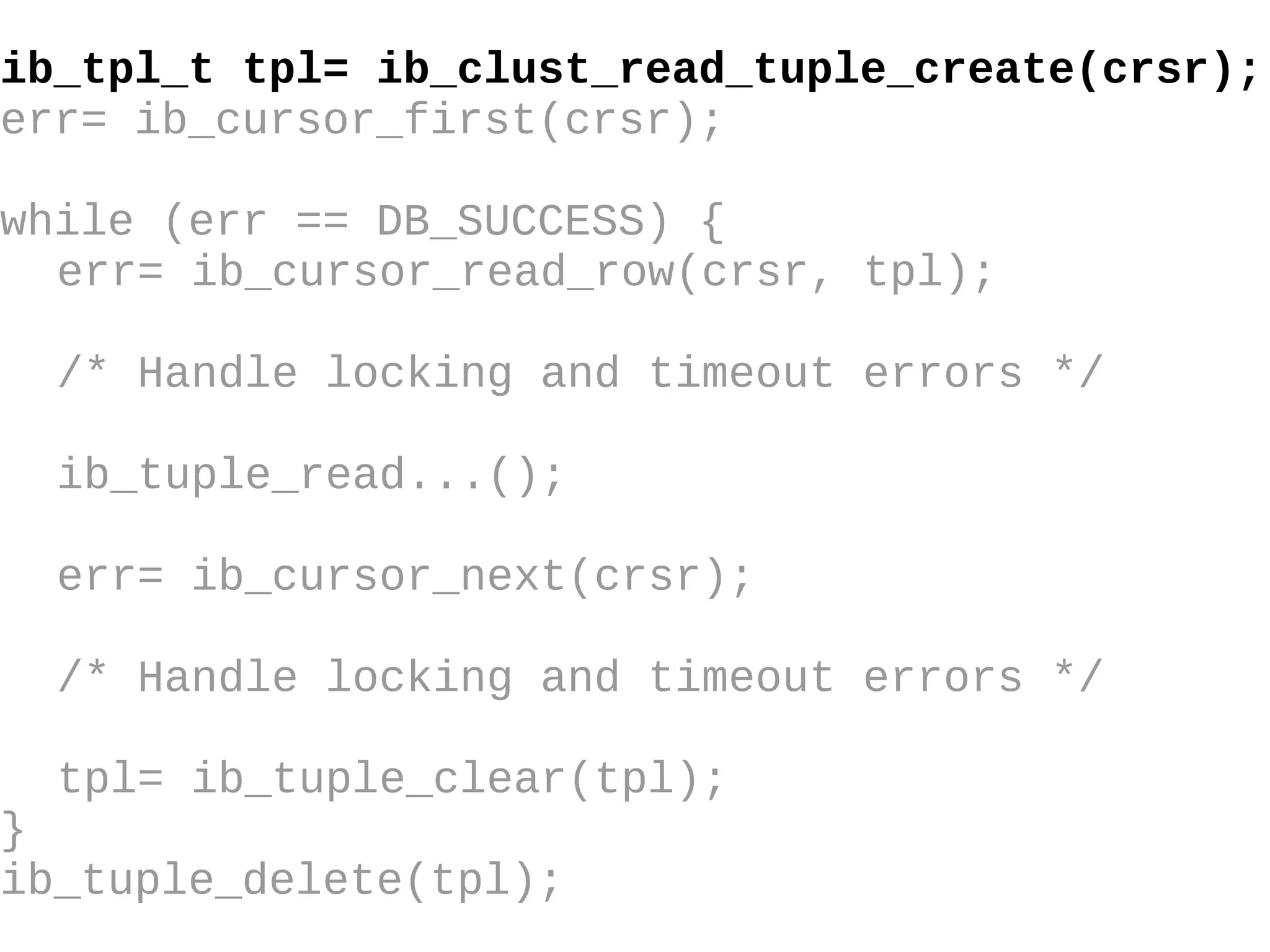
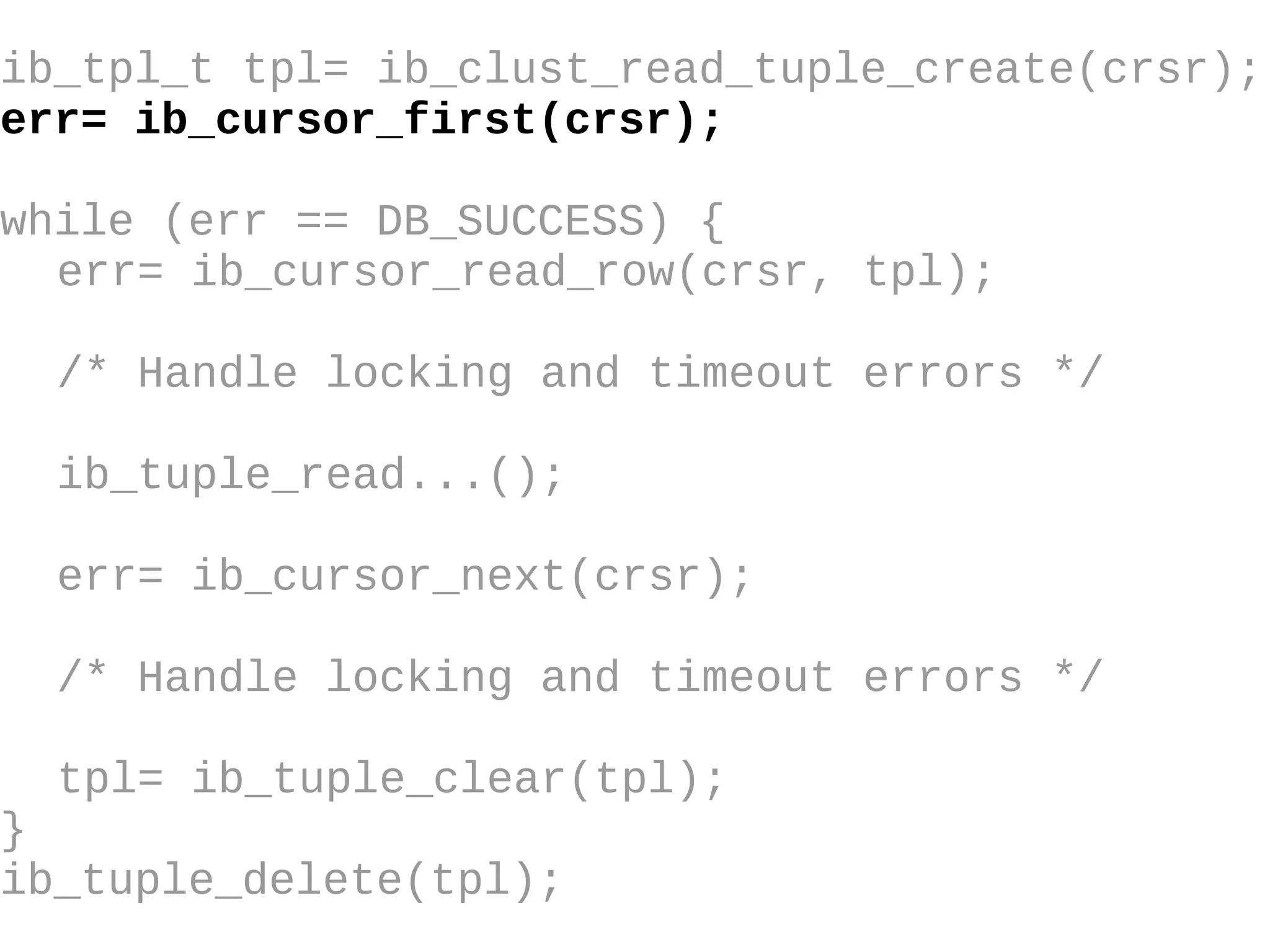
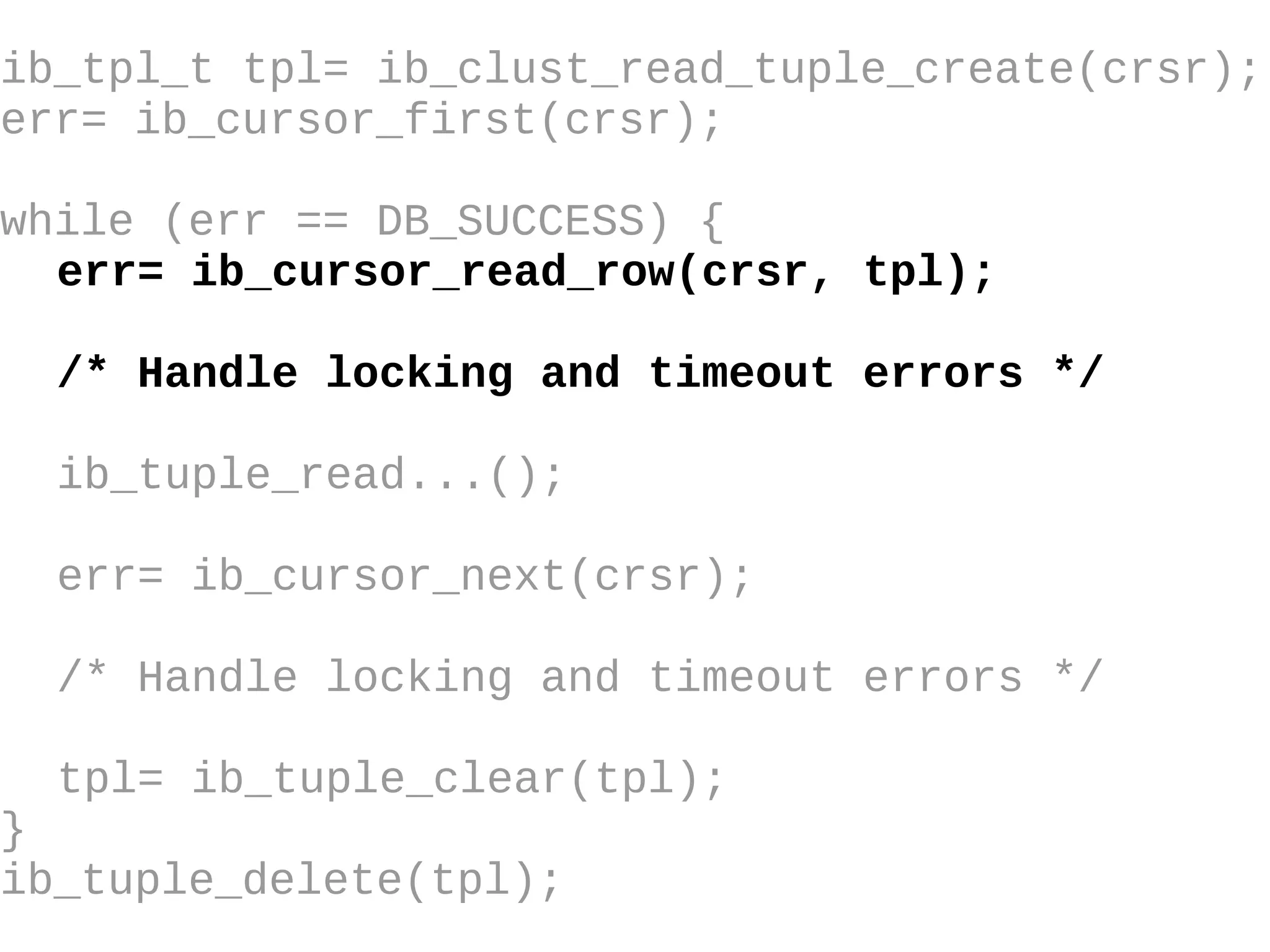
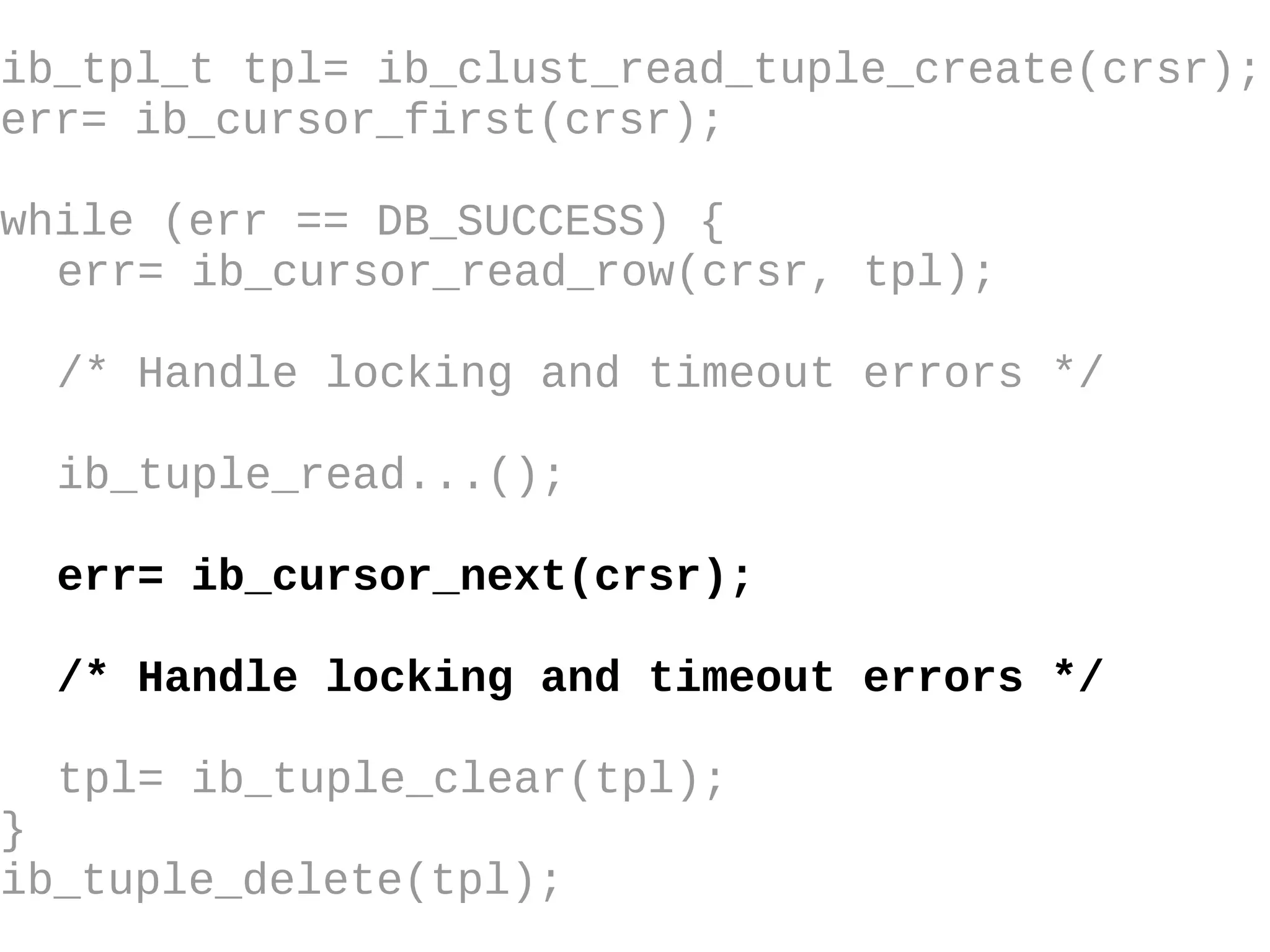
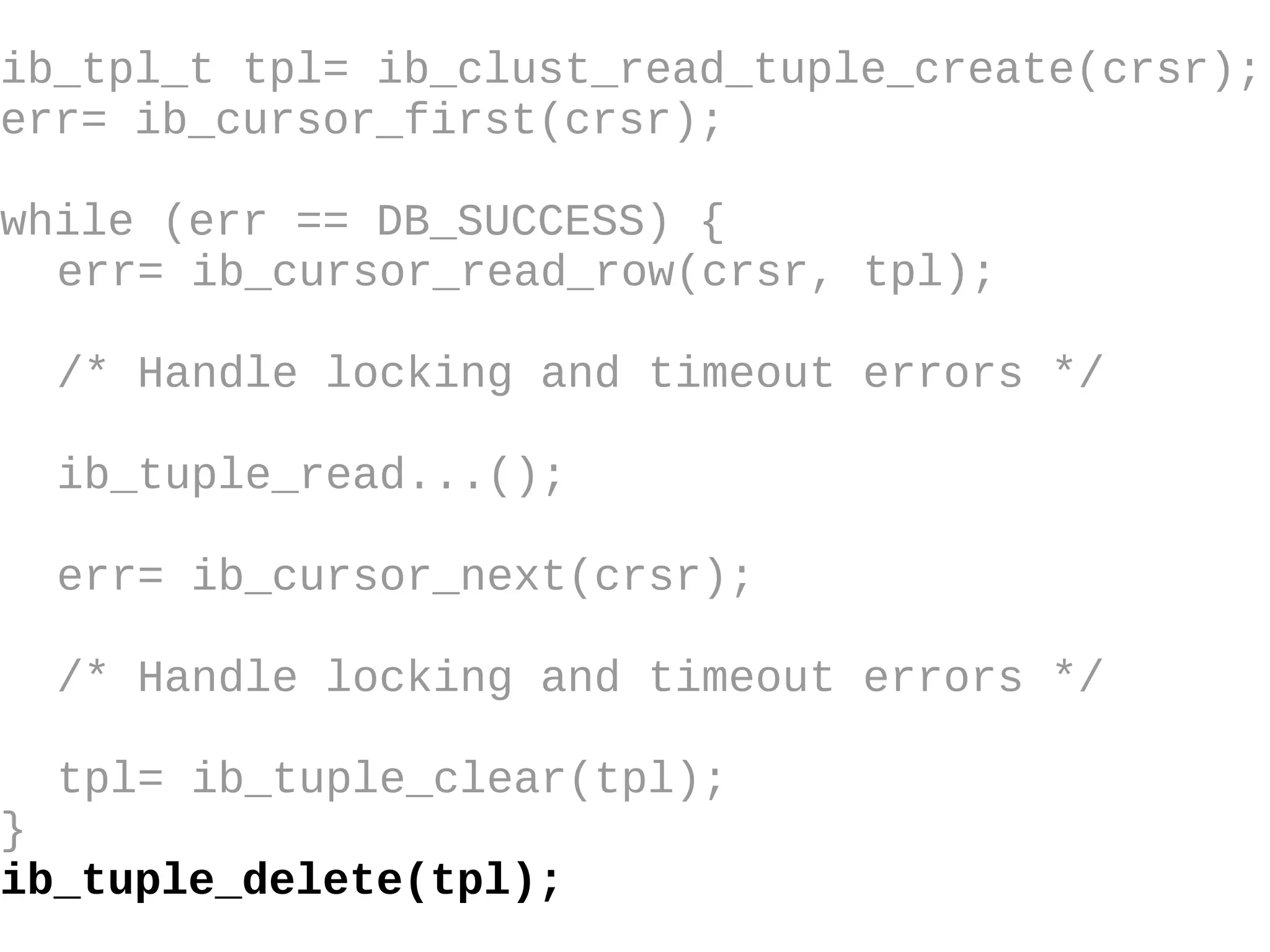
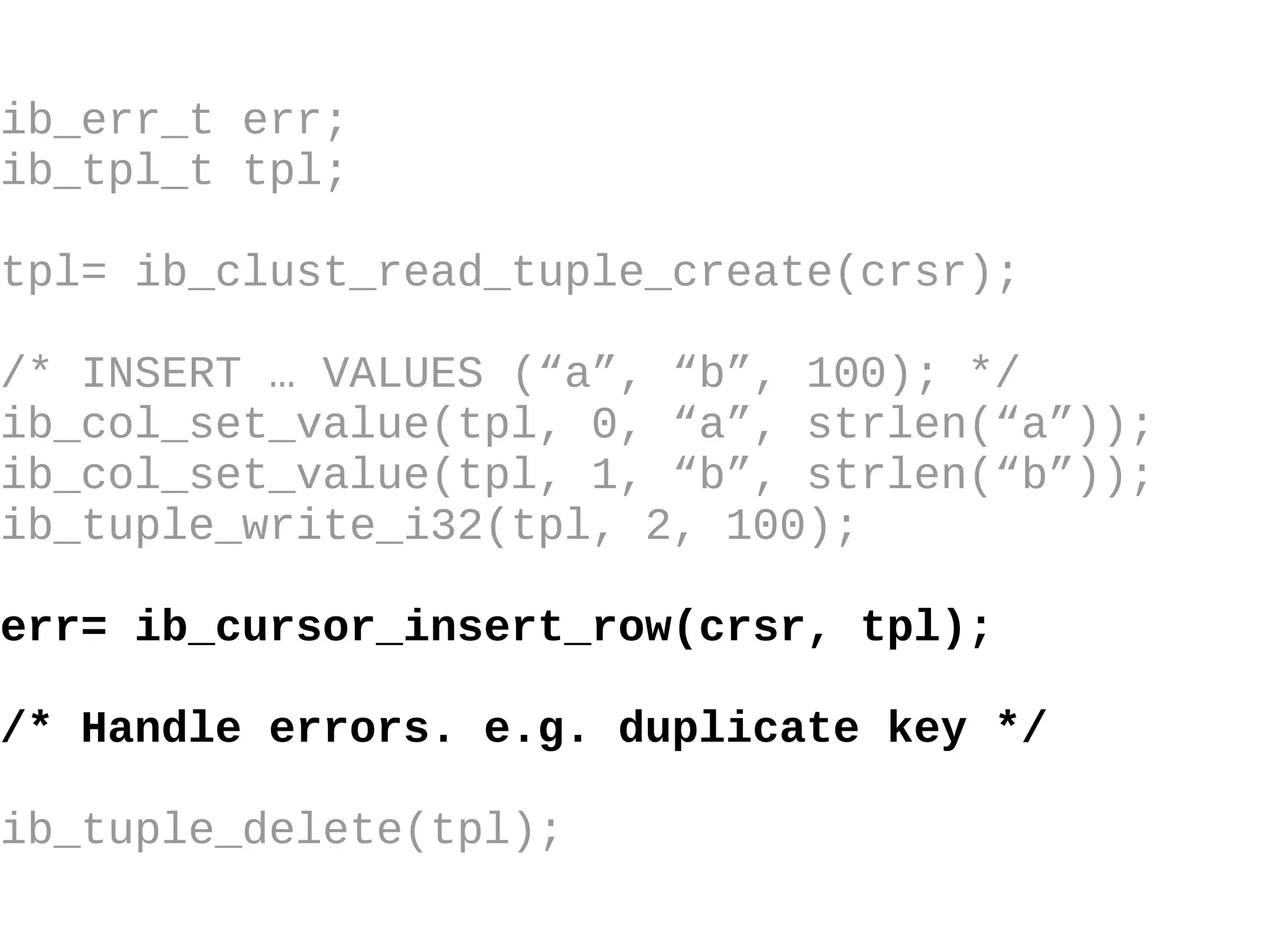
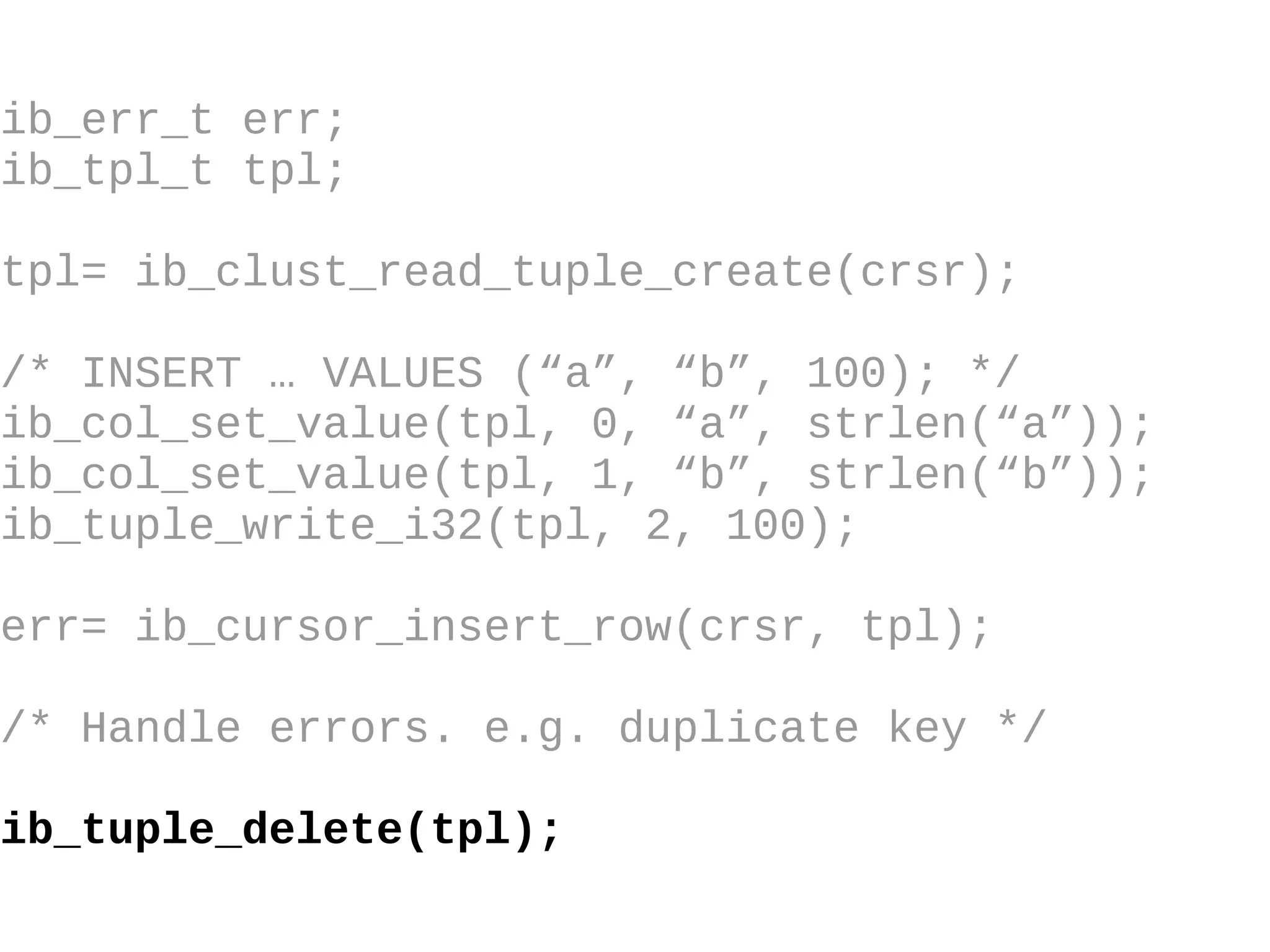
HailDB is an open source project that provides a NoSQL API directly to InnoDB. It exposes the internal InnoDB API through cursor-based functions for transactions, key lookups, index scans, updates, inserts, and deletes. HailDB can be used to build embedded, fast, concurrent relational databases or as the storage engine for SQL databases by using the API instead of SQL. The API provides functions for initialization, configuration, DDL statements, transactions, cursors, tuples, full table scans, inserts, and updates.














































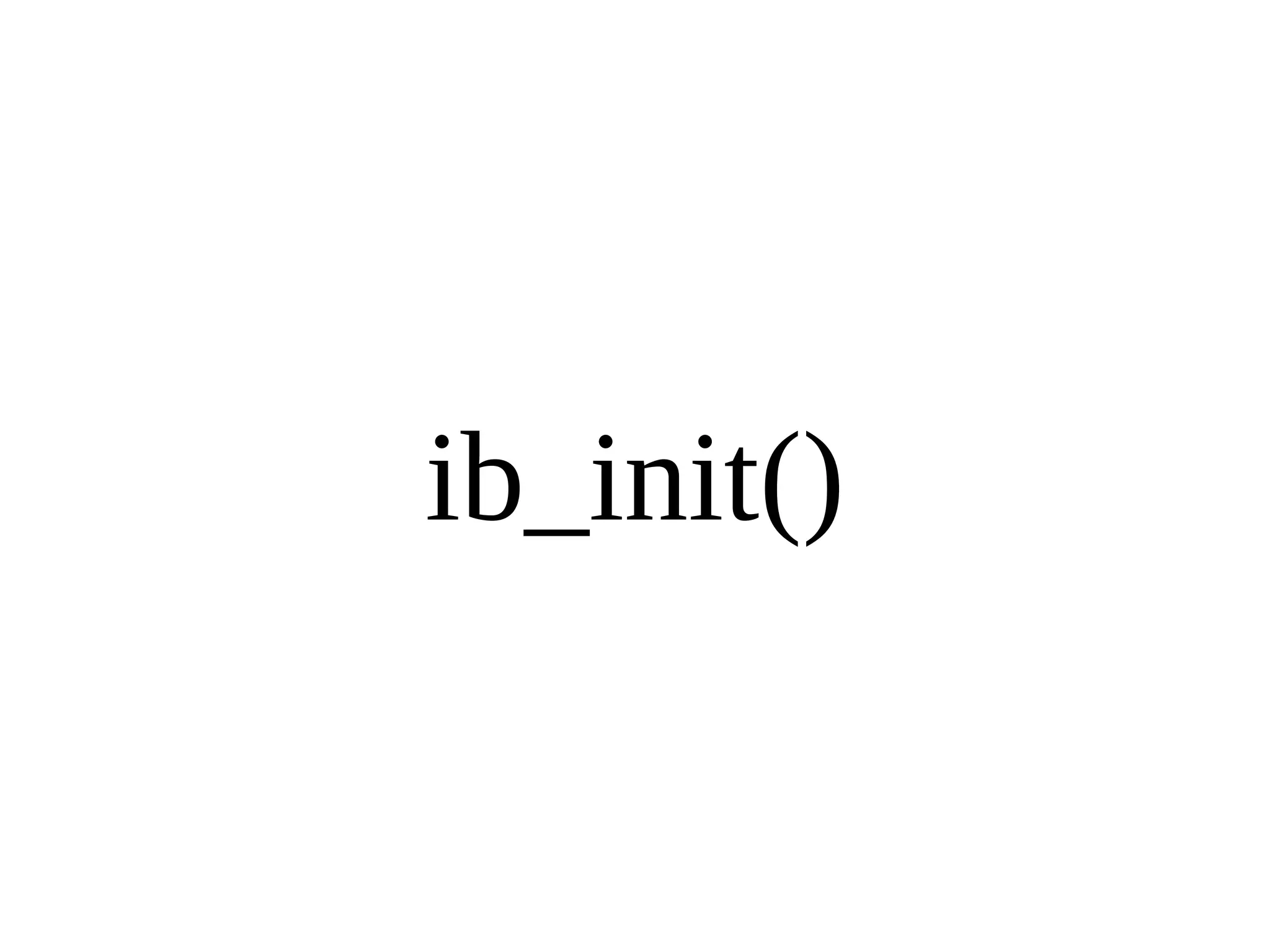
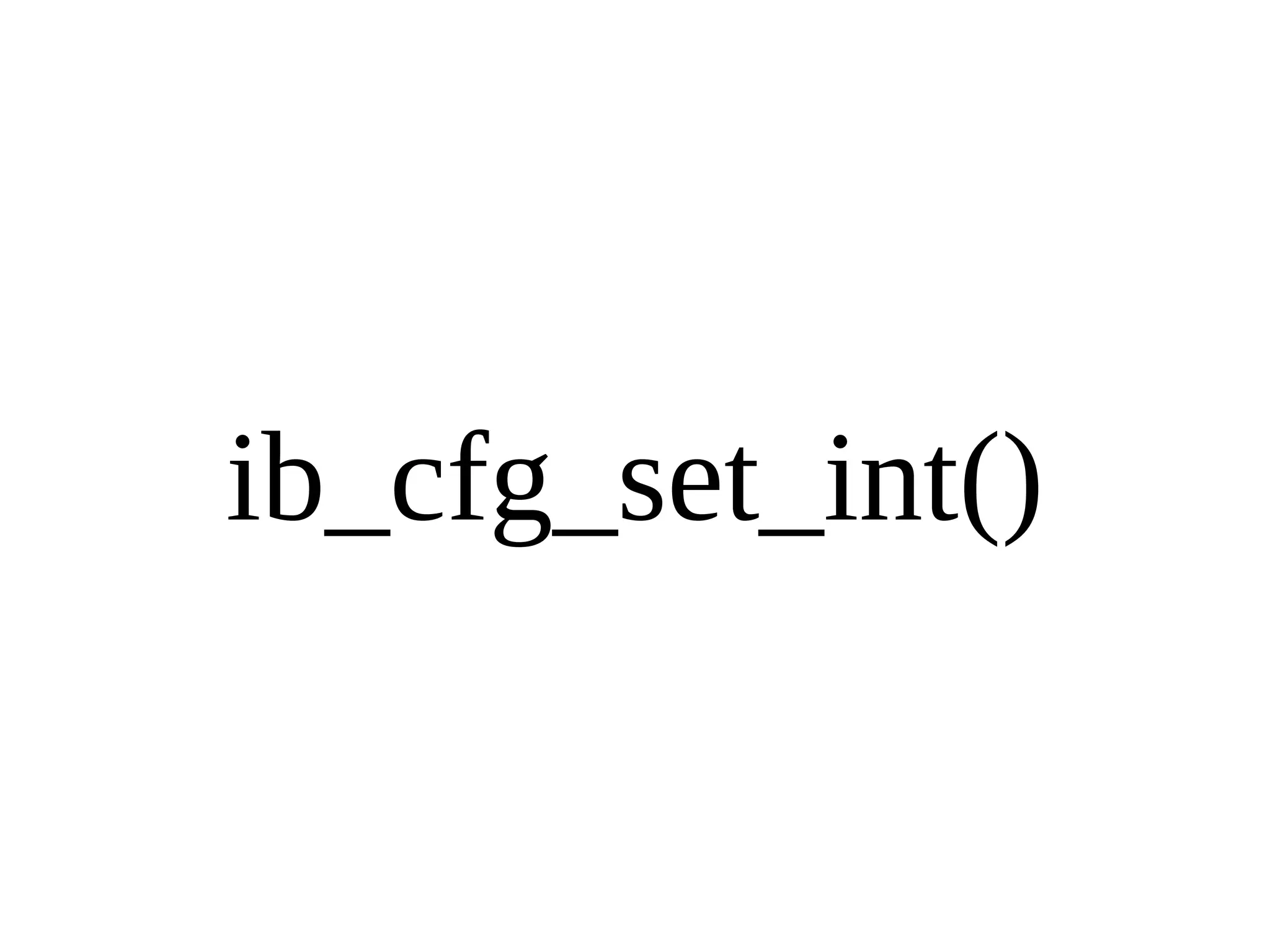
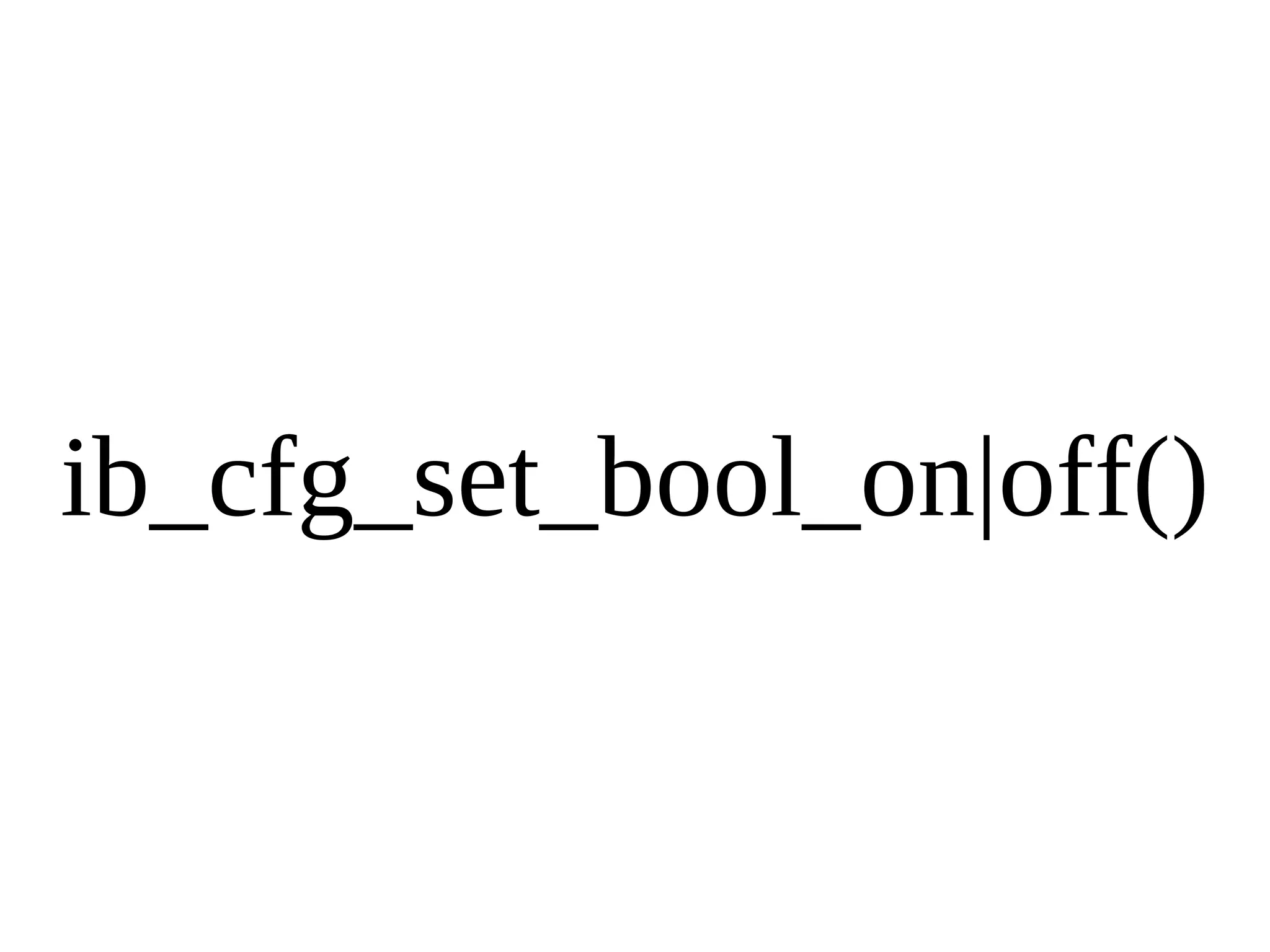
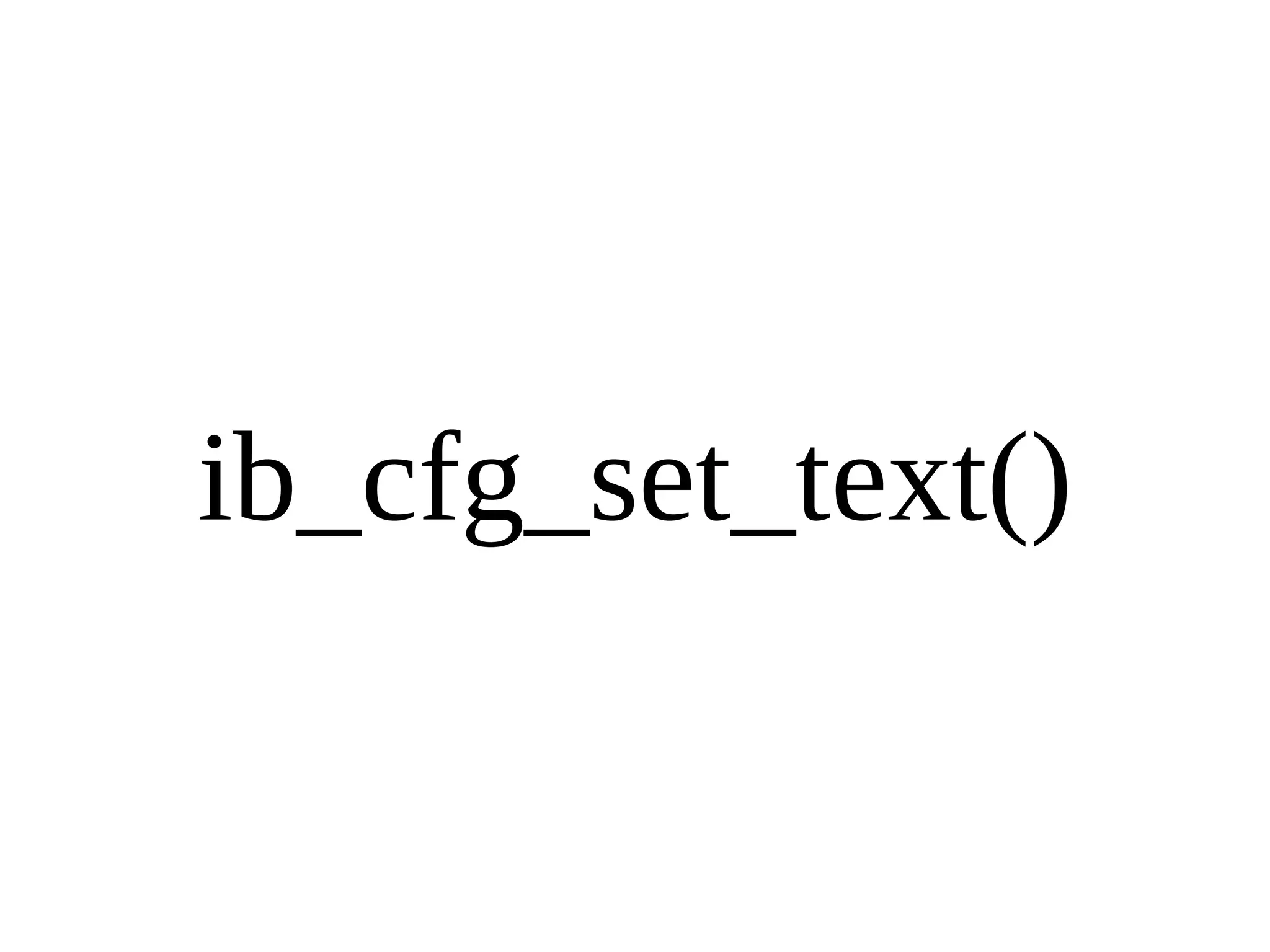





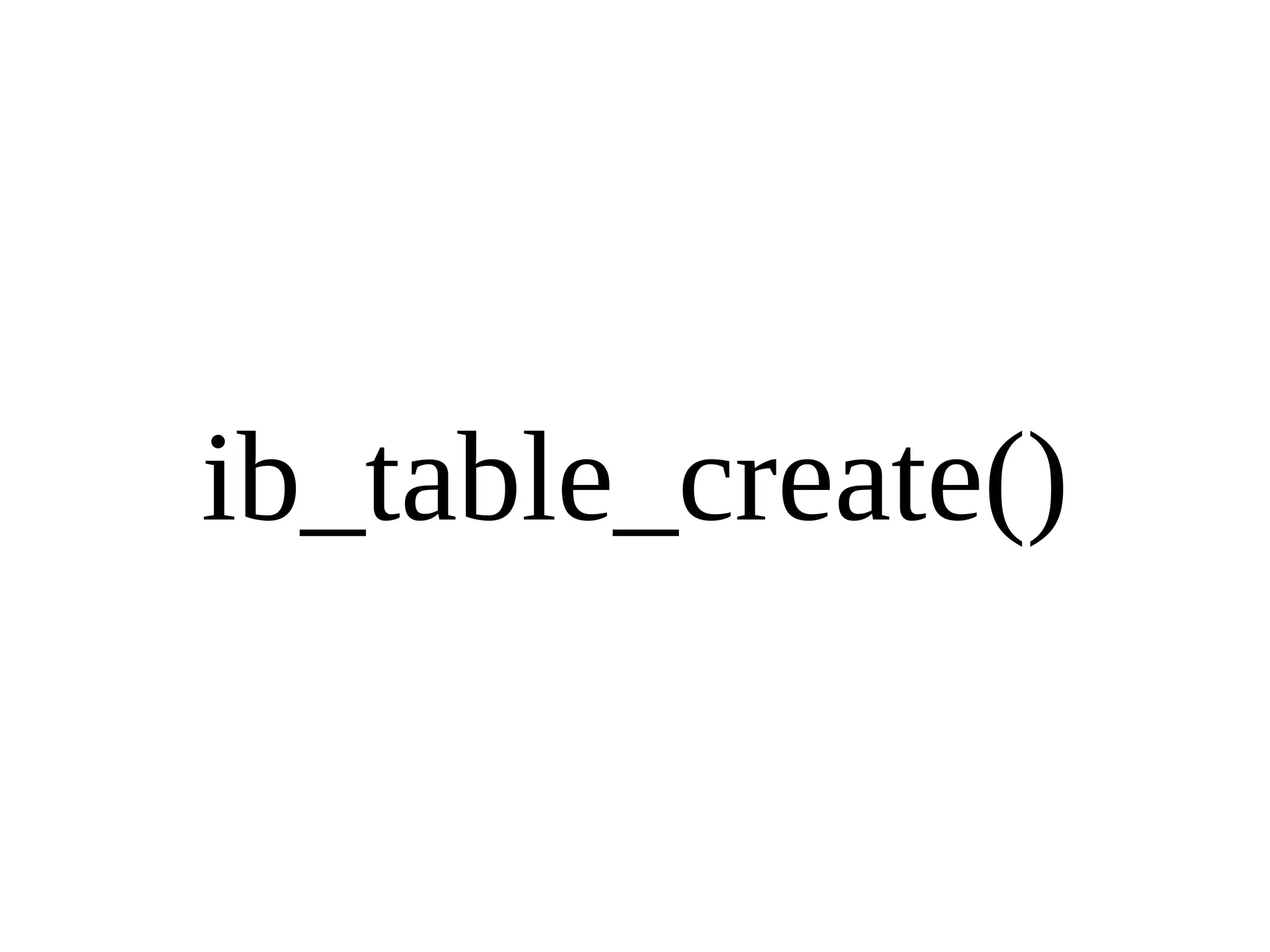
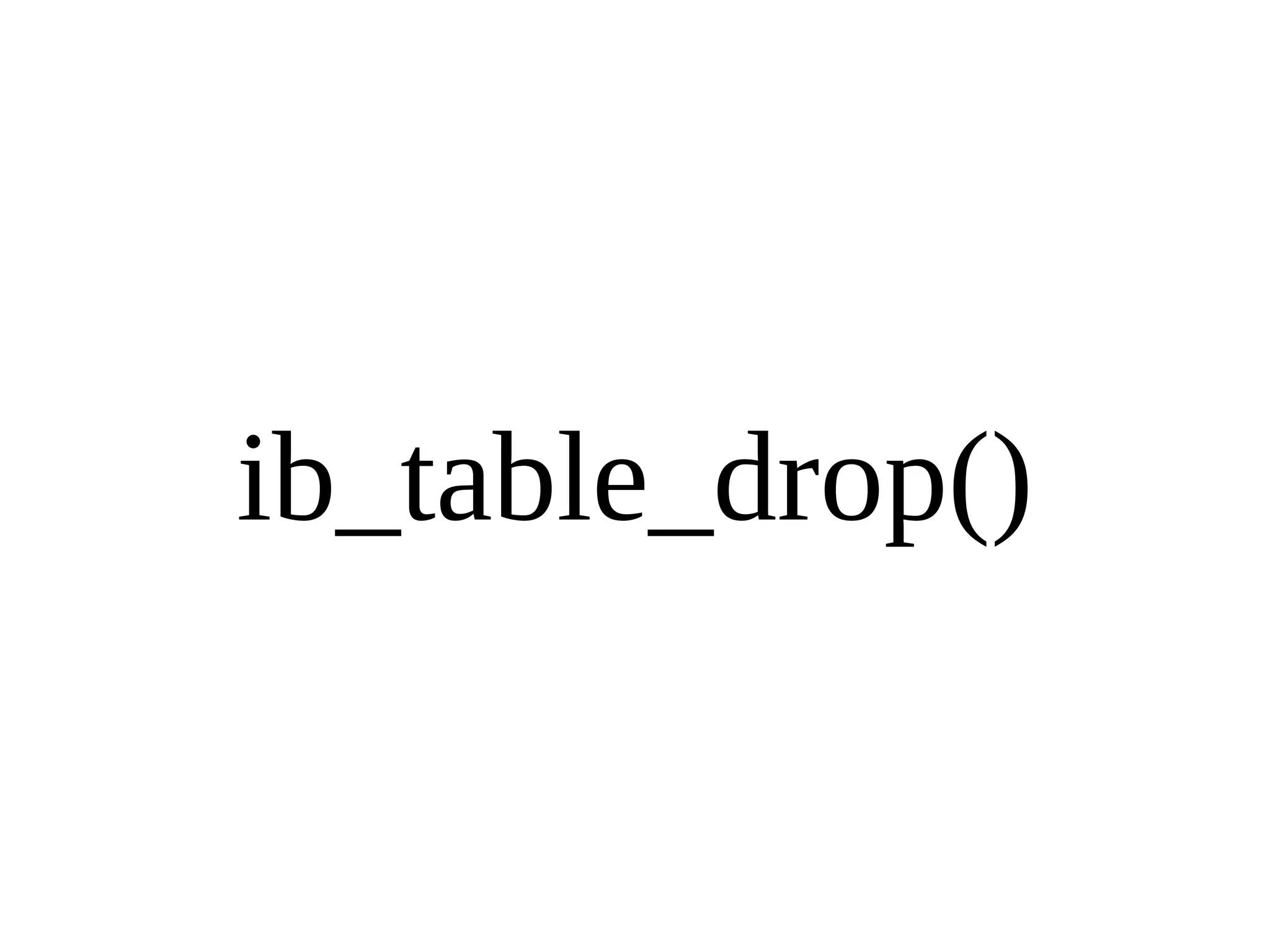


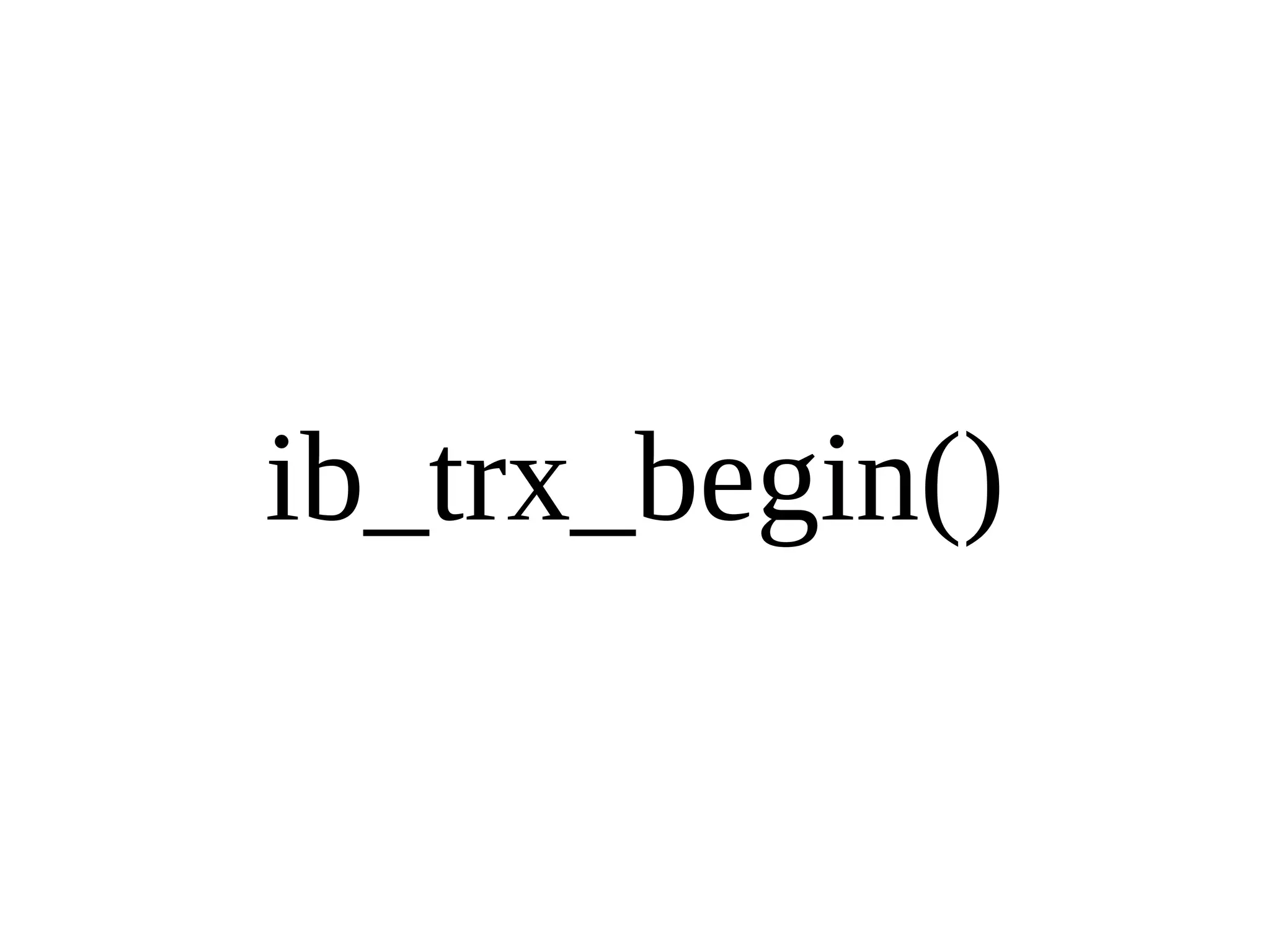
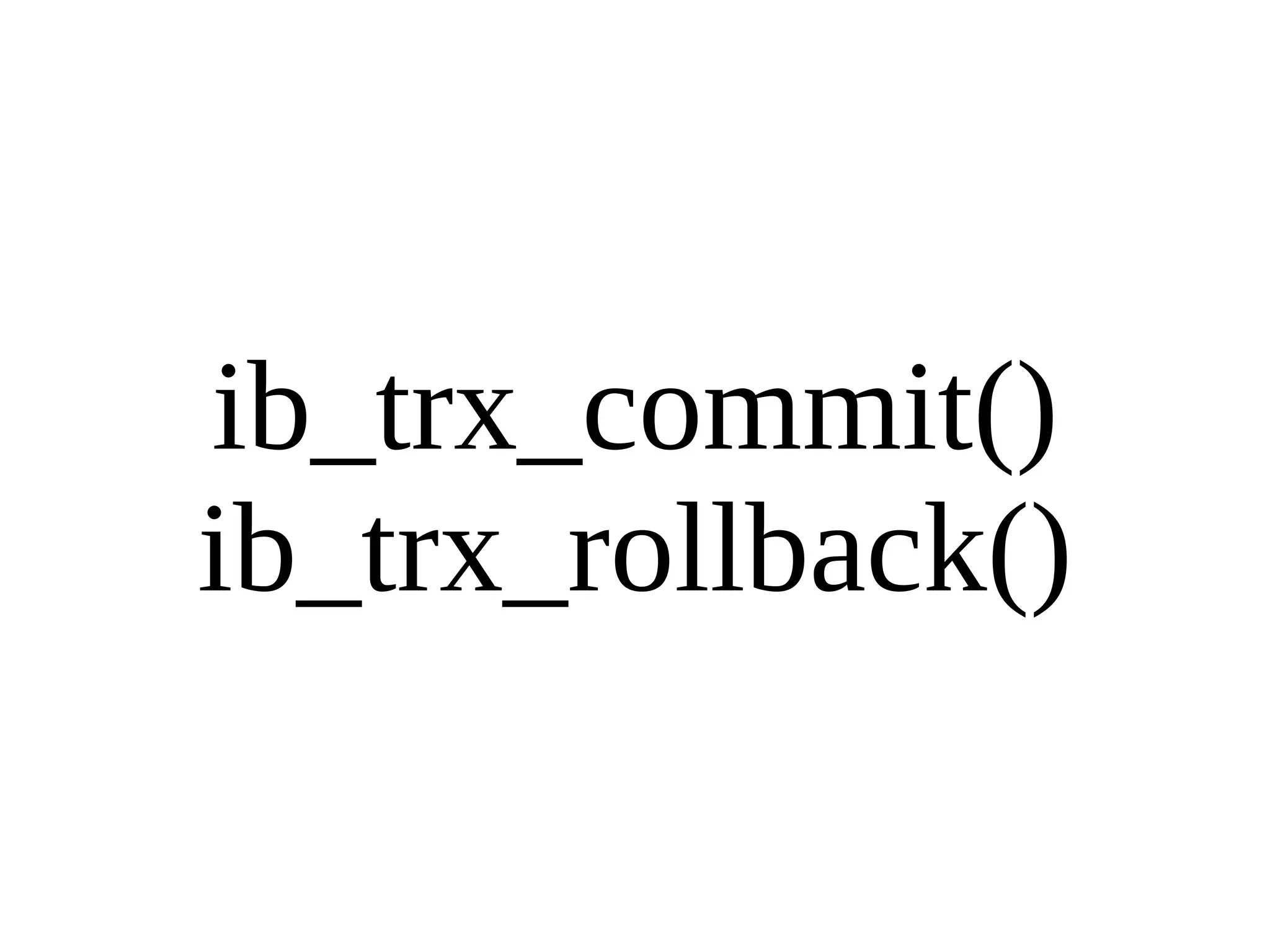









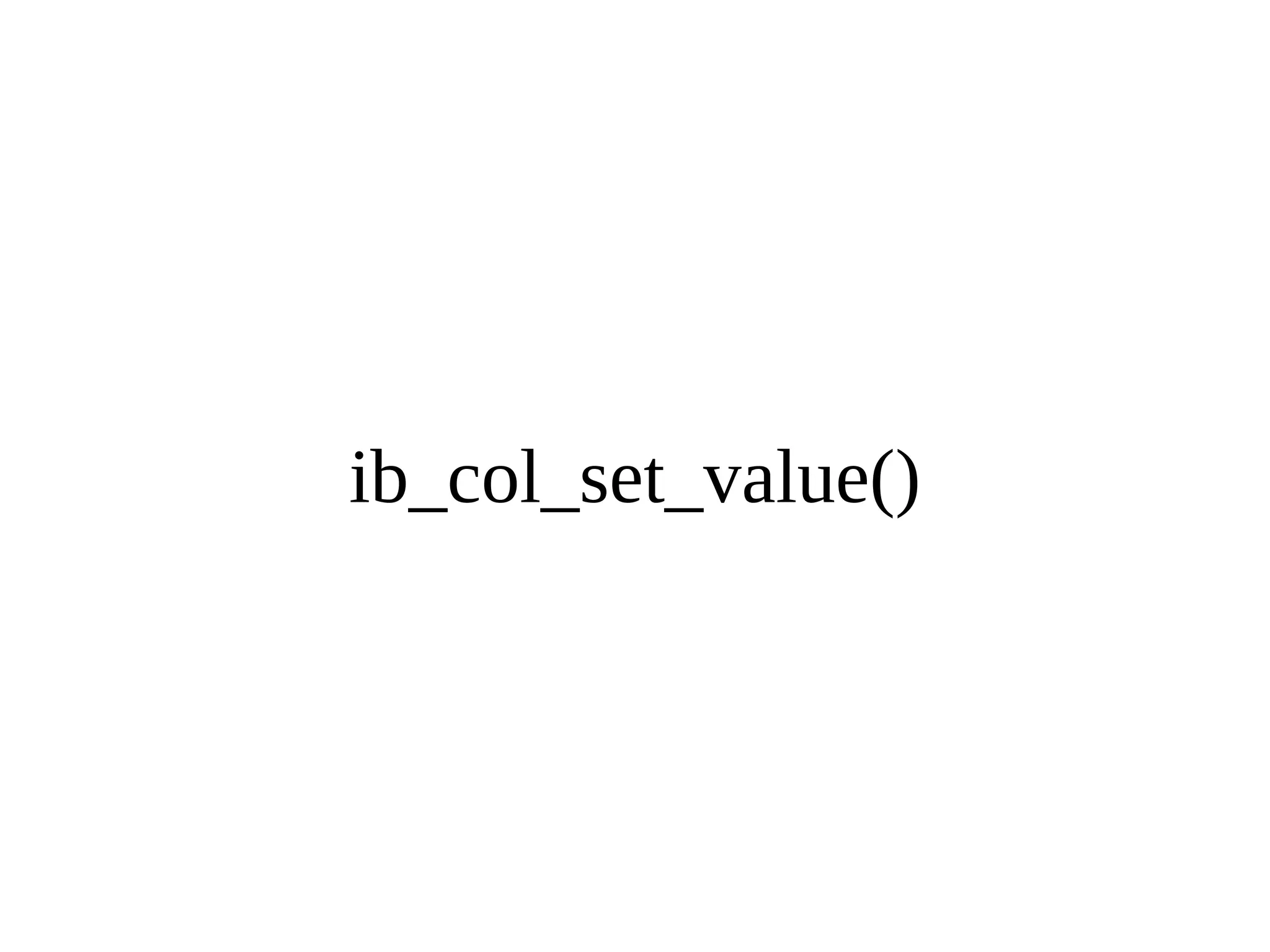
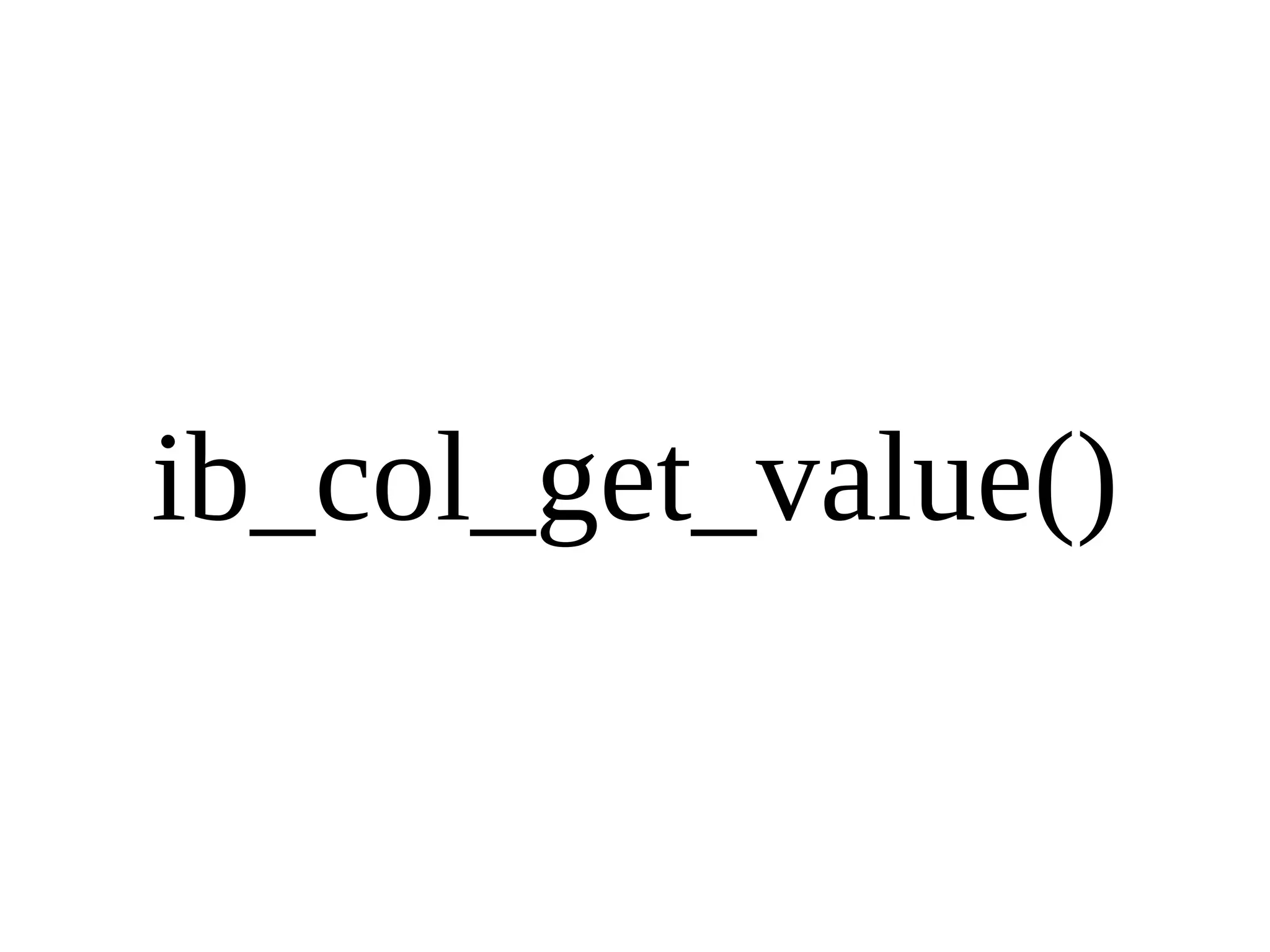





























![Diving into HHVM Extensions (php[tek] 2016)](https://cdn.slidesharecdn.com/ss_thumbnails/160525-divingintohhvmextensionsphptek2016-16x10-160525201430-thumbnail.jpg?width=640&height=640&fit=bounds)





































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















