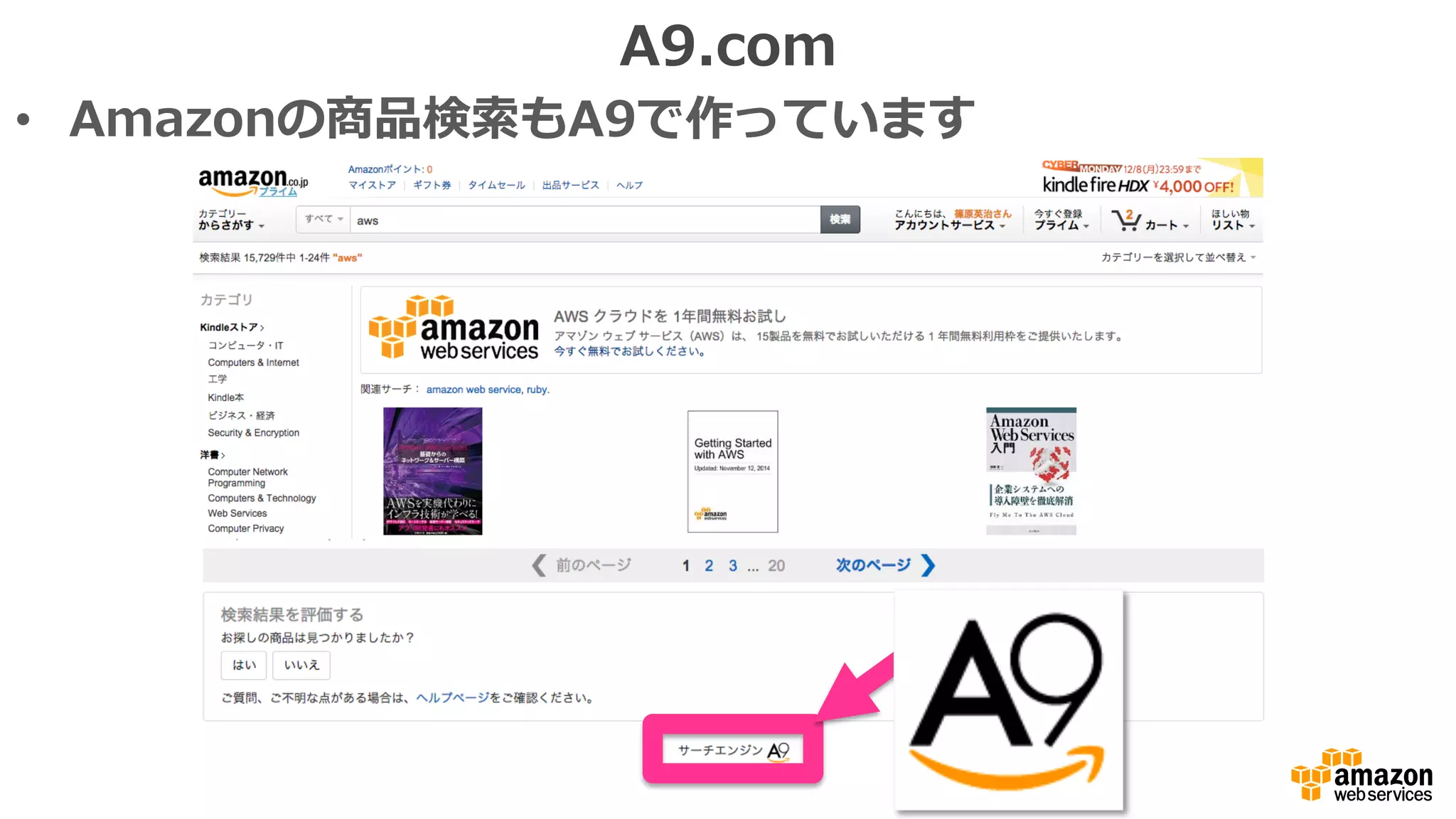
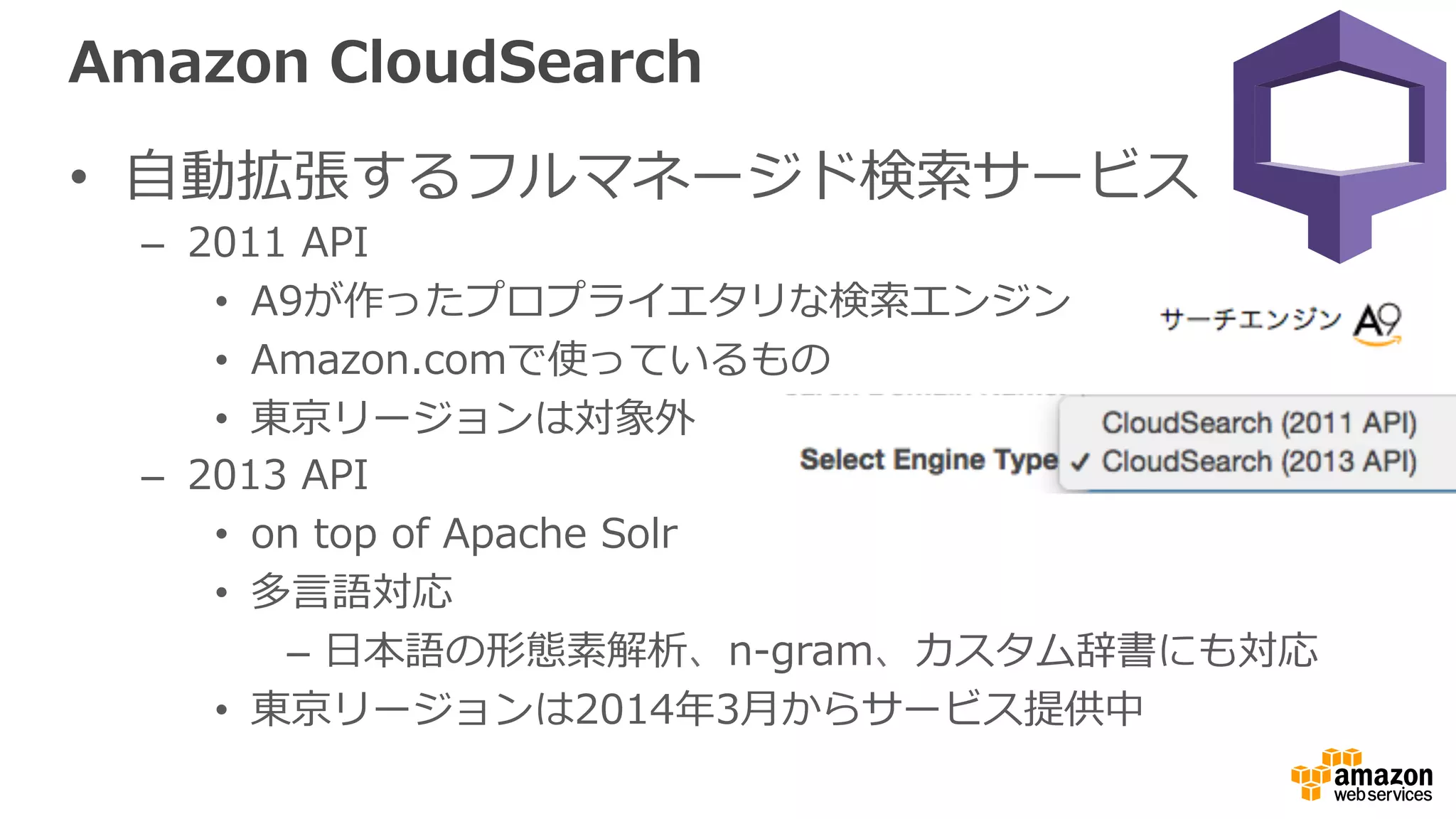
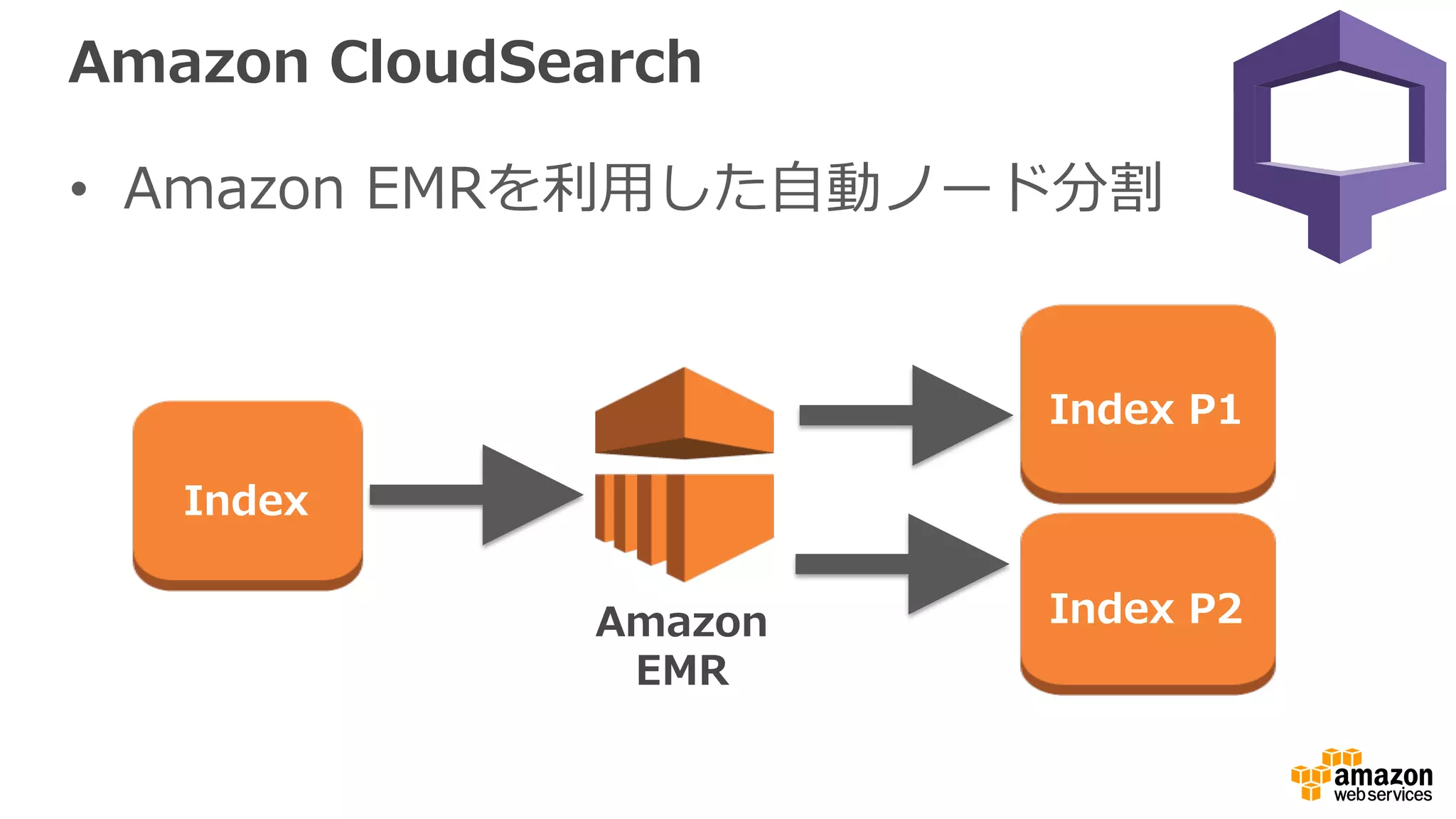
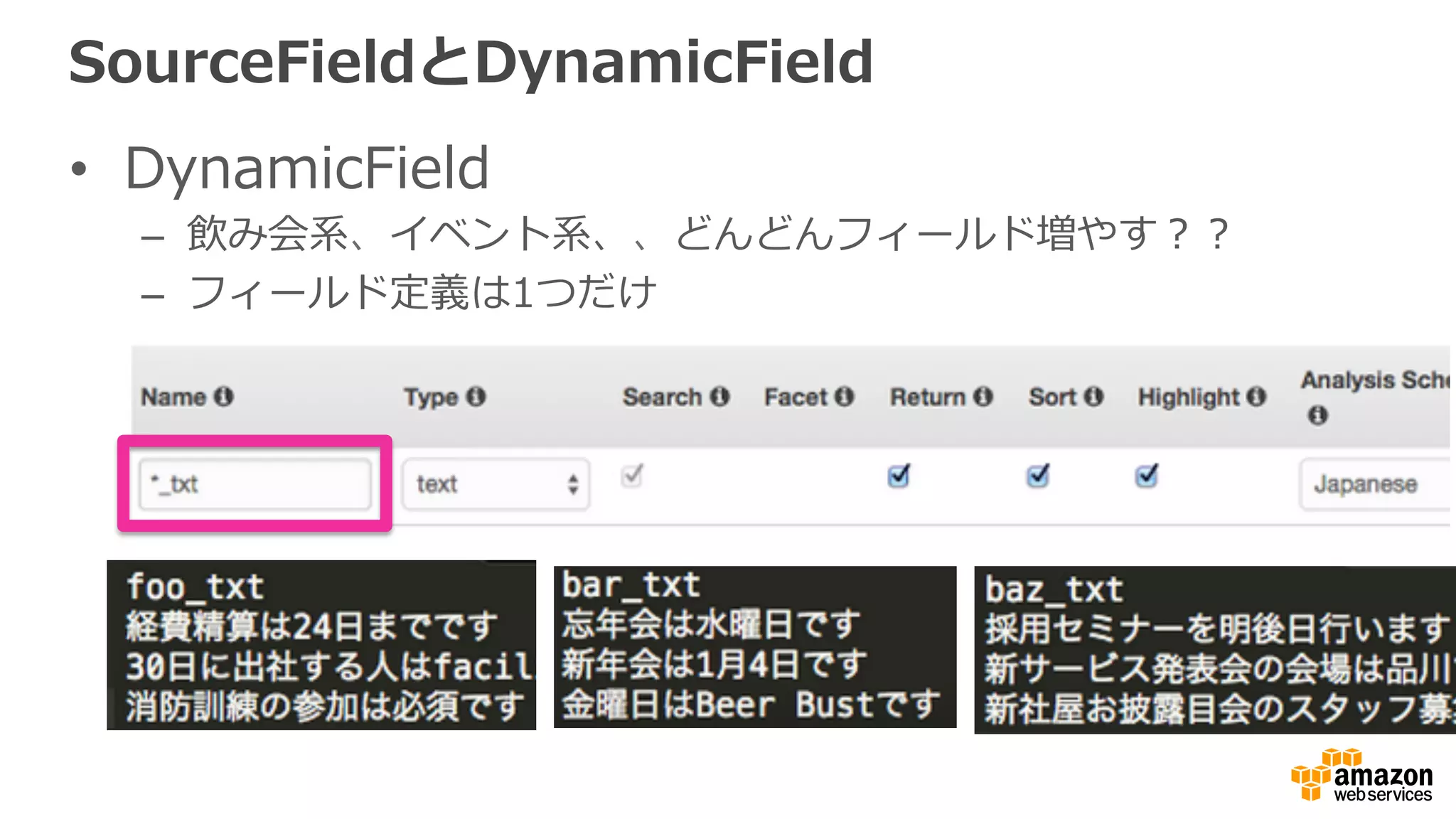
ELK stack
• ELK is Elasticsearch, Logstash, and Kibana
Elasticsearch is a
distributed, schema-‐‑‒
free search and
analytics engine
Logstash is a tool for
collecting and
managing events and
logs.
Kibana is a browser-‐‑‒
based analytics and
search dashboard for
Elasticsearch.


![⾃自⼰己紹介
{
"Name" : "篠原英治",
"Twitter" : "@shinodogg",
"Profile" : {
"Role" : "Solutions Architect",
"Market": "Startup",
"Services" : [
"Amazon CloudSearch",
"Amazon Elasticsearch Service",
"Amazon Simple Workflow Service”,
"AWS Elastic Beanstalk”
]
}
}
New ☺](https://image.slidesharecdn.com/awssearchservices-151211024211/75/AWS-Search-Services-2-2048.jpg)






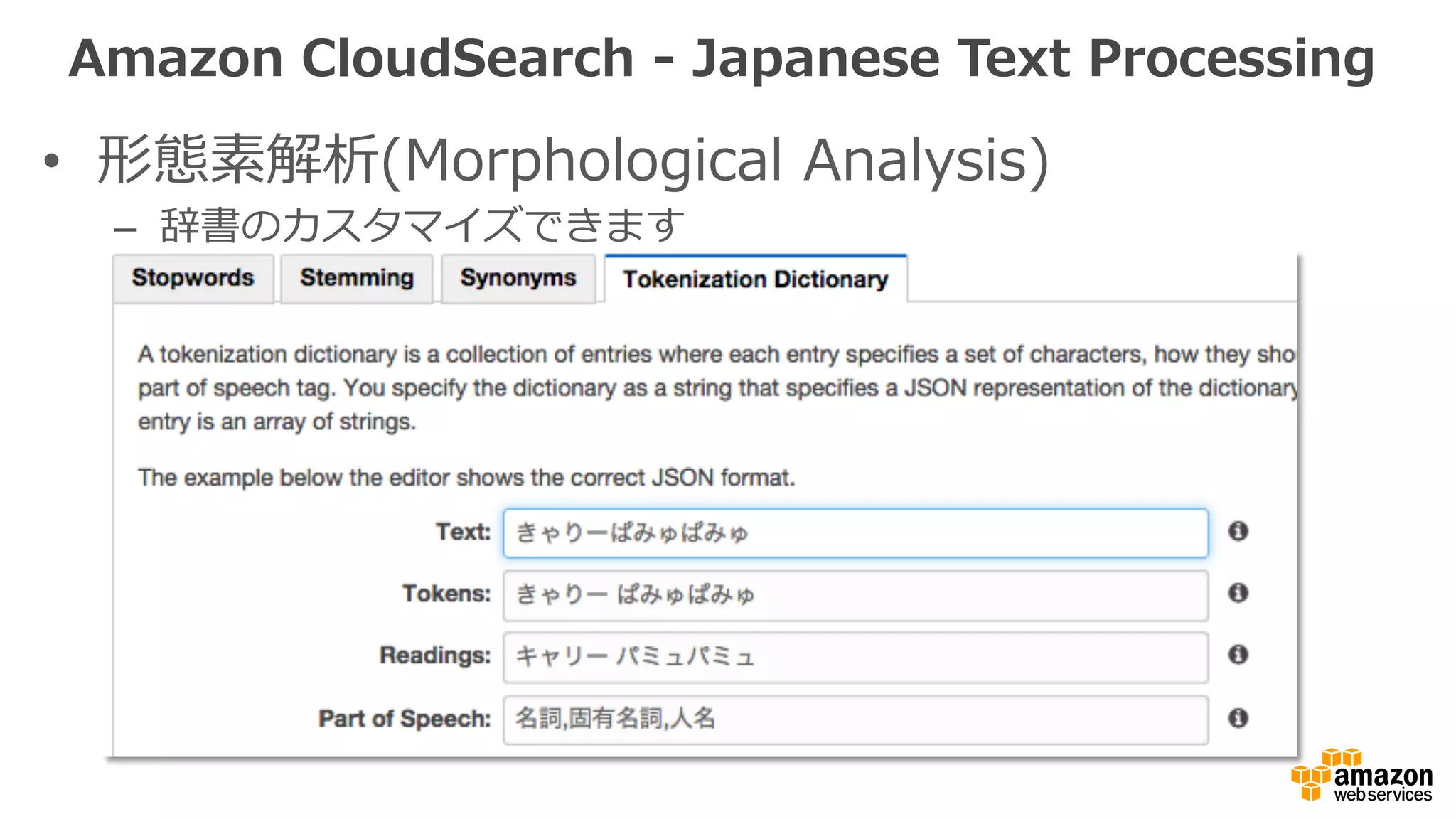
![• 形態素解析(Morphological Analysis)
– 辞書のカスタマイズできます: AWS CLI/SDKからも操作可能
{
"AnalysisSchemeName": "jascheme",
"AnalysisSchemeLanguage": "ja",
"AnalysisOptions": {
"JapaneseTokenizationDictionary": "[
[“きゃりーぱみゅぱみゅ”,“きゃりー ぱみゅぱみゅ”,“キャリー パミュパミュ","名
詞,固有名詞,⼈人名”]
]"
}
}
$ aws cloudsearch define-‐‑‒analysis-‐‑‒scheme -‐‑‒-‐‑‒region us-‐‑‒east-‐‑‒1 -‐‑‒-‐‑‒domain-‐‑‒name mydomain
-‐‑‒-‐‑‒analysis-‐‑‒scheme file://jascheme.txt
Amazon CloudSearch -‐‑‒ Japanese Text Processing](https://image.slidesharecdn.com/awssearchservices-151211024211/75/AWS-Search-Services-14-2048.jpg)






















![[AWS Start-up ゼミ] よくある課題を一気に解説!〜御社の技術レベルがアップする 2017 夏期講習〜](https://cdn.slidesharecdn.com/ss_thumbnails/awsstartupzemi-2017summer-170816032526-thumbnail.jpg?width=640&height=640&fit=bounds)












![AWS 初心者向けWebinar AWS上にWebサーバシステムを作ってみましょう~まずは仮想サーバーから[演習つき]](https://cdn.slidesharecdn.com/ss_thumbnails/20150623ec2handson-150624041700-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
















































![[要約] Building a Real-Time Bidding Platform on AWS #AWSAdTechJP](https://cdn.slidesharecdn.com/ss_thumbnails/2016rtbwhitepaper-160310091325-thumbnail.jpg?width=640&height=640&fit=bounds)




















